

在人工智能领域,大语言模型(LLMs)的发展日新月异,其在长文本推理任务中的表现尤为引人注目。然而,传统长推理范式面临着计算复杂度高、上下文窗口限制等问题,严重制约了模型的推理深度和效率。为了解决这一难题,浙江大学联合北京大学推出了创新的无限深度推理范式——InftyThink。
一、项目概述
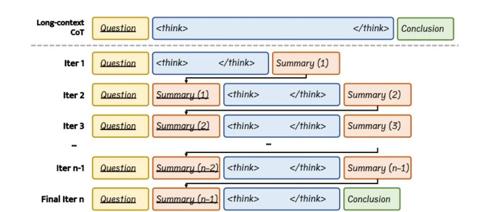
InftyThink是一种创新的大模型推理范式,由浙江大学和北京大学联合推出,旨在突破传统模型在长推理任务中的局限性。它通过分段迭代的方式,将复杂的推理过程分解为多个短片段,并在每个片段后生成中间总结,实现分块式思考。这种“锯齿形”内存模式显著降低了计算复杂度,使模型能够处理理论上无限长度的推理链,同时保持推理的准确性和效率。
二、技术原理
(一)迭代式推理与阶段性总结
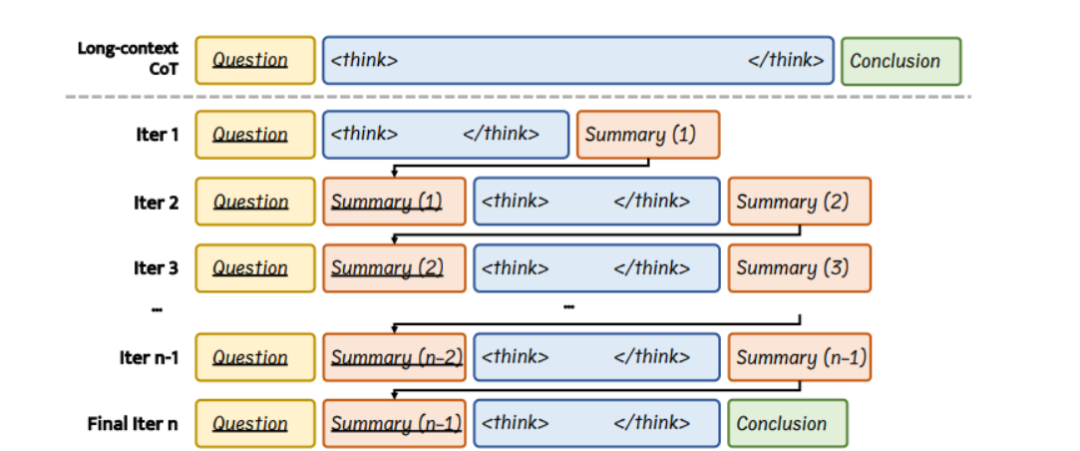
InftyThink的核心思想是将传统的单一连续推理过程拆分为多个短推理片段,并在每个片段后生成一段精炼的总结。这些总结作为下一阶段推理的上下文输入,模拟了人类逐步归纳总结的认知过程。通过这种方式,模型能够在保持上下文连贯的同时进行无限深度的推理,解决了传统长推理在上下文长度和计算复杂度上的限制。
(二)固定的计算开销与上下文窗口
InftyThink采用“锯齿式”内存使用模式,在每轮短推理后清空前轮上下文,仅保留总结。这种模式显著降低了推理时的计算复杂度,与传统推理范式相比,InftyThink在推理深度与计算效率之间达成了更优的平衡。
(三)与原始架构解耦、训练范式兼容性强
InftyThink不依赖于模型结构上的调整,而是通过重构训练数据为多轮推理格式来实现其范式。它能够与现有的预训练模型、微调、强化学习流程无缝结合,具备良好的工程可落地性。
(四)开发数据重构技术
InftyThink开发了一种将现有长文本推理数据集转换为迭代格式的方法。例如,将OpenR1-Math数据集转换为33.3万条训练实例,方便在该范式下训练模型。
三、主要功能
(一)突破上下文窗口限制
InftyThink通过迭代推理和中间总结,能够处理理论上无限长度的推理链,突破了传统大模型上下文窗口的限制。
(二)降低计算成本
相比传统的长推理方法,InftyThink在推理过程中减少了对长序列的直接处理,显著降低了计算成本。
(三)提升推理性能
在一些复杂的推理任务中,InftyThink能够更好地处理长序列信息,提升推理的准确性和生成吞吐量。
