

xAI的Grok 4在ARC-AGI-2测试中拿下15.9%,成为全球最强公开AI模型。

ARC Prize主席Greg Kamradt(@GregKamradt)在推特上详细还原了整个测试过程。
24小时前,xAI团队突然联系ARC Prize,表示想要在ARC-AGI上测试他们的最新模型Grok 4。
Greg Kamradt透露,他们早就听说了相关传闻,知道这个模型会很厉害,但没想到它会直接成为ARC-AGI上的第一名公开模型。
24小时紧急测试
Greg Kamradt(@GregKamradt)详细介绍了测试流程:
昨天,我们与xAI团队的Jimmy进行了交流,他希望我们验证他们的Grok 4分数。他们在ARC-AGI-1和ARC-AGI-2公开评估集上进行了自己的测试。
为了验证分数并测量可能的过拟合问题,ARC Prize团队在半私有评估集上对新模型进行了独立测试。
Greg Kamradt介绍了他们的测试政策:
-
不保留数据 -
模型检查点必须用于公开使用 -
为突发测试临时提高速率限制
xAI团队同意了所有条件,测试随即开始。不过测试过程并不顺利——最初使用普通请求时遇到了超时错误,切换到流式传输后才解决了问题。
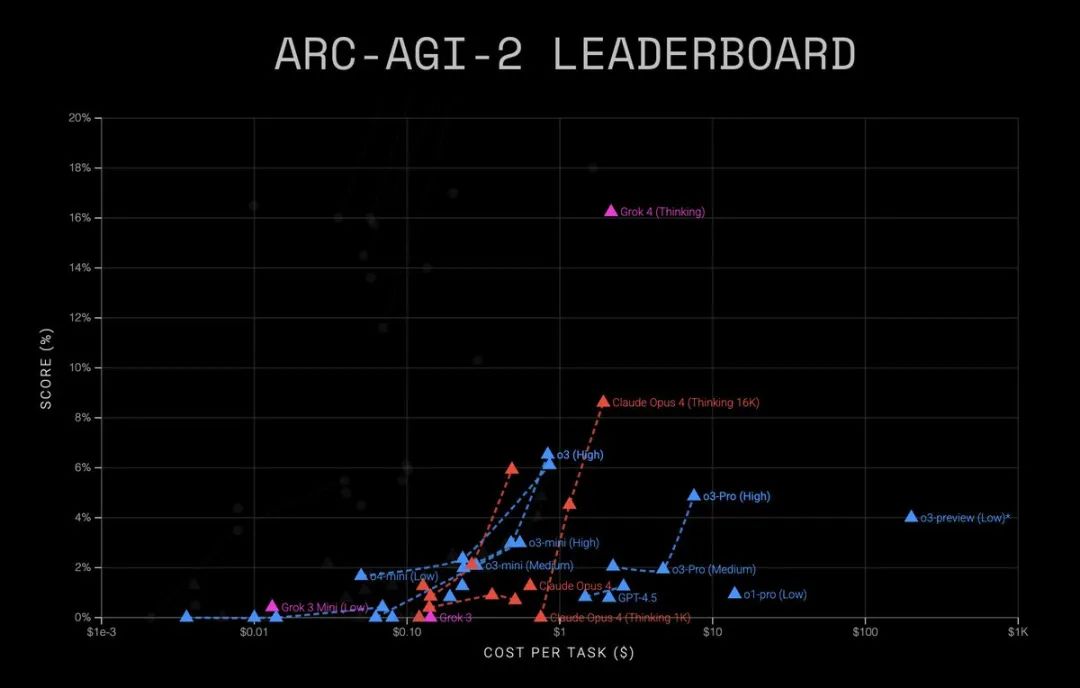
ARC-AGI-2:AI 的终极考验
很多人可能不知道ARC-AGI是什么。
简单来说,ARC-AGI是一个专门测试AI「流体智能」的基准测试。
所谓流体智能,就是从少量训练样例中学习迷你技能,然后在测试时展示这种技能的能力。
在ARC-AGI-2的排行榜上,Grok 4的表现极其亮眼:
-
Grok 4 (Thinking):15.9% -
Claude Opus 4 (Thinking 16K):8.6% -
o3 (High):6.5% -
o4-mini (High):6.1% -
Claude Sonnet 4 (Thinking 16K):5.9%
相比之下,人类在ARC-AGI-2上的表现是100%。
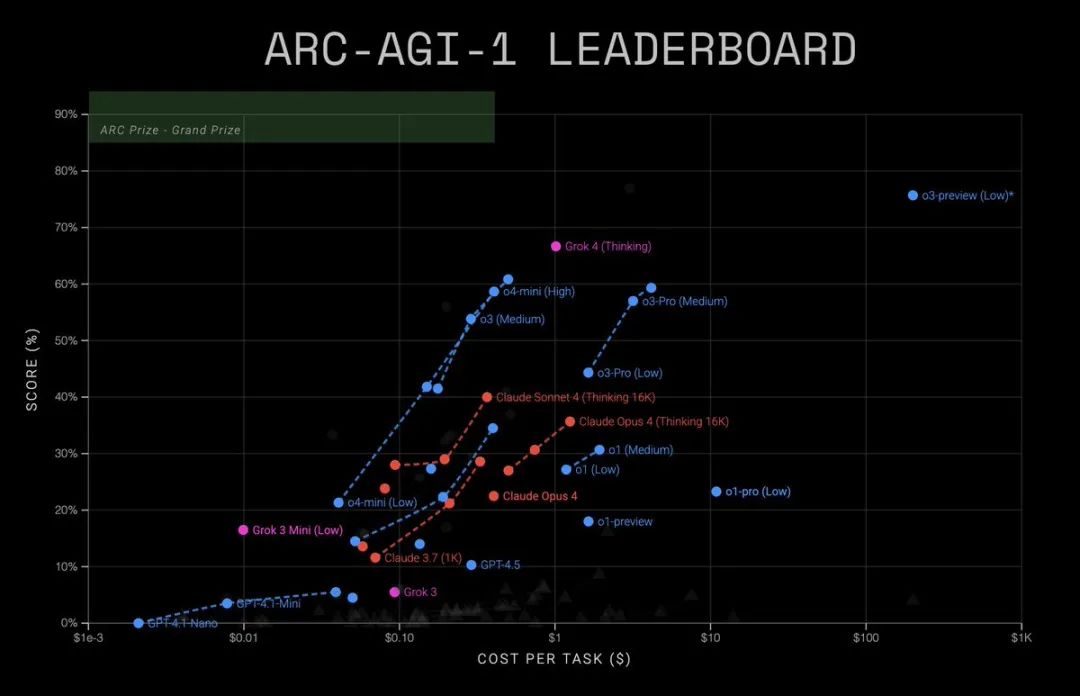
打破噪声屏障
Greg Kamradt特别强调了15.9%这个数字的重要性:
之前的最高分是~8%(由Opus 4创造)。低于10%基本都是噪声。
