


还在为海量 LLM 如何高效选型而头疼?还在苦恼资源有限无法穷尽所有微调可能?来自弗吉尼亚理工大学的最新研究,提出 LensLLM 框架,不仅能精准预测大模型微调性能,更大幅降低计算成本,让 LLM 选型不再是“开盲盒”!

前言:LLM狂飙突进,选型为何成了“瓶颈”?
大语言模型(LLMs)的浪潮席卷全球,从机器翻译、文本摘要到智能问答和对话系统,它们正以惊人的速度重塑着自然语言处理的边界。
然而,当开源 LLM 如雨后春笋般涌现,例如 LLaMA、Falcon、Mistral 到 DeepSeek,如何在这片模型“森林”中找到最适合特定下游任务的那一棵“参天大树”,却成了摆在研究者和开发者面前的巨大挑战。
传统的模型选择方法,面对 LLM 的庞大规模和复杂性,往往耗费巨大计算资源却收效甚微,且泛化能力不足,如同在黑暗中摸索,充满不确定性。

LENSLLM理论突破:PAC-贝叶斯泛化界限揭示微调深层动力学
为了打破这一“瓶颈”,来自弗吉尼亚理工大学的研究团队,通过深邃的理论洞察,提出了一项突破性的理论框架——LensLLM。
他们的研究基于全新的 PAC-贝叶斯泛化界限(PAC-Bayesian Generalization Bound),首次从理论上揭示了 LLM 微调过程中测试损失(TestLoss)随训练数据量(TrainSize)变化的独特“相变”动力学。

论文名称:
LensLLM: Unveiling Fine-Tuning Dynamics for LLM Selection
论文作者:
Xinyue Zeng, Haohui Wang, Junhong Lin, Jun Wu, Tyler Cody, Dawei Zhou
所属机构:
Department of Computer Science, Virginia Tech, Blacksburg, VA, USA等
收录会议:
ICML 2025
开源地址:
https://github.com/Susan571/LENSLLM
论文链接:
https://arxiv.org/abs/2505.03793
联系方式:
xyzeng@vt.edu, zhoud@vt.edu

具体来说,这项 PAC-贝叶斯泛化界限(定理 2)表明,LLM 的测试损失 可以被表示为:
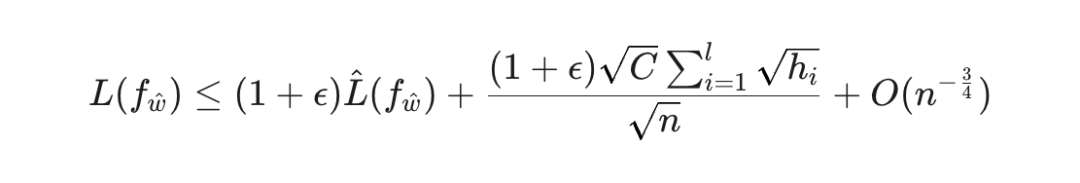
其中,n 是训练样本量, 与模型参数的 Hessian 矩阵(衡量损失函数曲率和参数敏感性)紧密相关。
在此基础上,研究团队进一步推导出推论 1,将泛化界限简化为:
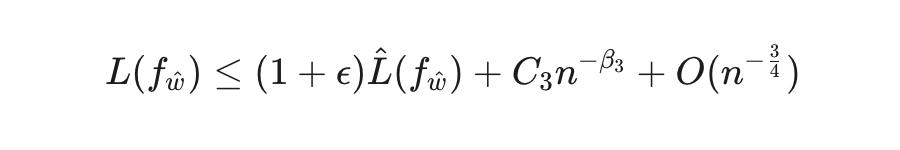
其中 和 都是模型/任务相关的参数。这一理论框架揭示了 LLM 微调性能的“双相演进”:
-
预幂律相(Pre-powerPhase):在数据量 n 较少时,模型行为主要受初始化和早期训练动态影响,此时泛化误差由 项主导。这一阶段的特点是 Hessian 值较高,参数敏感性显著,因此性能提升相对缓慢,需要谨慎调优和大量数据才能实现可靠的适应。
-
幂律相(PowerPhase):随着训练数据量 n 的增加,误差缩放规律过渡到由 项主导,成为主要影响因素。一旦模型进入这个阶段,Hessian 值降低,模型稳定性增强,使得更激进的参数更新和更高的数据效率成为可能。
这种从 到 的主导常数因子变化,正是预幂律相到幂律相转换的关键标志,反映了 Hessian 值和参数敏感性的变化。
LensLLM 的理论分析不仅为理解这一复杂行为提供了首个第一性原理层面的解释,更是精确预测了何时的数据投入将带来性能的“质变”,并指导我们在进入幂律相后,如何权衡数据收集成本与预期性能增益。这一理论基础为高效的模型选择提供了前所未有的“透视能力”。
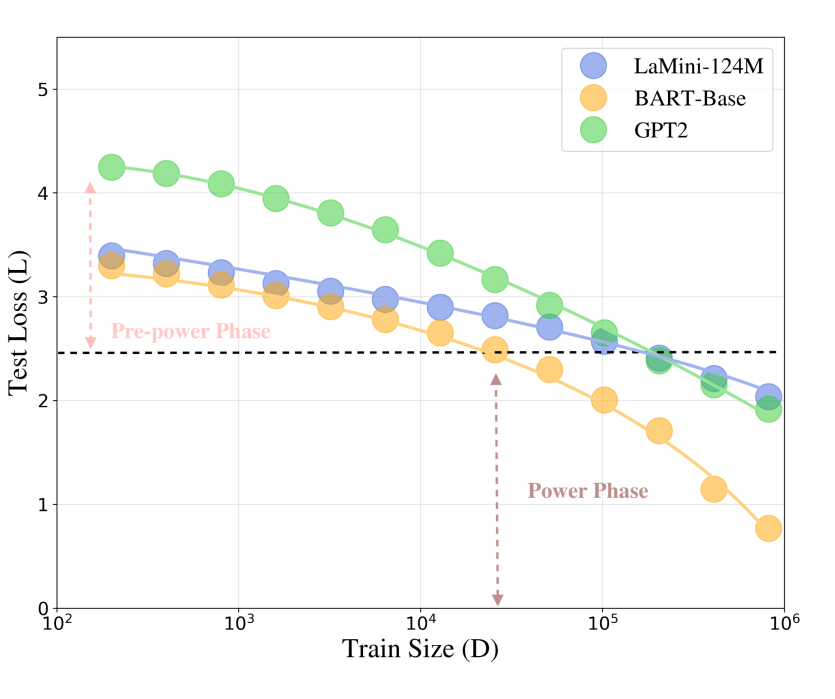
▲ 图1:LLM 微调过程中测试损失 L 随训练数据量 D 变化的相变现象。低数据量阶段为预幂律相,高数据量阶段为幂律相,两者之间存在明显的转折点。

