

SkyReels-Audio 是 Skywork AI 团队开发的一款创新框架,能够将静态图像或视频与语音输入相结合,生成高度逼真且唇形同步的说话人像视频。该框架基于预训练的视频扩散变换器构建,支持无限长度的视频生成和编辑,提供多模态控制能力。通过混合课程学习策略和双向潜在融合技术,该模型在身份一致性、面部表情自然度和唇形同步精度上取得了显著进展,为数字内容创作、教育和娱乐领域带来了革命性的可能性。

研究背景与概述
2025 年 6 月 1 日,Skywork AI 团队发布了最新研究论文《SkyReels-Audio: Omni Audio-Conditioned Talking Portraits in Video Diffusion Transformers》,在计算机视觉和人机交互领域引起了广泛关注。这项研究将在项目官网 SkyReels-Audio.github.io 公布详细信息和演示视频。

想象一下,仅需一张照片和一段语音,就能让照片中的人“活”起来,自然地说话、表情生动,甚至能做出与语音内容相匹配的肢体动作。这正是 SkyReels-Audio 实现的突破性技术。在数字内容创作领域,生成逼真的人物视频一直极具挑战性,尤其是要实现音频的精确同步、保持身份一致性,并展现自然的面部表情和身体动态。传统方法通常需要专业设备和复杂的后期处理,效果往往不尽如人意。SkyReels-Audio 的出现正是为了解决这些问题,它能够根据输入的图像、视频或文本,结合音频信息,生成高度逼真、时间连贯的人像视频。
技术原理与创新
SkyReels-Audio 的核心是基于预训练的视频扩散变换器构建的统一框架。3D VAE(变分自编码器)负责提取视觉特征,而 Whisper 模型处理输入的语音信号,进行重采样和特征编码。这些音频表示经过 Whisper 编码器后,转化为离散的标记嵌入,然后通过专门的交叉注意力层注入到视频 DiT(扩散变换器)中,从而调制视频生成过程。
为了改善音频和视觉模态之间的对齐,研究团队采用了 RoPE(旋转位置编码)技术,有效捕捉距离感知关系,并能泛化到可变序列长度。这种技术增强了模态内部的连贯性和跨模态的对应关系,从而实现更准确的唇部同步和生成内容的语义一致性。
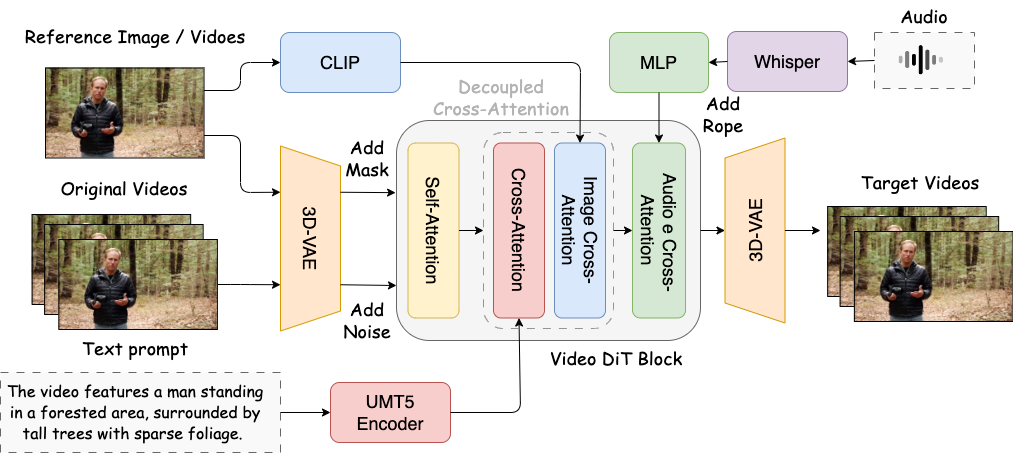
研究团队还提出了混合学习策略,发现联合训练策略能够更有效地处理图像动画和视频编辑任务。实验表明,采用联合训练策略即使使用 T2V 模型作为基础模型,也能获得令人满意的图像动画结果。相比之下,单独训练图像动画任务往往需要更长的收敛时间,有时甚至无法产生正确结果。
数据处理与模型训练
为了训练高质量的模型,SkyReels 团队构建了一条严格的数据处理流水线。他们从公共数据集和自行收集的来源中收集了 10,000 小时的视频数据,经过多阶段处理,最终获得 1,000 小时用于训练的高质量数据。数据预处理流程包括:收集大规模视频数据集,基于内容连贯性将其分割为短片段;使用视频字幕模型 SkyCaptioner-V1 为每个片段生成描述性注释;使用 YOLO-World 和 InsightFace 进行身体和面部检测;使用 DWpose 提取姿势相关特征;应用 Whisper 识别所讲语言。这种多阶段预处理确保了训练数据的质量。
