


随着人工智能技术的飞速发展,AI在音乐创作领域的应用逐渐崭露头角。腾讯AI Lab开源的SongGeneration项目,为音乐生成领域带来了新的突破和可能性,它不仅能够提升音乐创作的效率,还能激发创作者的灵感,为音乐产业注入新的活力。

一、项目概述
SongGeneration是腾讯AI Lab推出的一款基于大模型的音乐生成工具,它通过先进的技术架构和算法,实现了高质量的音乐生成。该项目支持文本控制、多轨合成、风格跟随等功能,能够满足创作者在不同场景下的音乐创作需求。SongGeneration在多个维度上的表现优于多数开源模型,部分指标甚至媲美商业闭源模型,广泛应用于短视频配乐、游戏音效、虚拟人演出、商业广告及个人音乐创作等领域,推动了AI音乐创作从“辅助工具”迈向“智能共创”的新阶段。
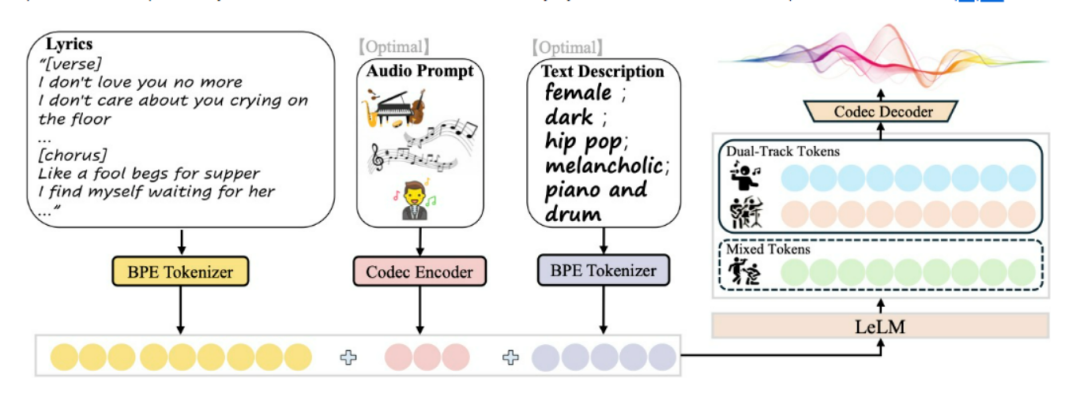
二、技术原理
(一)LeLM(Language Model)
LeLM是SongGeneration的核心组件之一,它能够并行预测混合标记(Mixed Tokens)和双轨标记(Dual-Track Tokens)。混合标记代表人声和伴奏的组合音频,用于捕捉歌曲的整体结构和节奏,确保人声与伴奏的和谐;双轨标记则分别编码人声和伴奏,用于生成高质量的音频细节。LeLM通过并行预测这两种标记,避免了不同标记类型之间的干扰,提高了生成质量和效率。
(二)音乐编解码器(Music Codec)
音乐编解码器负责将音乐音频提取为混合标记和双轨标记,并将双轨标记重建为高保真的音乐音频。编码器将音乐音频转化为离散的标记序列,而解码器则将这些标记重建为高质量的音频信号,确保生成的歌曲具有出色的音质表现。
(三)多偏好对齐(Multi-Preference Alignment)
SongGeneration采用基于直接偏好优化(DPO)的多偏好对齐方法,通过半自动数据构建和DPO后训练,处理多样化的人类偏好。这种方法能够提升模型在音乐性、指令遵循和人声与伴奏和谐方面的表现,使生成的音乐更符合人类的审美和创作需求。
(四)三阶段训练范式
1. 预训练(Pre-training):在大规模音乐数据上进行预训练,对齐不同输入模态和混合标记,为后续的训练奠定基础。
2. 模块扩展训练(Modular Extension Training):进一步训练AR解码器,建模双轨标记,提升音质和音乐性,同时保留预训练阶段的知识。
3. 多偏好对齐(Multi-Preference Alignment):基于DPO后训练,优化模型在多维度偏好上的表现,使模型能够更好地遵循指令和生成高质量的音乐。
三、主要功能
(一)文本控制
用户可以通过输入关键词文本,如“开心 流行”,快速生成对应风格和情绪的完整音乐作品。这种功能使得音乐创作更加便捷和直观,创作者可以根据自己的创意和需求,轻松生成符合主题的音乐。
(二)风格跟随
用户可以上传10秒以上的参考音频,SongGeneration能够生成风格一致的全长新曲,涵盖多种流派。这一功能为创作者提供了强大的风格迁移能力,能够快速探索不同风格的音乐创作。
(三)多轨生成
SongGeneration能够自动生成分离的人声与伴奏轨道,保证旋律、结构、节奏与配器的高度匹配。这种多轨生成能力不仅提高了音乐的制作质量,还为后续的音乐编辑和混音提供了更大的灵活性。
(四)音色跟随
基于参考音频的音色跟随,SongGeneration能够实现“音色克隆”级别的人声表现,自然且有情感。这一功能对于需要特定音色的音乐创作场景非常有价值,能够帮助创作者实现独特的音色效果。
四、应用场景
(一)音乐创作
SongGeneration为音乐人和制作人提供了高质量歌曲草稿,节省了创作时间,使创作者能够更专注于核心创作部分,激发更多创意。
(二)娱乐产业
在影视、游戏、广告等娱乐领域,SongGeneration能够快速生成契合需求的配乐,增强作品的沉浸感与吸引力,丰富音乐内容。
(三)教育领域
作为音乐教育工具,SongGeneration可以帮助学生理解音乐基础知识,激发创造力,辅助在线课程提供示例歌曲,提升教学效果。
(四)广告和营销
SongGeneration能够为广告和品牌生成贴合主题的音乐,提升广告的吸引力和品牌认同感,助力品牌营销。
(五)个人娱乐
普通用户可以使用SongGeneration创作个性化歌曲,表达情感,分享到社交平台,增添娱乐互动的乐趣。
五、快速使用
(一)环境准备
1. 从头开始安装