LENSLLM:NTK驱动的“透视眼”,精准预测性能
基于对微调相变机制的深刻理论理解,研究团队重磅推出了 LensLLM 框架——一个革命性的 NTK(NeuralTangentKernel)增强型修正缩放模型。LensLLM 巧妙地将 NTK 引入,以更精准地捕捉 transformer 架构在微调过程中的复杂动态,有效表征了预训练数据对性能的影响。
值得强调的是,LensLLM 的理论严谨性是其核心优势之一。它不仅提供了经验观察的理论解释,更在数学上建立了模型性能与数据量之间的精确关联,为 LLM 选型提供了坚实的理论支撑,而非仅仅依赖于经验拟合。
核心优势一:卓越的曲线拟合与预测能力
LensLLM 在曲线拟合和测试损失预测方面展现出令人印象深刻的准确性。在 FLAN、Wikitext 和 Gigaword 三大基准数据集上,LensLLM(蓝色方块)的表现始终优于基准模型(Rectified Scaling Law)(红色三角形),能更平滑、更准确地追踪实际测试损失曲线,且误差带(RMSE Band)更小,表明其预测结果更为稳定。
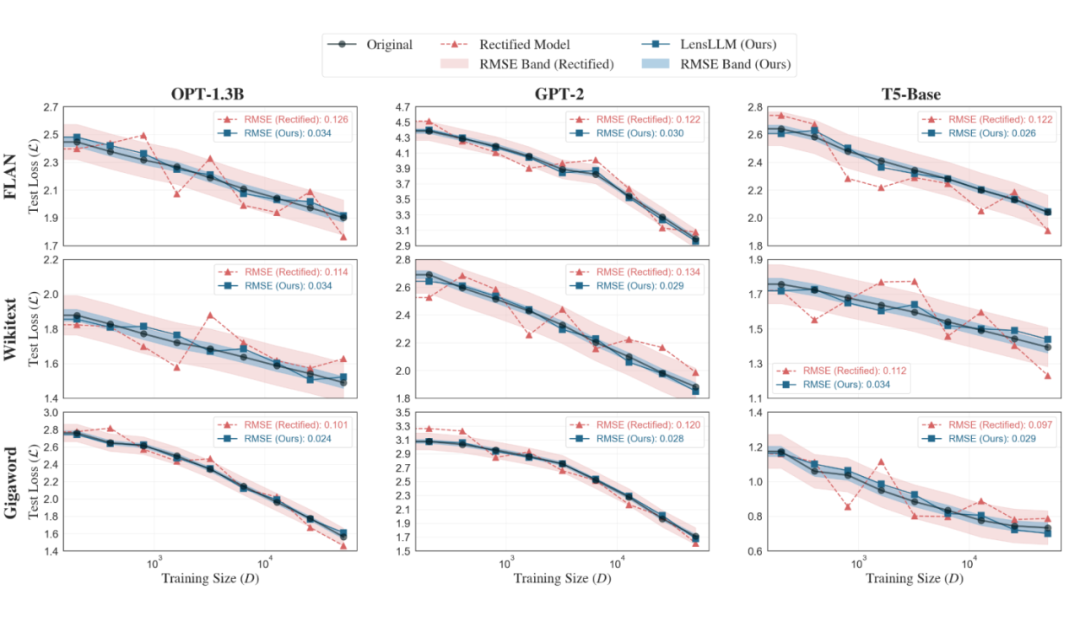
▲ 图2:LensLLM(蓝色方块)在 FLAN、Wikitext 和 Gigaword 数据集上对 OPT-1.3b、GPT-2 和 T5-base 模型性能的曲线拟合效果。LensLLM 的 RMSE值显著低于 Rectified Scaling Law(红色三角形),误差带更窄,表明其预测更稳定准确。
此外,通过 RMSE 对比预测损失和实际损失,LensLLM 的误差显著更低,例如在 Wikitext 数据集上,LensLLM 的误差通常是 Rectified Scaling Law 的 5 倍之小(例如,OPT-6.7B:0.026 vs 0.132;mT5-Large:0.028 vs 0.144)。
在 FLAN 数据集上,LensLLM 保持低 RMSE(0.022-0.035),而 Rectified Scaling Law 的 RMSE 较高(0.087-0.15)。
在 Gigaword 数据集上,LensLLM 的性能始终低于0.036,而 Rectified Scaling Law 的 RMSE 在 0.094-0.146 之间波动。
这些结果在三个数据集和十四种架构上证实了 LensLLM 在预测训练动态方面的卓越准确性。
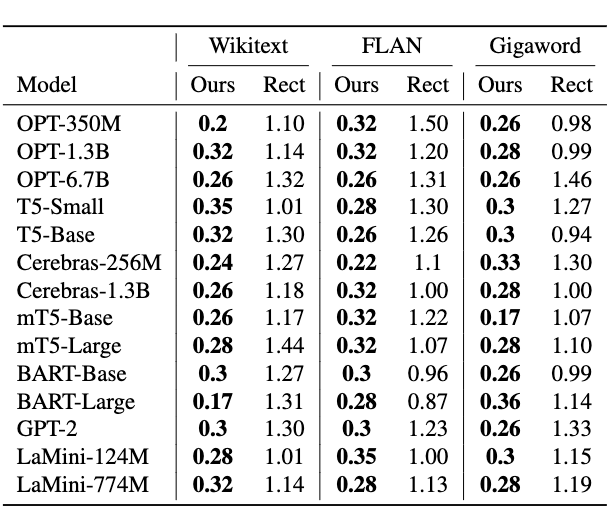
▲ 表格2:预测测试损失与实际测试损失方面的均方根误差(RMSE)对比(×10-1)
核心优势二:更准、更快地选出“最优解”
LensLLM 在 LLM 选型任务中也展现了压倒性的优势。在 FLAN、Wikitext 和 Gigaword 数据集上,LensLLM 在 Pearson 相关系数(PearCorr)和相对准确率(RelAcc)两项关键指标上均取得最高分。
例如,在 Gigaword 数据集上,LensLLM 实现了高达 85.8% 的 PearCorr 和 91.1% 的 RelAcc。这意味着 LensLLM 能够更有效地对模型进行排名,并选出性能接近最优的模型。