四、性能表现
(一)实验结果
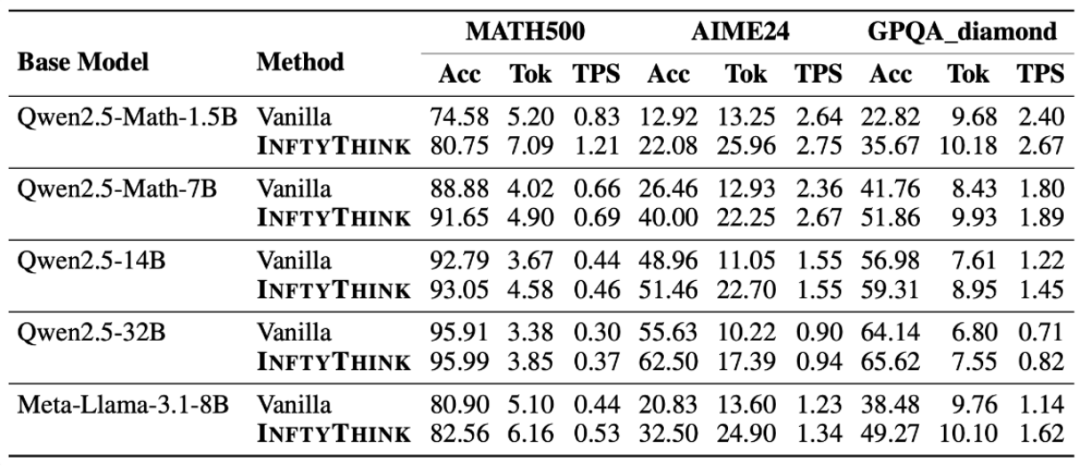
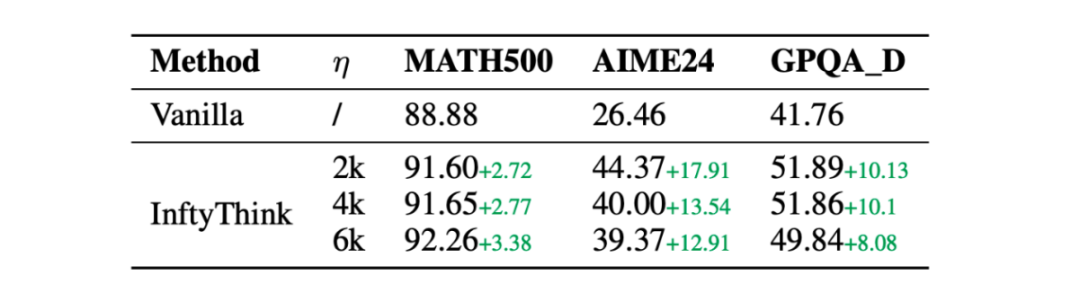
InftyThink在多个模型架构上的实验结果表明,其在保持推理深度的同时,显著降低了计算复杂度。例如,Qwen2.5-Math-7B在MATH500、AIME24和GPQA_diamond基准测试中分别实现了3%、13%和10%的性能提升。此外,InftyThink还通过迭代推理的方式,使短上下文模型具备了长上下文推理能力,进一步拓展了模型的应用范围。
(二)推理迭代轮次性能
InftyThink的迭代推理机制使其能够在多次迭代中逐步提升推理性能。实验表明,随着迭代轮次的增加,模型的推理准确率不断提高,最终在多次迭代后达到较高的准确率水平。这种逐步提升的推理能力,使得InftyThink在处理复杂推理任务时更具优势。
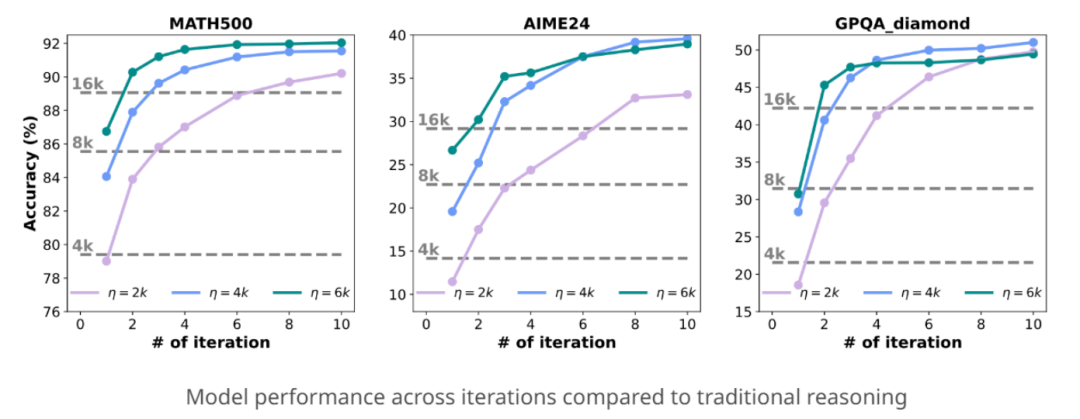
(三)不同上下文窗口大小的影响
InftyThink通过调整上下文窗口大小参数η,可以在推理深度和计算效率之间进行灵活权衡。实验结果表明,较大的η值可以使模型在每次迭代中处理更多的内容,从而减少迭代次数;而较小的η值则可以提高推理效率,但可能需要更多的迭代次数来达到相同的推理深度。通过合理选择η值,InftyThink能够在不同的任务需求下实现最优的推理性能。
五、应用场景
(一)数学问题求解
InftyThink能够处理复杂的数学问题,通过分段迭代推理和中间总结,逐步解决长链条的数学问题,适用于数学竞赛、数学建模等领域。
(二)逻辑推理
在需要处理长序列逻辑推理的任务中,InftyThink可以有效提升推理的准确性和效率,适用于法律推理、科学实验设计等场景。
(三)代码生成
InftyThink可以逐步生成复杂的代码逻辑,保持代码的连贯性和正确性,适用于软件开发、自动化编程等领域。
(四)智能辅导
在智能辅导系统中,InftyThink能够根据学生的问题逐步提供详细的解答和解释,帮助学生更好地理解和掌握知识点,适用于在线教育、个性化学习等场景。
(五)药物研发
在药物研发过程中,InftyThink可以用于预测药物靶标3D结构及结合亲和力,加速研发进程,适用于生物医学研究、新药开发等领域。
六、快速使用
(一)环境准备
