

vivo AI Lab 投稿
量子位 | 公众号 QbitAI
vivo AI Lab发布AI多模态新模型了,专门面向端侧设计,紧凑高效~
能够直接理解GUI页面的那种:
模型BlueLM-2.5-3B,融合文本和图文的理解和推理能力,支持长短思考模式自由切换,并引入思考预算控制机制。
与同尺寸模型相比,BlueLM-2.5-3B在多个文本与多模态评测任务中表现出色。
BlueLM-2.5-3B支持思考预算控制(thinking token budget),有效平衡思考深度和推理成本:

兼具多模态推理和文本的推理能力,思考范围扩展:

另外值得一提的是,作者对模型结构与训练策略进行了深度优化,显著降低了训练和推理成本。通过优质数据筛选、自动配比策略以及大规模推理合成数据,模型的数据利用效率大幅提升。
同时,模型训练全过程由自建的高性能训练平台与框架高效支撑,确保了训练效率和训练稳定性。
以下是更多细节。
在20余项评测任务中表现出色
BlueLM-2.5-3B在20余项评测任务中展现出如下核心优势:
1、文本任务表现出色,缓解能力遗忘难题
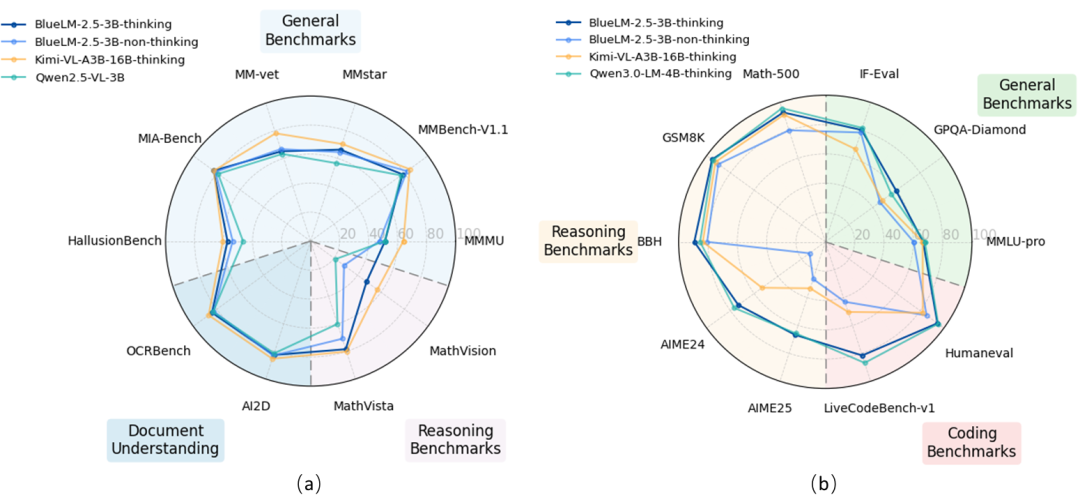
BlueLM-2.5-3B在thinking、non-thinking不同模式下,在文本任务上与同规模文本模型Qwen3-4B效果相近,领先于同规模以及更大规模的多模态模型。
这主要得益于数据策略以及训练策略较好地缓解了困扰多模态模型训练的文本能力遗忘难题。
thinking模式下,与4B以下同规模具有思考模式的文本模型Qwen3-4B-thinking相比,BlueLM-2.5-3B除代码类任务外其他大部分文本任务效果相近;与同规模多模态模型如Qwen2.5-VL-3B相比指标全面领先;与更大规模的具有思考模式的多模态模型Kimi-VL-A3B-16B-thinking相比,文本效果全面领先。
