

本文使用Dify v1.4.0版本,主要解析了commands.py中的migrate_annotation_vector_database()函数的执行逻辑。源码位置:dify\api\commands.py
一.Dify中的标注
在QA过程中,对于某些Q和A问答对进行标注,在后续QA过程中,如果新的Q和标注的Q满足Score阈值,那么直接返回A即可。标注回复流程,如下所示:
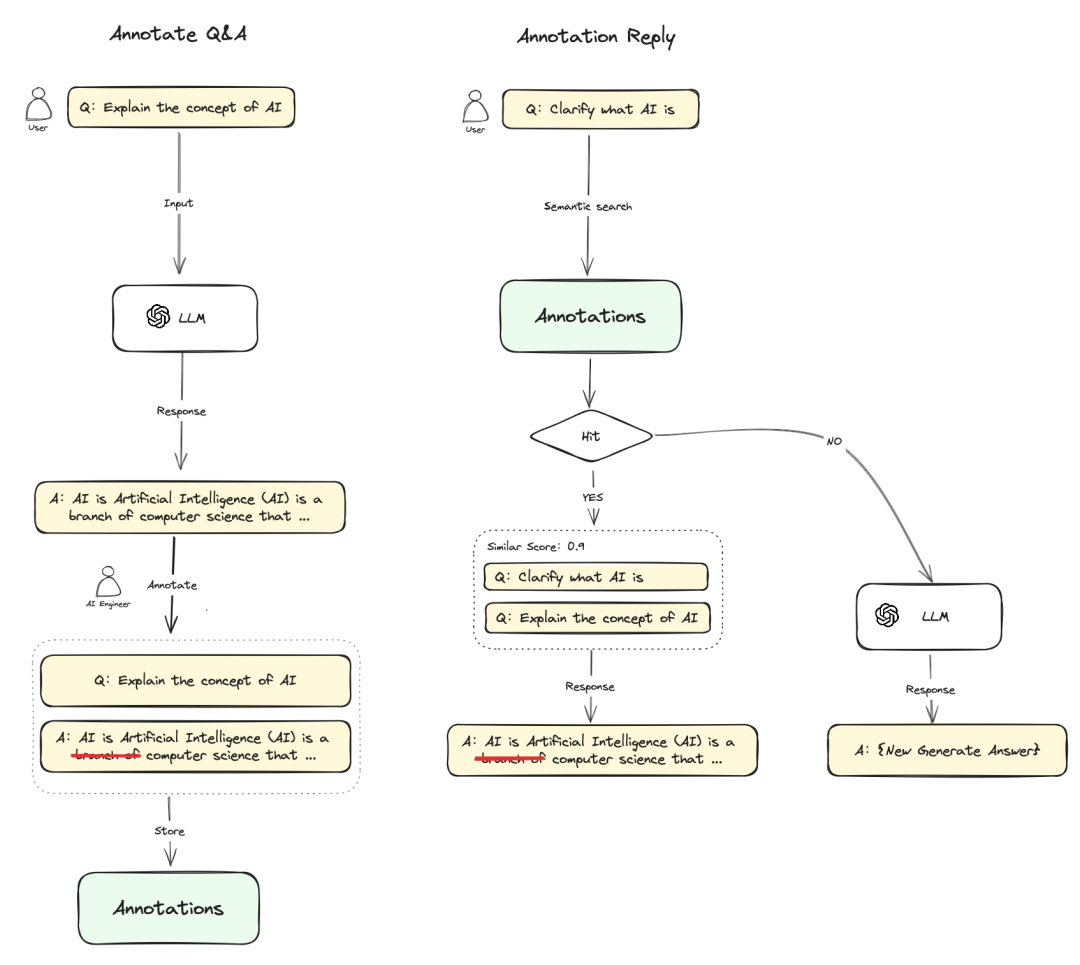
标注回复参数包括:Score 阈值 和 Embedding 模型。
-
Score 阈值:用于设置标注回复的匹配相似度阈值,只有高于阈值分数的标注会被召回。
-
