


论文链接:
https://arxiv.org/pdf/2507.00606
论文标题:
Mixtureof Reasonings: Teach Large Language Models to Reason with
Adaptive Strategies
一句话理解:
本文呢的核心内容是关于如何通过“混合推理策略”(MixtureofReasoning,简称MoR)来提升大型语言模型(LLMs)在复杂推理任务中的表现。以下是文章的主要内容概述:
研究背景与动机
现有方法的局限性:当前的大型语言模型(LLMs)在复杂任务中表现出色,主要依赖于先进的提示技术,如“思维链”(Chain-of-Thought,CoT)和“思维树”(Tree-of-Thought,ToT)。然而,这些方法依赖于手动设计的任务特定提示,这不仅耗时,而且难以在不同任务之间进行优化。这种对提示工程的依赖成为了一个关键瓶颈,限制了模型的适应性和效率。
研究目标:为了解决这一问题,文章提出了一种新的训练框架——“混合推理”(MoR),该框架将多种推理策略直接嵌入到LLMs中,使模型能够自主地选择和应用适合特定任务的有效推理方法,而无需外部提示工程。
研究方法
MoR框架:MoR框架包含两个主要阶段:
1.思维生成(ThoughtGeneration):使用像GPT-4o这样的高级模型生成大规模的推理链模板。这些模板覆盖了多种推理模式,包括多步推理、类比推理和策略性思考。
2.监督微调数据集构建(SFTDatasetConstruction):将生成的推理链模板与基准数据集中的样本配对,创建一个用于监督微调的训练数据集。通过这种方式,模型学会了根据任务结构选择最合适的推理链。
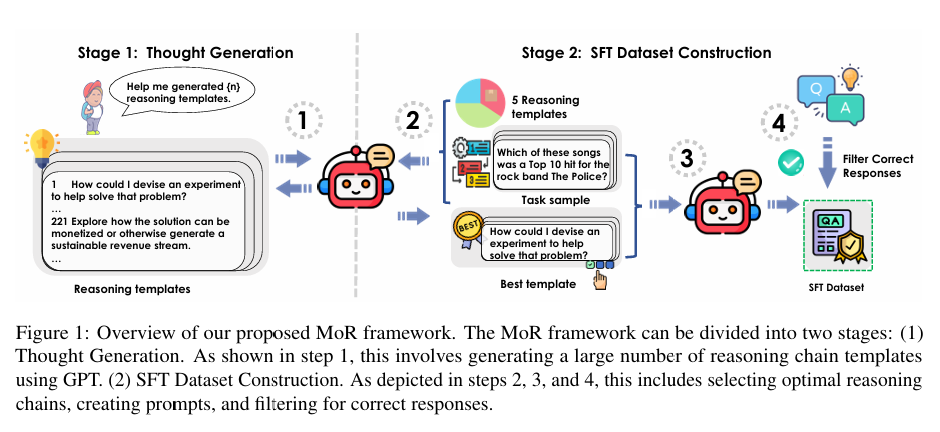
实验设计:作者选择了五个推理数据集(HotpotQA、StrategyQA、MMLU、BigTom和TrivialCreativeWriting),并从每个数据集中随机选择50个样本进行测试。通过不同的推理链模板数量(如50、150、300和500)来训练模型,并评估其性能。
实验结果
性能提升:实验结果表明,MoR显著提升了模型的性能。例如,MoR150模型在使用CoT提示时达到了0.730的准确率,比基线模型提高了2.2%;在直接输入输出(IO)提示时达到了0.734的准确率,比基线模型提高了13.5%。
案例分析:文章通过具体的案例展示了MoR模型与基线模型的差异。例如,在BigTom数据集上,基线模型未能考虑主人公信念的变化,导致推理不完整和答案错误,而MoR模型能够选择有效的策略,通过逻辑推理正确解决问题。

结论
MoR的优势:MoR框架通过将多种推理策略嵌入到LLMs中,消除了对任务特定提示的依赖,使模型能够自主适应不同任务的推理需求。这种方法不仅提高了模型的性能,还增强了其在复杂推理任务中的泛化能力。
未来工作:作者计划进一步扩展推理模板的多样性,并将MoR与其他先进的训练范式相结合,以进一步提升其在更具挑战性领域的有效性。
创新点与贡献
创新的训练框架:MoR框架通过内部化推理能力,使模型能够自主选择和应用多种推理策略,而无需外部提示工程。
显著的性能提升:通过实验验证,MoR在多个推理任务中显著优于基线模型,尤其是在复杂任务中。
泛化能力:MoR不仅提升了特定任务的性能,还增强了模型在不同任务之间的泛化能力。
总的来说,这篇文章提出了一种新的方法来提升LLMs在复杂推理任务中的表现,通过混合多种推理策略并将其嵌入模型中,使模型能够自主适应不同任务的需求。这种方法为未来的研究提供了新的方向,尤其是在减少对提示工程的依赖和提升模型泛化能力方面。
(文:机器学习算法与自然语言处理)