thinking模式下推理类任务(如Math-500、GSM8K、AIME)效果也显著优于更大规模的没有thinking模式的模型如 Qwen2.5-VL-72B。
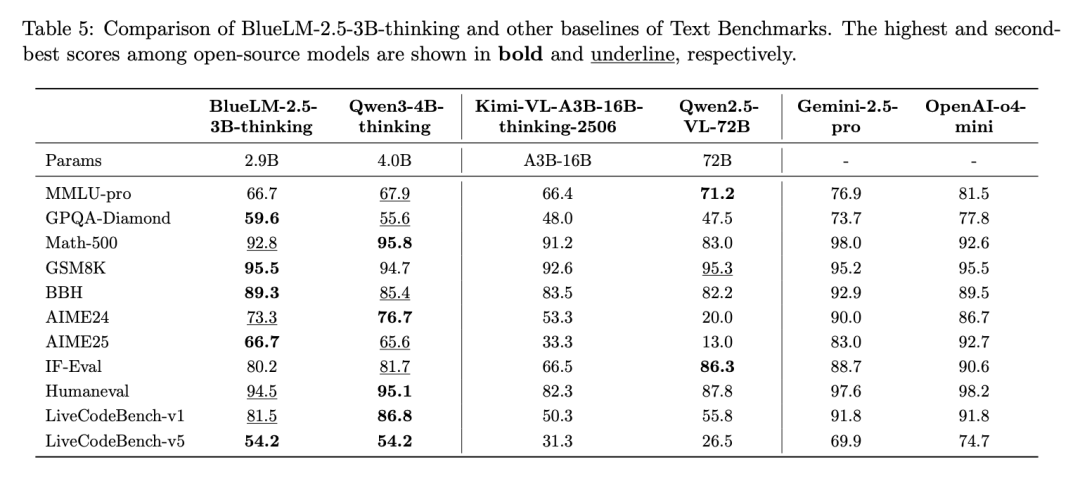
non-thinking模式下,与同规模文本模型Qwen3-4B-non-thinking相比,文本效果相当。
明显优于同规模多模态模型Qwen2.5-VL-3B、Gemma3-4B,其中推理类任务如Math-500、BBH、AMIE24、AIME25优势更为明显。
与更大规模多模态模型Kimi-VL-A3B-16B-non-thinking 相比全部指标均更优,尤其是推理类任务的优势更明显。
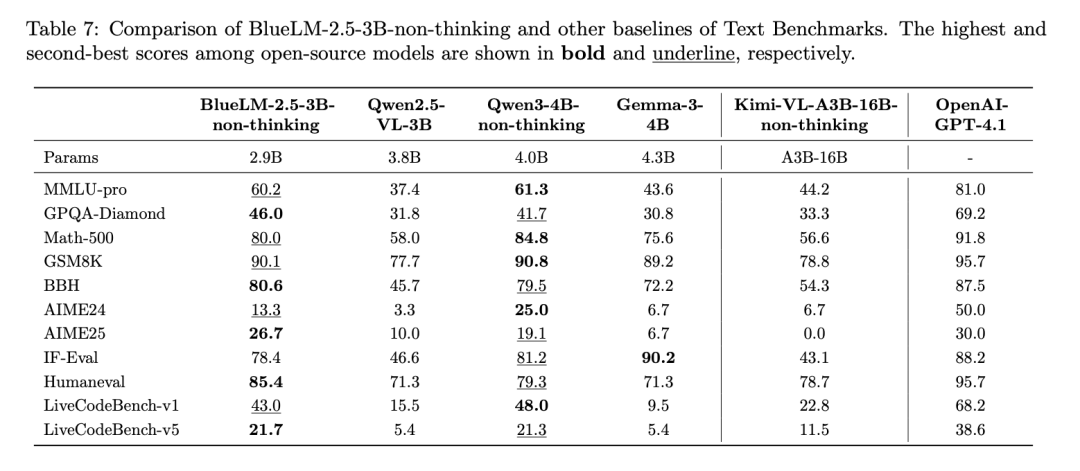
2、多模态理解能力领先同规模模型
BlueLM-2.5-3B在thinking、non-thinking不同模式下,在多模态任务上领先于同规模多模态模型,与更大规模的多模态模型效果相近。
thinking模式下,与更大规模模型Kimi-VL-A3B-16B-thinking相比,大多数评测任务的差距在5%以内;在推理相关任务如MathVista和MathVision的效果优于没有thinking模式的Qwen2.5-VL-72B。
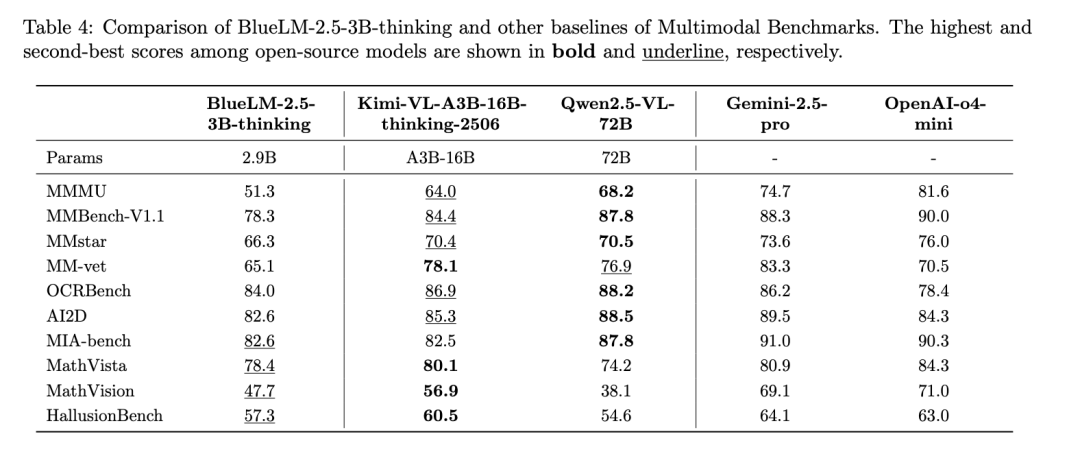
non-thinking模式下,与同规模模型Qwen2.5-VL-3B相比,指标全面领先,其中推理类任务Mathvista、Mathvision优势明显;与Gemma-3-4B相比效果更优;与更大规模模型Kimi-VL-A3B-16B-non-thinking相比,超过半数指标领先,其余指标差距在5%以内;与行业领先模型相比,一半左右评测集差距在5%以内。