Embedding 模型:用于对标注文本进行向量化,切换模型时会重新生成嵌入。
1.App标注
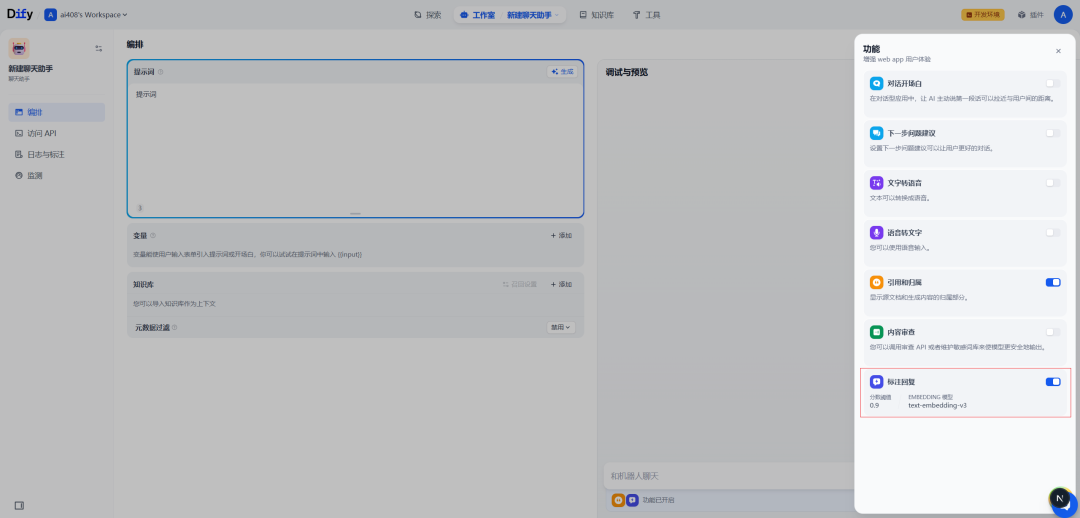
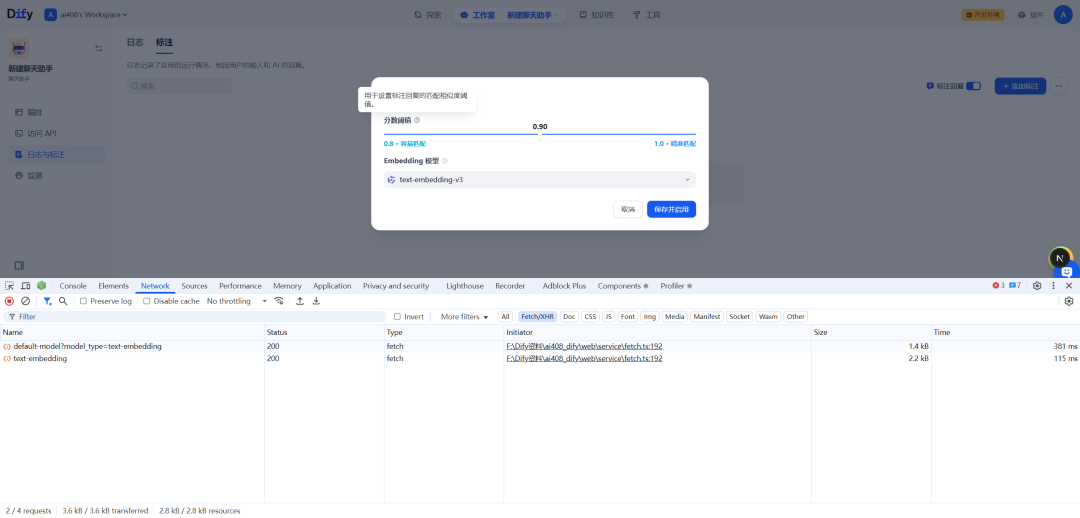
2.message标注
3.migrate_annotation_vector_database源码
该函数 migrate_annotation_vector_database 主要用于将注释数据迁移到目标向量数据库。
defmigrate_annotation_vector_database():
"""
Migrate annotation datas to target vector database .