▲ 图3:LensLLM 在 FLAN、Wikitext 和 Gigaword 数据集上的 Pearson 相关系数和相对准确率表现。LensLLM(最右侧深蓝色条形)在所有数据集上均显著优于 Rectified Scaling Law、NLPmetrics、SubTuning、ZeroShot 和 ModelSize 等基线方法,展现了其在模型选型中的卓越能力。
更令人振奋的是,LensLLM 在保持高精度的同时,极大地降低了计算成本。与 FullTuning 相比,LensLLM 能够将计算成本降低高达 88.5%!
LensLLM 在各项任务中的计算成本分别为 0.48、0.59 和 0.97×1021 FLOPs,这大大优于 SubTuning 和 FullTuning。
这得益于其创新的渐进式采样策略,使得 LensLLM 在更低的 FLOPs 消耗下,就能达到卓越的选型性能,让 LLM 选型真正实现高效与准确的平衡。
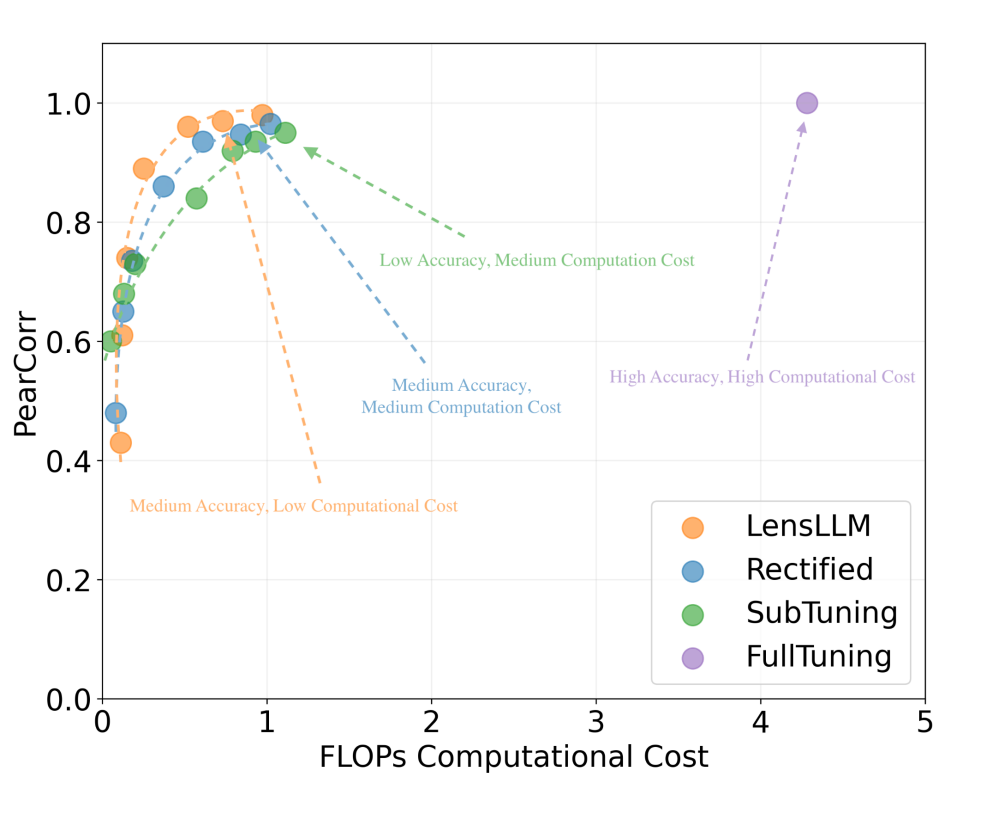
▲ 图4:LLM 选型性能与计算成本的 Pareto-最优曲线。LensLLM(橙色点)在显著降低 FLOPs(计算成本)的同时,保持了高水平的 Pearson 相关系数,相较于Rectified(蓝色点)、SubTuning(绿色点)和 FullTuning(紫色点)展现出更优的效率。