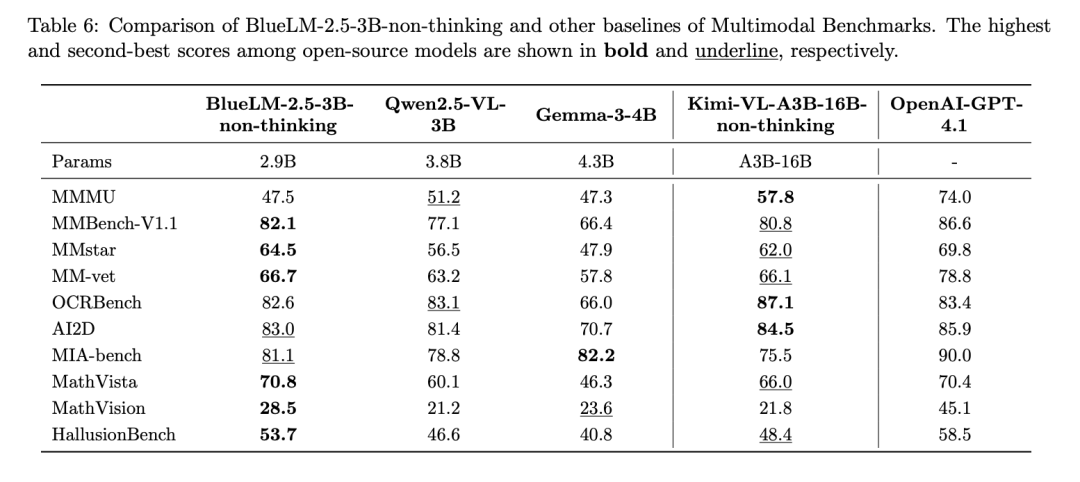
3、同时支持文本和多模态的长短思考以及思考预算控制
上述评测结果显示,BlueLM-2.5-3B 同时具备了文本与多模态的thinking 模式。长思考模式显著提升复杂推理任务上的模型效果。
例如,在AIME25 任务中thinking模式较之non-thinking 模式提高达40分,在MathVision 任务中提高达19.2分。
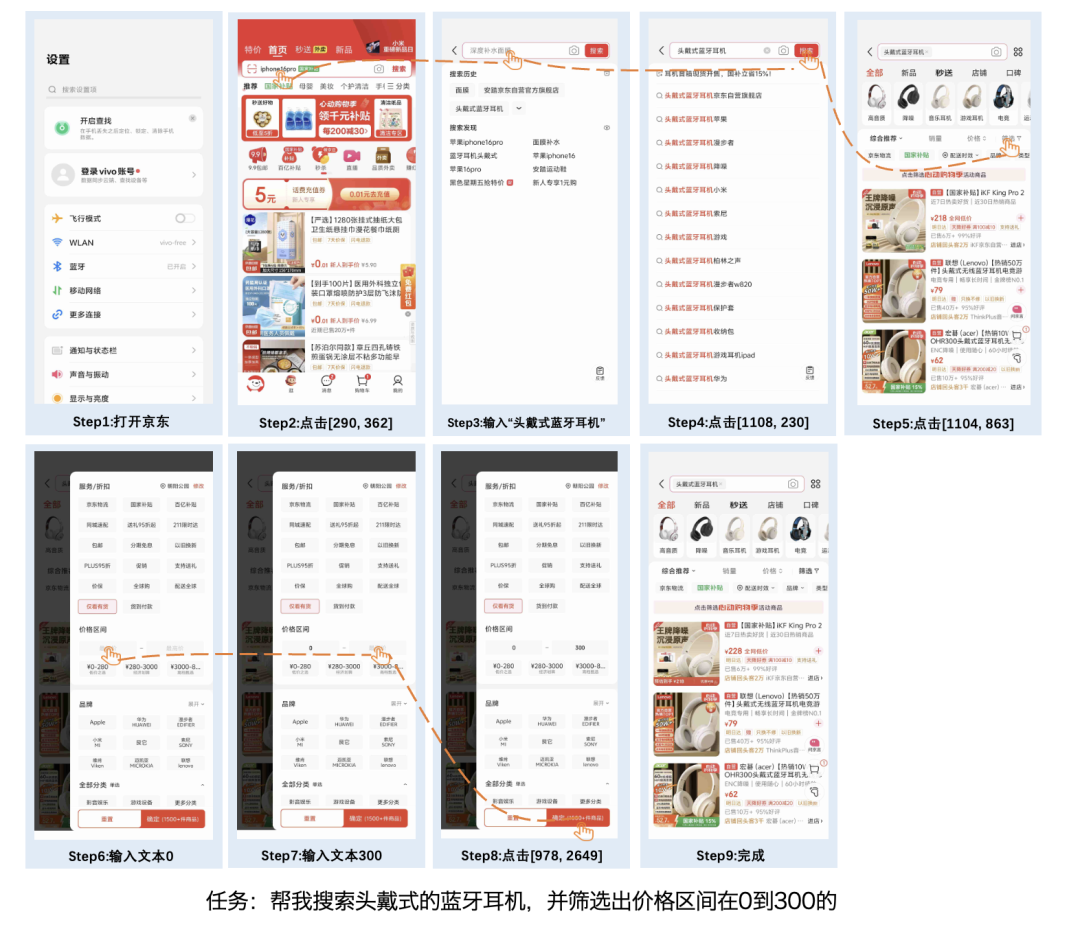
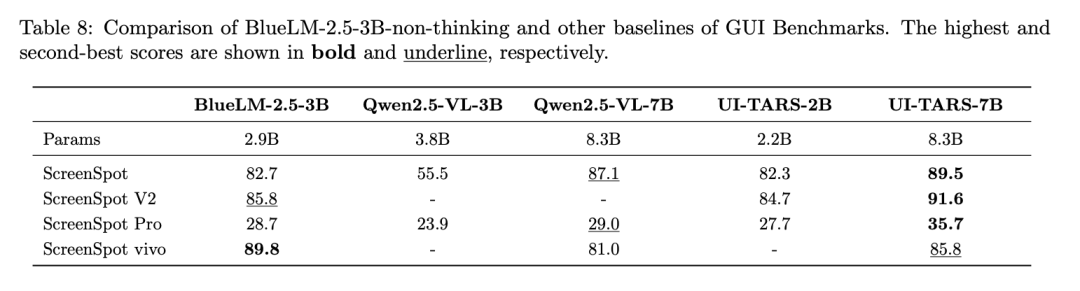
4、GUI理解能力领先同规模模型
与同规模模型相比,BlueLM-2.5-3B在GUI grounding指标上全面领先,例如ScreenSpot、ScreenSpot V2、ScreenSpot Pro的得分均超过了Qwen2.5-VL-3B和UI-TARS-2B。
与更大规模模型如Qwen2.5-VL-7B、UI-TARS 7B相比存在一定差距。得益于采集标注了大量中文app截屏数据,在中文评测集ScreenSpot vivo得分高于其他模型。
精巧模型结构与高效训练
为支撑模型上述效果,BlueLM-2.5-3B设计了精巧紧凑的模型结构和高效的训练策略。
模型结构
BlueLM-2.5-3B面向端侧部署,参数量仅2.9B,比同规模的模型如Qwen2.5-VL-3B小22%以上,具有训练和推理的成本优势。
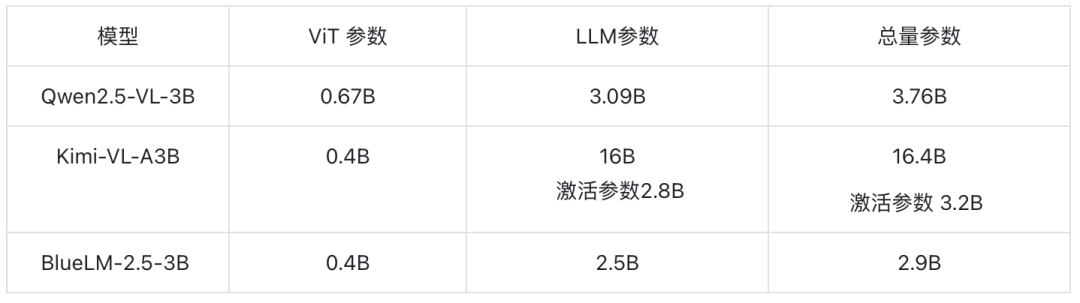
BlueLM-2.5-3B模型由ViT、Adapter、LLM组成。如图所示:
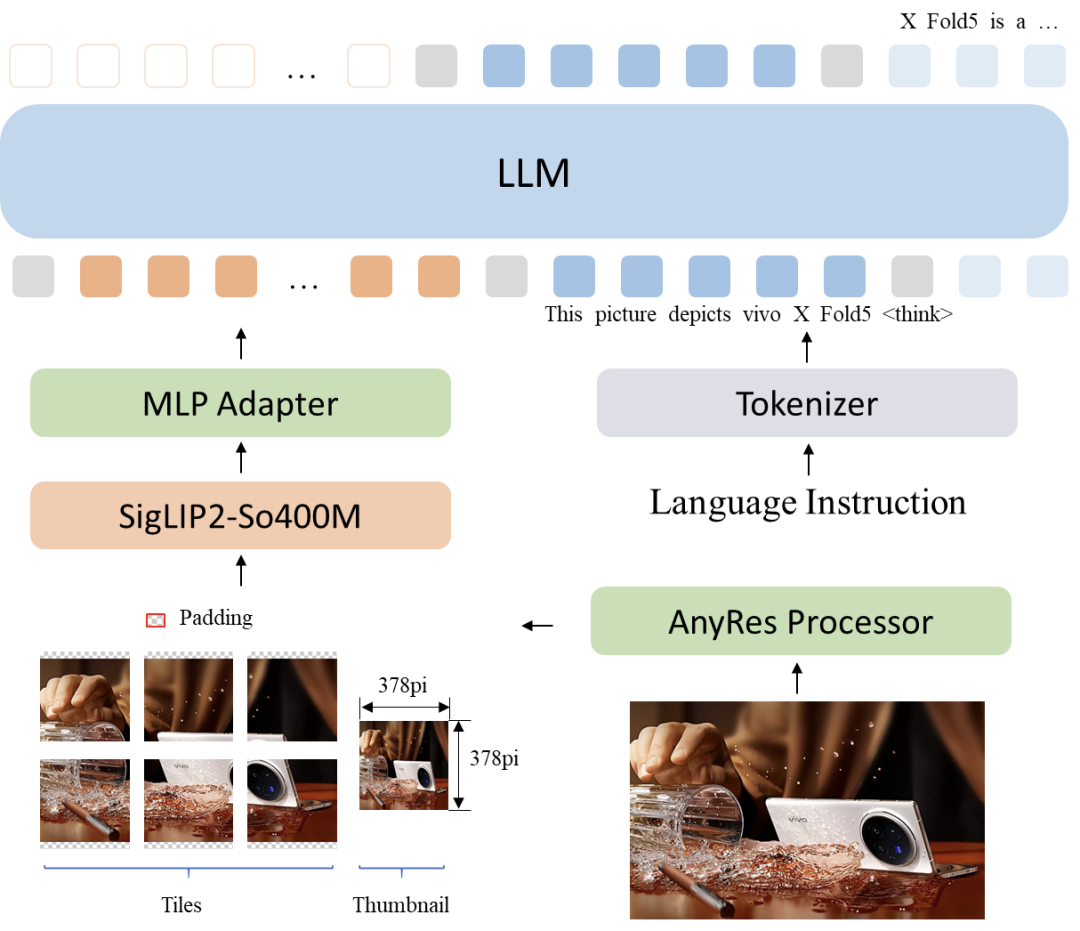
ViT采用400M参数量的SigLIP2(so400m-patch14-384)。 采用AnyRes方案支持动态分辨率,最大图像输入1512×1512。切完子图后,固定长度token便于端侧部署,且子图并行推理,推理耗随输入token数量线性增长。此外,小尺寸ViT也有助于进一步降低功耗。
图像token经Adapter投影后接入LLM Decoder。
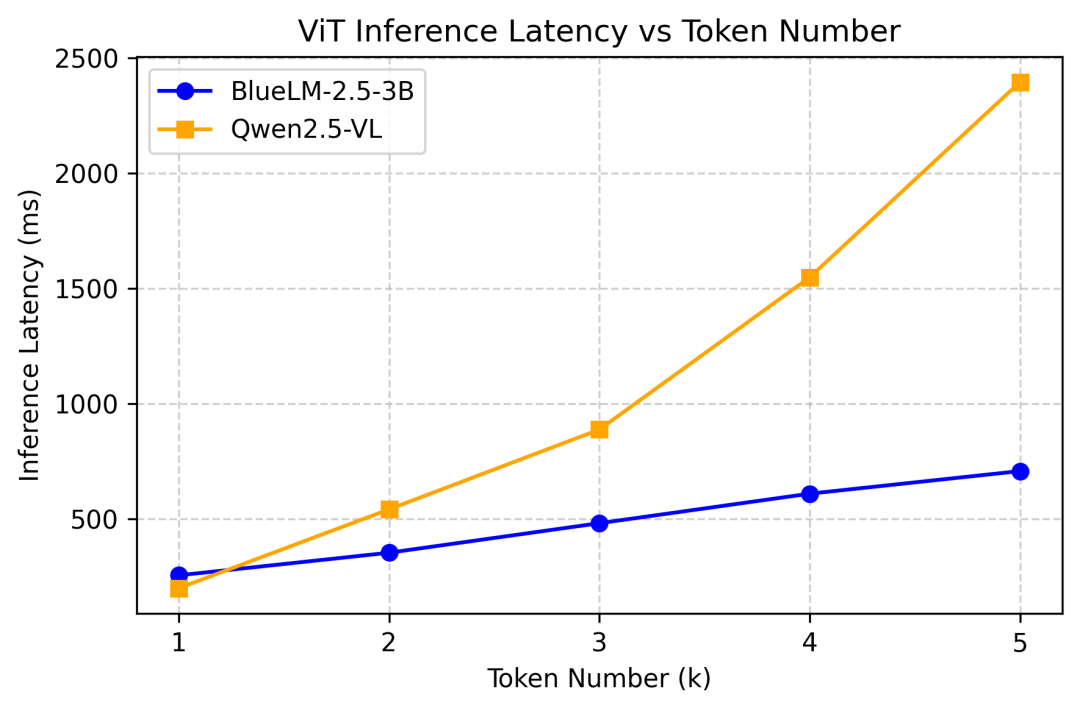
下图展示了BlueLM-2.5-3B优秀的ViT推理性能:
预训练策略
文本和多模态的预训练共分为4个阶段:
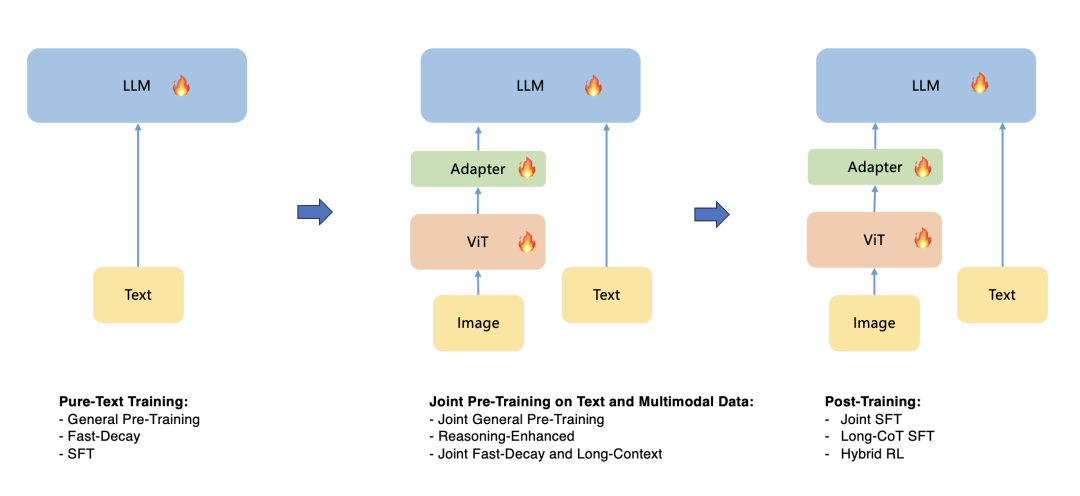
1、文本数据预训练策略(Pure-Text Pre-training Stage)
LLM Decoder参数采用文本模型初始化。文本模型采用了“大模型裁剪+蒸馏”的三阶段训练策略,包括普通预训练(General Pre-training)、快速衰减(Fast-Decay, FD)和微调(SFT)。
首先训练7B教师模型并裁剪得到3B文本模型,再继续用3T tokens蒸馏预训练以及300B tokens FD蒸馏训练。
相比从零训练的同尺寸模型,性能提升超 4%。
2、文本和图文数据联合预训练 (Joint Pre-training Stage)
先冻结ViT和LLM参数,利用2.5M条图文对数据训练Adapter;再解冻全参数进行全量训练。
通过设置64M的大batch size、统一12T tokens全局学习率衰减调度及对ViT的分层学习率控制,有效提升了训练效率与稳定性。