"""
click.echo(click.style("Starting annotation data migration.", fg="green"))
create_count = 0
skipped_count = 0
total_count = 0
page = 1
whileTrue:
try:
# get apps info
per_page = 50
apps = (
db.session.query(App)
.filter(App.status == "normal")
.order_by(App.created_at.desc())
.limit(per_page)
.offset((page - 1) * per_page)
.all()
)
ifnot apps:
break
except NotFound:
break
page += 1
for app in apps:
total_count = total_count + 1
click.echo(
f"Processing the {total_count} app {app.id}. " + f"{create_count} created, {skipped_count} skipped."
)
try:
click.echo("Creating app annotation index: {}".format(app.id))
app_annotation_setting = (
db.session.query(AppAnnotationSetting).filter(AppAnnotationSetting.app_id == app.id).first()
)
ifnot app_annotation_setting:
skipped_count = skipped_count + 1
click.echo("App annotation setting disabled: {}".format(app.id))
continue
# get dataset_collection_binding info
dataset_collection_binding = (
db.session.query(DatasetCollectionBinding)
.filter(DatasetCollectionBinding.id == app_annotation_setting.collection_binding_id)
.first()
)
ifnot dataset_collection_binding:
click.echo("App annotation collection binding not found: {}".format(app.id))
continue
annotations = db.session.query(MessageAnnotation).filter(MessageAnnotation.app_id == app.id).all()
dataset = Dataset(
id=app.id,
tenant_id=app.tenant_id,
indexing_technique="high_quality",
embedding_model_provider=dataset_collection_binding.provider_name,
embedding_model=dataset_collection_binding.model_name,
collection_binding_id=dataset_collection_binding.id,
)
documents = []
if annotations:
for annotation in annotations:
document = Document(
page_content=annotation.question,
metadata={"annotation_id": annotation.id, "app_id": app.id, "doc_id": annotation.id},
)
documents.append(document)
vector = Vector(dataset, attributes=["doc_id", "annotation_id", "app_id"])
click.echo(f"Migrating annotations for app: {app.id}.")
try:
vector.delete()
click.echo(click.style(f"Deleted vector index for app {app.id}.", fg="green"))
except Exception as e:
click.echo(click.style(f"Failed to delete vector index for app {app.id}.", fg="red"))
raise e
if documents:
try:
click.echo(
click.style(
f"Creating vector index with {len(documents)} annotations for app {app.id}.",
fg="green",
)
)
vector.create(documents)
click.echo(click.style(f"Created vector index for app {app.id}.", fg="green"))
except Exception as e:
click.echo(click.style(f"Failed to created vector index for app {app.id}.", fg="red"))
raise e
click.echo(f"Successfully migrated app annotation {app.id}.")
create_count += 1
except Exception as e:
click.echo(
click.style(
"Error creating app annotation index: {} {}".format(e.__class__.__name__, str(e)), fg="red"
)
)
continue
click.echo(
click.style(
f"Migration complete. Created {create_count} app annotation indexes. Skipped {skipped_count} apps.",
fg="green",
)
)
二.初始化与分页循环
-
初始化计数器(创建数、跳过数、总数、页码)。
-
进入分页循环,每次处理一页(50个)App。
defmigrate_annotation_vector_database():
"""
Migrate annotation datas to target vector database .
"""
click.echo(click.style("Starting annotation data migration.", fg="green"))
create_count = 0
skipped_count = 0
total_count = 0
page = 1
whileTrue:
try:
# get apps info
per_page = 50
apps = (
db.session.query(App)
.filter(App.status == "normal")
.order_by(App.created_at.desc())
.limit(per_page)
.offset((page - 1) * per_page)
.all()
)
ifnot apps:
break
except NotFound:
break
page += 1
三.遍历每个 App,处理注释迁移
这段代码是一个数据迁移工具,它从SQL数据库中提取应用程序注释数据,并准备将其转换为向量形式以支持语义搜索功能。
for app in apps:
total_count = total_count + 1
click.echo(
f"Processing the {total_count} app {app.id}. " + f"{create_count} created, {skipped_count} skipped."