使用`requirements.txt`文件安装必要的依赖项:
pip install -r requirements.txt --no-deps安装flash attention:
pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.6.3/flash_attn-2.6.3+cu118torch2.2cxx11abiFALSE-cp310-cp310-linux_x86_64.whl2. 使用Docker部署
拉取Docker镜像并运行:
docker pull juhayna/song-generation-levo:hf0613docker run -it --gpus all --network=host juhayna/song-generation-levo:hf0613 /bin/bash
(二)模型下载与配置
从Hugging Face下载所需的模型文件(`ckpt`和`yaml`文件),并将其保存到项目的根目录或指定的检查点目录中。
(三)输入文件准备
– 创建一个JSON Lines格式的输入文件(`.jsonl`),每行代表一个音乐生成请求。输入文件应包含以下字段:
– `idx`:输出歌曲的唯一标识符,将用作生成音频文件的名称。
– `gt_lyric`:用于生成的歌词,必须遵循`[Structure] Text`的格式,其中`Structure`定义音乐部分(例如`[Verse]`、`[Chorus]`)。
– `descriptions`(可选):自定义文本提示,用于指导模型生成,可以包括性别、音色、流派、情感、乐器和BPM等属性。
– `prompt_audio_path`(可选):10秒参考音频文件的路径,如果提供,模型将生成类似风格的新歌曲。
– `auto_prompt_audio_type`(可选):如果未提供`prompt_audio_path`,模型将根据给定的风格自动从预定义库中选择参考音频。
(四)运行生成脚本
使用以下命令运行生成脚本:
sh generate.sh ckpt_path lyrics.jsonl output_path如果GPU内存小于30GB或遇到内存不足错误,使用低内存模式:
sh generate_lowmem.sh ckpt_path lyrics.jsonl output_path(五)示例输入与输出
示例输入文件`lyrics.jsonl`:
{"idx": "song1", "gt_lyric": "[intro-short] ; [verse] These faded memories of us. I can't erase the tears you cried before. Unchained this heart to find its way. My peace won't beg you to stay ; [chorus] Like a fool begs for supper. I find myself waiting for her. Only to find the broken pieces of my heart. That was needed for my soul to love again", "descriptions": "female, dark, pop, sad, piano and drums, the bpm is 125"}输出目录`output_path`将包含生成的音频文件和JSON Lines输出文件。
六、结语
SongGeneration作为腾讯AI Lab开源的音乐生成大模型,凭借其强大的功能和先进的技术原理,为音乐创作领域带来了新的变革。它不仅能够满足专业音乐人和制作人的创作需求,还能为普通用户提供个性化的音乐创作体验。随着技术的不断发展和优化,SongGeneration有望在更多领域发挥更大的作用,为音乐产业的发展注入新的动力。
七、项目地址
技术论文:https://arxiv.org/pdf/2506.07520
GitHub仓库:https://github.com/tencent-ailab/SongGeneration
Hugging Face模型库:https://huggingface.co/tencent/SongGeneration
在线体验Demo:https://huggingface.co/spaces/tencent/SongGeneration
(文:小兵的AI视界)