这一阶段,作者实现了训练流程简化,省略了一般方案中ViT+Adapter的单独训练阶段,直接全量训练。
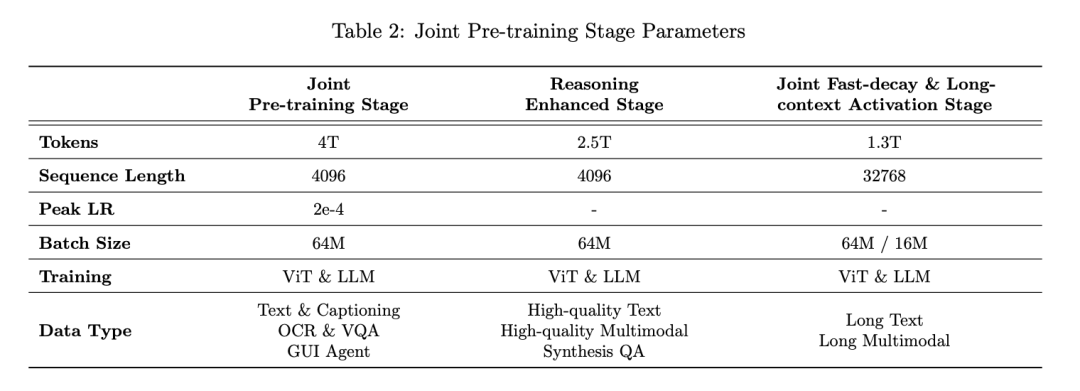
3、推理增强数据的继续训练(Reasoning-Enhanced Stage)
作者在文本数据中提升STEM、编程、逻辑推理以及高质量合成数据的占比。
合成数据覆盖了短COT和长COT数据。在多模态数据中引入大量高质量的推理相关的图文问答对。这一阶段共使用2.5T tokens数据。
将文本任务的推理增强训练后置到多模态阶段,有效避免了文本推理能力遗忘,提升了训练效率。
4、快速衰减与长文联合训练(Joint Fast-decay and Long-context Activation Stage)
快速衰减阶段同时进行长文训练。位置编码从 Rope调整为 Yarn。
这一阶段使用1.3T tokens,序列长度从4K扩展到32K。通过逐步将原生长文和高质量长推理数据占比增至80%以上、减小Global Batch Size,有效提升模型的长思考能力。
后训练策略
BlueLM-2.5-3B的后训练分为2个阶段:
1、SFT训练
SFT阶段将文本与多模态任务联合微调,引入特殊token [|BlueThink|] 控制思考模式是否触发。这一阶段序列长度保持为32K。根据学习难度差异,作者将常规COT数据训练3 epoch,长COT数据训练9 epoch。
2、RL训练
RL阶段混合使用了基于人类偏好反馈的强化学习(RLHF)方法和基于可验证奖励的强化学习(RLVR)方法,使用GRPO算法进行优化。
开放问答类任务,使用RLHF方法。对文本写作、总结等任务,使用生成式奖励模型从相关性、准确性、有用性、冗余性维度进行打分优化;而模型安全能力的提升,则使用判别式奖励模型进行优化。