)
try:
click.echo("Creating app annotation index: {}".format(app.id))
app_annotation_setting = (
db.session.query(AppAnnotationSetting).filter(AppAnnotationSetting.app_id == app.id).first()
)
ifnot app_annotation_setting:
skipped_count = skipped_count + 1
click.echo("App annotation setting disabled: {}".format(app.id))
continue
# get dataset_collection_binding info
dataset_collection_binding = (
db.session.query(DatasetCollectionBinding)
.filter(DatasetCollectionBinding.id == app_annotation_setting.collection_binding_id)
.first()
)
ifnot dataset_collection_binding:
click.echo("App annotation collection binding not found: {}".format(app.id))
continue
annotations = db.session.query(MessageAnnotation).filter(MessageAnnotation.app_id == app.id).all()
dataset = Dataset(
id=app.id,
tenant_id=app.tenant_id,
indexing_technique="high_quality",
embedding_model_provider=dataset_collection_binding.provider_name,
embedding_model=dataset_collection_binding.model_name,
collection_binding_id=dataset_collection_binding.id,
)
documents = []
if annotations:
for annotation in annotations:
document = Document(
page_content=annotation.question,
metadata={"annotation_id": annotation.id, "app_id": app.id, "doc_id": annotation.id},
)
documents.append(document)
1.执行流程
(1)循环遍历检索到的应用程序列表,并显示处理进度
for app in apps:
total_count = total_count + 1