在开始使用InftyThink之前,需要确保已安装Python环境,并具备基础的深度学习框架支持。此外,还需要安装项目所需的依赖库,如transformers、torch等。
(二)数据预处理
InftyThink提供了一套完整的数据预处理流程,用于将现有的长文本推理数据集转换为迭代格式。具体步骤如下:
1. 思考过程分割:运行`segmentation.py`脚本,将原始推理过程分割为多个片段。例如:
cd data_preprocesspython3 segmentation.py --dataset_name open-r1/OpenR1-Math-220k \--tokenizer Qwen/Qwen2.5-Math-7B \--eta 4096
2. 生成总结并形成InftyThink风格数据:运行`generate_data.py`脚本,为每个推理片段生成总结,并将其与原始片段组合,形成InftyThink风格的训练数据。例如:
cd data_preprocesspython3 generate_data.py --model meta-llama/Llama-3.3-70B-Instruct
(三)模型训练
使用InftyThink风格的数据对模型进行训练。可以基于现有的预训练模型进行微调,以实现更好的推理性能。训练时,需要指定训练数据路径、模型架构等参数。
(四)推理实践
完成训练后,可以使用InftyThink风格的模型进行推理。InftyThink提供了一个推理示例脚本,方便用户快速上手。例如:
cd inferencepython3 infer_single.py
运行该脚本后,模型将根据输入问题逐步进行迭代推理,并生成最终的推理结果。
七、结语
InftyThink作为一种创新的无限深度推理范式,为大语言模型在长推理任务中的应用提供了新的思路和方法。它通过分段迭代推理和中间总结的方式,突破了传统模型的上下文窗口限制,显著降低了计算成本,同时提升了推理性能。InftyThink在数学问题求解、逻辑推理、代码生成等多个领域展现出广阔的应用前景。未来,随着技术的不断发展和完善,InftyThink有望在更多领域发挥重要作用,推动人工智能技术的进一步发展。
八、项目资料
官方网站:https://zju-real.github.io/InftyThink/
开源仓库:https://github.com/ZJU-REAL/InftyThink
技术论文:https://arxiv.org/pdf/2503.06692
(文:小兵的AI视界)