对有明确答案或评测标准的任务,如数学、代码等推理相关任务,使用RLVR方法。作者使用规则结合verify模型进行正确性打分,最终奖励分数综合考虑答案正确性、格式正确性和重复情况和长度,其中为了优化模型“过度思考”的问题,作者引入“Group Overlong”的长度惩罚机制。
高质量训练数据
模型性能背后离不开高质量训练数据的支持。BlueLM-2.5-3B的训练数据有如下特点:
1)相较于同规模模型如Qwen2.5-VL-3B,预训练数据总量减少了约23%,这主要得益于对文本模型训练数据的有效压缩。文本模型训练数据仅为Qwen3-4B 的25%、Qwen2.5的48%。
2)BlueLM-2.5-3B的多模态预训练数据显著多于其他模型,主要因为文本推理能力训练后置合并到多模态训练阶段。累计引入3.3T tokens推理增强数据,为小模型具备较强推理能力奠定了坚实的数据基础。
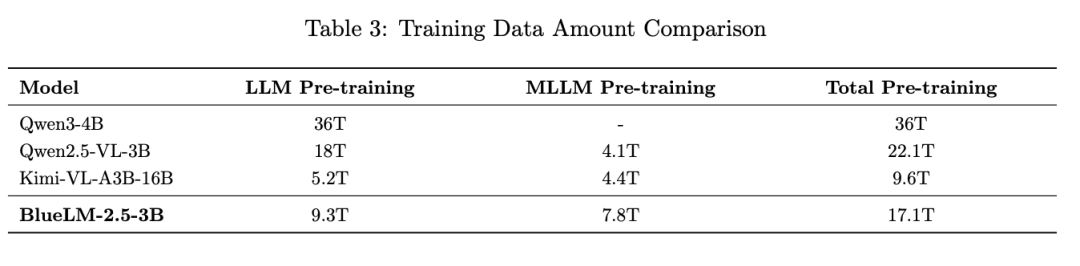
文本预训练数据
文本模型预训练阶段共计使用9.3T tokens,其中6T tokens用于教师模型训练,3.3T tokens 用于学生模型的蒸馏训练。
多模态预训练数据
多模态模型的预训练数据为4T tokens,涵盖Image Caption、OCR、GUI、纯文本以及其他类型数据。其中纯文本1.6T,图文对2.4T。通过将文本数据占比提升至40%,有效缓解了多模态预训练阶段文本能力遗忘问题。
另外,从预训练阶段开始就引入GUI等业务相关数据,有效提升基模在业务场景的能力上限。
推理训练数据
作者构建两阶段的数据合成pipeline生产大规模推理数据,第一阶段通过多种途径获取原始问题并改写扩充规模。第二阶段通过多次采样同一问题获得不同的推理路径,结合规则检查、拒绝采样以及投票技术筛选高质量答案。