click.echo(f"Processing the {total_count} app {app.id}. " + f"{create_count} created, {skipped_count} skipped.")
(2)检查应用程序是否启用了注释功能(AppAnnotationSetting)
-
查询应用程序的注释设置
-
如果没有找到设置,则跳过当前应用程序
(3)验证注释设置对应的数据集绑定(DatasetCollectionBinding)
-
获取
dataset_collection_binding信息,这包含了向量数据库的配置信息 -
如果找不到绑定信息,则跳过当前应用程序
(4)查询该 App 的所有注释(MessageAnnotation)
annotations = db.session.query(MessageAnnotation).filter(MessageAnnotation.app_id == app.id).all()
(5)创建新的Dataset对象,用于向量存储
dataset = Dataset(
id=app.id,
tenant_id=app.tenant_id,
indexing_technique="high_quality",
embedding_model_provider=dataset_collection_binding.provider_name,
embedding_model=dataset_collection_binding.model_name,
collection_binding_id=dataset_collection_binding.id,
)
(6)将注释转换为向量数据库可接受的文档格式
-
为每个注释创建一个
Document对象 -
文档包含注释的问题内容和相关元数据
-
这些文档将用于后续步骤中创建向量索引
2.相关数据表
(1)AppAnnotationSetting数据表
AppAnnotationSetting 类代表应用程序注释设置,主要用于配置与应用相关的注释检索参数,特别是通过设置分数阈值来确定哪些注释内容应该被返回给用户。
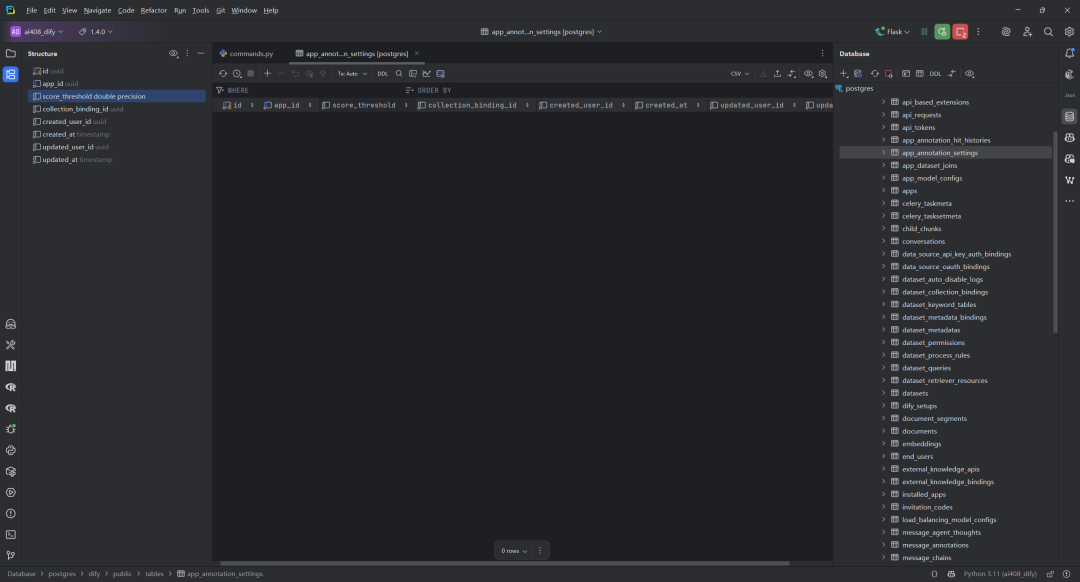
字段详细说明,如下所示:
-
id:主键,UUID格式,自动生成 -
app_id:应用ID,指定这些设置属于哪个应用 -
score_threshold:分数阈值,浮点型,默认为0,用于设置注释匹配的最低匹配分数 -
collection_binding_id:数据集集合绑定ID,关联到特定的嵌入数据集集合 -
created_user_id:创建者用户ID,记录谁创建了这个设置 -
created_at:创建时间,自动设置为当前时间 -
updated_user_id:更新者用户ID,记录最后修改设置的用户 -
updated_at:更新时间,自动设置为当前时间
collection_binding_detail 属性方法从数据库中查询并返回与 collection_binding_id 关联的 DatasetCollectionBinding 对象,提供了访问底层嵌入模型配置的能力。