模型推理与优化
在推理阶段,SkyReels-Audio 引入了几项关键优化,使模型不仅能产生高质量结果,还能高效运行。首先是音频引导条件采样机制(Audio CFG),通过增强与驱动音频信号的同步来改进生成效果,动态平衡条件影响,提高逼真度和音频同步人像生成的稳健性。其次是通过双向潜在融合(BLF)实现无限视频生成,通过双向加权融合视频潜在表示,减少错误累积导致的图像质量下降。第三是混合推理策略,模型在推理过程中同时支持图像和视频输入,通过在早期去噪步骤使用完整视频输入以保持结构一致性,后续切换到图像输入以细化唇部同步细节。最后是模型加速,通过 Teacache 和统一序列并行化(USP)优化推理过程,显著提升生成速度。
实验结果与性能评估
研究团队通过定量和定性分析全面评估了 SkyReels-Audio 的性能,结果令人印象深刻。在视觉保真度、运动真实性和唇部同步精度方面,SkyReels-Audio 始终优于基线模型,达到接近闭源模型的性能。在内部数据集上,SkyReels-Audio 在 Sync-C 和 Sync-D 指标(衡量音视频同步)上分别达到 6.75 和 8.32,明显优于多数基线模型。同时,在图像质量评估(IQA)和美学评分(ASE)上也表现出色,分别为 4.42 和 2.91。主观评估中,20 名参与者对音视频一致性和视觉质量进行评分,SkyReels-Audio 在两个维度上均优于基线系统。消融研究中,团队分析了音频 CFG 和音频 RoPE 的影响,结果显示这些技术显著提升了音视频同步和视觉质量。
应用场景与未来展望
SkyReels-Audio 为数字内容创作、教育和娱乐等领域带来了革命性的可能性。在数字内容创作方面,内容创作者可以轻松生成高质量的人物讲解视频,无需专业设备和场地。在教育领域,SkyReels-Audio 可以将历史人物的静态照片“复活”,创造沉浸式学习体验。在娱乐和媒体方面,该技术可用于电影制作中的对白后期处理,或创建与观众互动的虚拟角色。随着技术的发展,伦理和隐私问题也日益凸显。未来研究方向可能包括提升长视频生成的稳定性、增强情感表达的多样性、支持更复杂的人物互动场景,以及优化推理速度以实现实时应用。
总结与反思
SkyReels-Audio 代表了音频驱动人像视频生成领域的一个重要突破。通过结合预训练的视频扩散变换器、创新的双向潜在融合策略以及混合学习范式,该模型能够生成高度逼真、时间连贯的人像视频,同时保持强大的身份一致性和自然的面部与身体动态。这项技术不仅具有技术创新性,还为普通用户提供了强大而易用的视频创作工具,降低了数字内容创作的门槛。然而,我们也需要思考如何在技术创新与伦理责任之间取得平衡,维护信息的真实性和可信度。这些问题需要技术开发者、政策制定者和社会各界共同探讨。
(文:AI音频时代)