长文本数据
作者引入了由长文本与图文混合构成的长上下文训练数据。在原生长文本数据的基础上,引入高质量的长距离推理数据,有效提升了模型在多模态场景下的上下文理解深度与推理稳定性。
SFT数据
作者构造了高质量SFT数据集。从社区和内部业务广泛收集问题及图片,经过标注分类和指令去重后,围绕能力维度重建了多样化的新指令集。然后用多个强模型生成候选答案,结合规则过滤、模型打分、多数投票、人工校验等方法,筛选高质量数据。
数据集在语言与模态方面保持良好平衡,确保满足任务多样性、答案质量、场景平衡。其中,长推理方面构建了包含300K条样本、覆盖STEM领域的高质量SFT数据集。
RL数据
作者构建了多种任务类型的强化学习数据集,覆盖数学、代码、STEM、指令跟随以及端侧业务等。数据来源于开源数据集以及业务场景,经过去重、质量过滤,总计145K条。
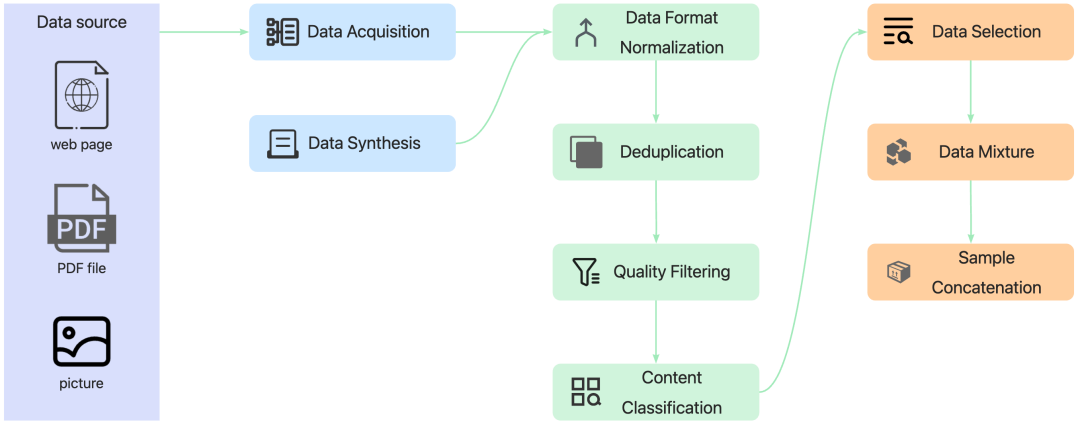
Data Pipeline
作者构建了一套覆盖数据处理全生命周期的自动化 data pipeline,涵盖数据采集、合成、格式转换、质量过滤、去重、分类、筛选、配比、样本构建等关键模块,支持多源异构数据统一接入,具备高度模块化与自动化能力,显著提升了预处理效率与训练数据质量。
高性能训练平台与框架
为支撑模型的高效训练,作者构建了高性能训练平台和训练框架。
训练集群
作者自建了大规模高性能训练集群,在千卡级训练场景实现了超过95%的近线性加速比。依托自研的轩辕分布式存储并通过多级缓存优化IO瓶颈。同时建设了集群稳定性保障体系,训练有效时长超过 99%。
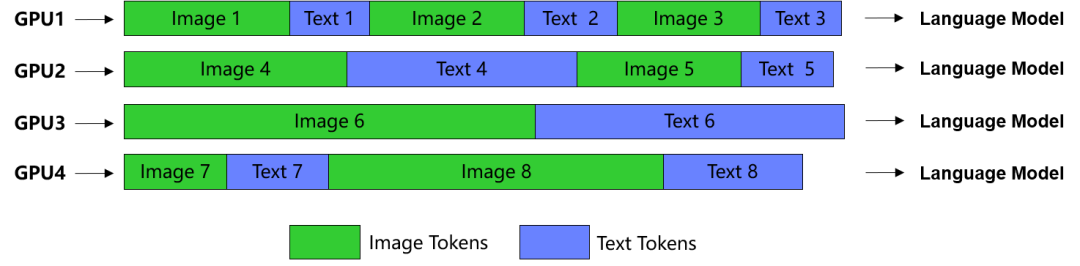
多样本拼接平衡计算负载、提高GPU利用率:
长上下文训练:

vivoLM训练框架