(2)DatasetCollectionBinding数据表
DatasetCollectionBinding 类定义了数据集与向量存储集合之间的绑定关系。该类主要用于跟踪和管理数据集在向量数据库中的存储位置,建立了数据集、嵌入模型和向量集合之间的映射关系,是RAG系统中连接数据索引和检索的重要组件。
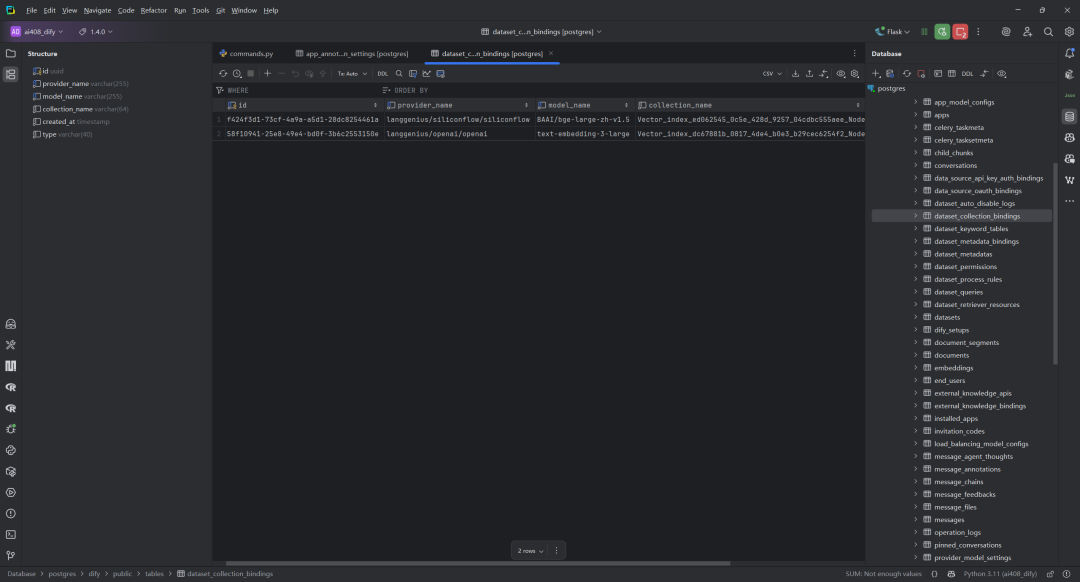
字段详细解释,如下所示:
-
id: 主键,使用 UUID 自动生成的唯一标识符 -
provider_name: 提供商名称,指向量数据库或嵌入模型的提供商(如OpenAI、Pinecone等) -
model_name: 模型名称,用于指定使用的嵌入模型(如text-embedding-ada-002等) -
type: 绑定类型,默认为”dataset”,表示该绑定关联的是数据集 -
collection_name: 集合名称,在向量数据库中的实际集合名称,长度限制为64字符 -
created_at: 记录创建时间,自动设置为当前时间戳
(3)MessageAnnotation数据表
MessageAnnotation 表的功能是存储与消息相关的注释信息。
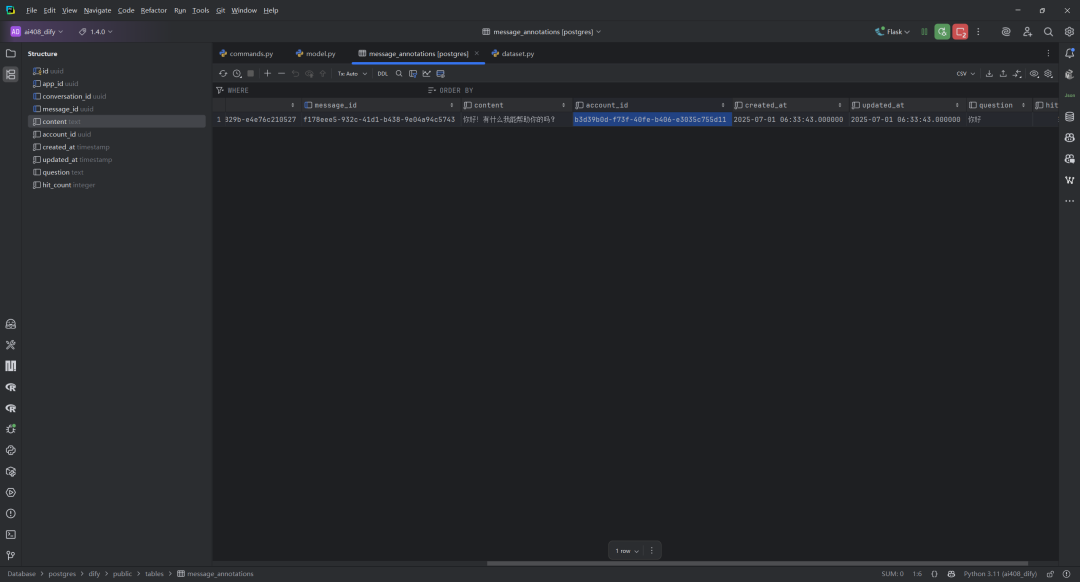
字段解释,如下所示:
-
id: 主键,唯一标识每条记录,使用uuid_generate_v4()自动生成。 -
app_id: 外键,关联到应用(App)的唯一标识,表示该注释所属的应用。 -
conversation_id: 外键,关联到会话(Conversation)的唯一标识,表示该注释所属的会话(可为空)。 -
message_id: 外键,关联到消息(Message)的唯一标识,表示该注释所属的消息(可为空)。 -
question: 可选字段,存储与注释相关的问题内容。 -
content: 必填字段,存储注释的具体内容。 -
hit_count: 整数类型,记录注释被命中的次数,默认值为 0。 -
account_id: 外键,关联到账户(Account)的唯一标识,表示创建该注释的用户。 -
created_at: 时间戳,记录注释的创建时间,默认值为当前时间。 -
updated_at: 时间戳,记录注释的最后更新时间,默认值为当前时间。
属性方法
-
account: 返回与account_id关联的账户对象。 -
annotation_create_account: 同样返回与account_id关联的账户对象(功能与account类似)。
三.删除旧向量索引,创建新索引
该代码是应用程序注释(annotations)向量索引迁移过程的核心部分。具体实现了向量数据库迁移的完整流程:删除旧索引→创建新索引→处理异常情况,同时提供了详细的日志记录。
vector = Vector(dataset, attributes=["doc_id", "annotation_id", "app_id"])
click.echo(f"Migrating annotations for app: {app.id}.")