未来展望:让LLM选型走向更广阔天地
这项突破性的研究为 LLM 的开发和应用提供了强大的新工具。它将帮助研究者和工程师们更自信、更高效地探索大模型的潜力,让 LLM 的普及和落地更进一步。
LensLLM 的成功,不仅为 LLM 选型建立了新的基准,更开启了未来的无限可能。研究团队指出,未来有望将 LensLLM 扩展到多任务场景,探索其对模型架构设计的影响,并将其应用于新兴模型架构,例如 MoE(Mixture of Experts)模型。
潜在应用场景:
-
资源受限环境下的模型部署:LensLLM 的高效性使其特别适用于边缘设备或计算资源有限的场景,能够快速筛选出兼顾性能与效率的最佳模型。
-
A/B 测试与模型迭代:在实际产品开发中,LensLLM 可以大大加速新模型的测试与部署周期,降低试错成本。
-
个性化 LLM 定制:用户可以根据自身数据特点和任务需求,快速找到最匹配的 LLM,实现模型性能最大化。
面对 LLM 的澎湃发展,LensLLM 犹如一座灯塔,照亮了高效、精准模型选择的道路。它将终结 LLM 微调的“玄学”,引领我们进入一个更加“智能”和“高效”的 LLM 应用新纪元。
(文:PaperWeekly)