作者基于Megatron-LM,自研了vivoLM训练框架,支持文本和多模态大模型训练,围绕以下四大维度进行了优化:
1)训练性能上,优化图文对拼接策略以均衡每张卡计算的token数量,提升算力利用率。 通过Context Parallelism + CP组内ViT数据并行支持32K长文训练,训练效率是社区方案的1.66倍。全局Batch Size扩至16K,千卡集群加速比达96.8%。
2)架构扩展上,模块化解耦ViT、Adapter与LLM,组件及数据处理策略可即插即用。兼容 Megatron-LM、DeepSpeed 等主流训练框架。
3)稳定性上,完善框架异常处理机制并与训练平台联动,部分故障场景任务可自动恢复。万亿级token数据、千卡级预训练任务100+小时零中断。
4)可观察性上,实现了训练过程的细粒度监控,包括参数、梯度的L2范数、AdamW优化器内部状态等。同时支持了在线评测,实时跟踪模型效果。
RL训练框架
作者基于 veRL进行了定制开发,适配蓝心大模型训练并做了性能优化。
在性能上借鉴 verl-pipeline方案实现了One-Step Asyn RL,并将Ray通信切换为NCCL通信,降低参数更新的通信开销;重写vLLM异步ChatScheduler,动态调度消除 bubble time以最大化推理吞吐。整体训练性能提升了60%。
为了保障训练稳定性,针对RM服务作者自动化部署多实例,并将实例注册到名字服务(VNS),支持训练框架按标识自动发现并调用服务。同时服务可基于QPS 动态弹性伸缩,避免流量变大后请求延迟变高影响RL训练性能。
技术报告: https://arxiv.org/abs/2507.05934
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)