try:
vector.delete()
click.echo(click.style(f"Deleted vector index for app {app.id}.", fg="green"))
except Exception as e:
click.echo(click.style(f"Failed to delete vector index for app {app.id}.", fg="red"))
raise e
if documents:
try:
click.echo(
click.style(
f"Creating vector index with {len(documents)} annotations for app {app.id}.",
fg="green",
)
)
vector.create(documents)
click.echo(click.style(f"Created vector index for app {app.id}.", fg="green"))
except Exception as e:
click.echo(click.style(f"Failed to created vector index for app {app.id}.", fg="red"))
raise e
click.echo(f"Successfully migrated app annotation {app.id}.")
create_count += 1
except Exception as e:
click.echo(
click.style(
"Error creating app annotation index: {} {}".format(e.__class__.__name__, str(e)), fg="red"
)
)
continue
执行流程,如下所示:
1.向量对象初始化
创建一个Vector实例,传入dataset参数和需要保留的三个属性字段。
vector = Vector(dataset, attributes=["doc_id", "annotation_id", "app_id"])
2.迁移日志输出
输出正在为特定应用程序迁移注释数据的信息。
click.echo(f"Migrating annotations for app: {app.id}.")
3.删除现有向量索引(vector.delete)
尝试删除可能存在的旧向量索引。成功时输出绿色成功消息,失败时输出红色错误消息并重新抛出异常。
try:
vector.delete()
click.echo(click.style(f"Deleted vector index for app {app.id}.", fg="green"))
except Exception as e:
click.echo(click.style(f"Failed to delete vector index for app {app.id}.", fg="red"))
raise e
4.创建新向量索引(vector.create)
如果有文档数据,则尝试创建新的向量索引。这里会显示创建的注释数量,并记录成功或失败状态。
if documents:
try:
click.echo(...)
vector.create(documents)
click.echo(click.style(f"Created vector index for app {app.id}.", fg="green"))
except Exception as e:
click.echo(click.style(f"Failed to created vector index for app {app.id}.", fg="red"))
raise e
5.迁移完成记录
记录迁移成功并增加成功创建的计数器。
click.echo(f"Successfully migrated app annotation {app.id}.")
create_count += 1
6.异常处理
捕获整个过程中可能发生的任何异常,记录错误后继续处理下一个应用程序,确保一个应用程序的失败不会中断整个迁移过程。
except Exception as e:
click.echo(click.style(...))
continue
四.迁移结束输出统计信息
循环结束后,输出迁移完成的统计信息。
click.echo(
click.style(
f"Migration complete. Created {create_count} app annotation indexes. Skipped {skipped_count} apps.",
fg="green",
)
)
总结:该函数分页遍历所有正常状态的 App。对每个 App,查找注释设置和数据集绑定,生成文档列表。删除旧的向量索引,创建新的向量索引。统计并输出迁移结果。
参考文献
[0] commands.py中的migrate_annotation_vector_database()函数解析:https://z0yrmerhgi8.feishu.cn/wiki/PWR9wOxHKiCG6kkSYXLcAKHnnTf
[1] Dify日志与标注:https://docs.dify.ai/zh-hans/guides/annotation/logs
[2] Dify标注回复:https://docs.dify.ai/zh-hans/guides/annotation/annotation-reply
知识星球服务内容:Dify源码剖析及答疑,Dify对话系统源码,NLP电子书籍报告下载,公众号所有付费资料。加微信buxingtianxia21进NLP工程化资料群。
(文:NLP工程化)