获得15.9%突破了噪声屏障,Grok 4正在展现非零水平的流体智能。
这意味着,Grok 4不再是简单地匹配模式或记忆答案,而是真正在进行某种形式的「理解」和「推理」。
更令人惊讶的是,这个成绩甚至超过了在Kaggle竞赛中提交的专门构建的解决方案——
那些可都是人类专家精心设计的算法。
网友质疑
面对这个突破性的成绩,社区中也出现了不少质疑声音。
Permaximum Judicium(@permaximum88)提出了尖锐的问题:
好是好,但是:*模型检查点必须用于公开使用。那么为什么所谓的o3-preview仍然在基准测试中?它从未发布,而且在这一点上几乎可以肯定它是为ARC-AGI进行了大量优化的。
为什么你们只给OpenAI这样的特权?
Dhananjay Kajla(@kajla_dhananjay)则从更深层次分析了这个问题,他引用了古德哈特定律:
当一个指标成为目标时,它就不再是一个好的指标。
他进一步解释道:
我们(你、我和ARC)都同意目标是AGI。然而AGI的描述是复杂和主观的。我们能做的最好的事情是取一个AGI实体(比如我们)的一些属性,并测试机器是否具有这些属性。
他用一个简单的例子说明了这个问题:假设目标是制造一台能说出字典中任何单词的机器。如果评估指标是「能否说出’打印机’」,那么新机器的开发者就会特别优化「打印机」这个词,而忽略其他词汇。结果看起来机器变得更智能了,但实际上只是指标变得更糟糕了。
这不是机器变得更好,而是指标变得更差。所以我们会提出新的指标,然后循环继续……
有趣的是,Kuang Xu(@ProfKuangXu)注意到了一个细节:
为什么Gemini系列没有出现在这个图表上?
dacapo(@dacapo_go)则再次关心起开源问题:
这是否意味着grok 4将有开放权重?
写在最后
尽管Grok 4的成绩令人印象深刻,但Greg Kamradt也清醒地指出:
但任务还没有结束。我们需要新的想法来解决ARC-AGI-2。仅靠规模是无法达到目标的。
ARC-AGI-2的难点在于它要求AI系统具备真正的泛化能力:不是记忆大量模式,而是从少量例子中提取规律并应用到全新的问题上。
这正是人类智能的核心特征之一。
目前Grok 4的15.9%虽然是一个突破,但离人类的100%还有巨大差距。
不过,Grok 4的强大不仅体现在ARC-AGI-2上。
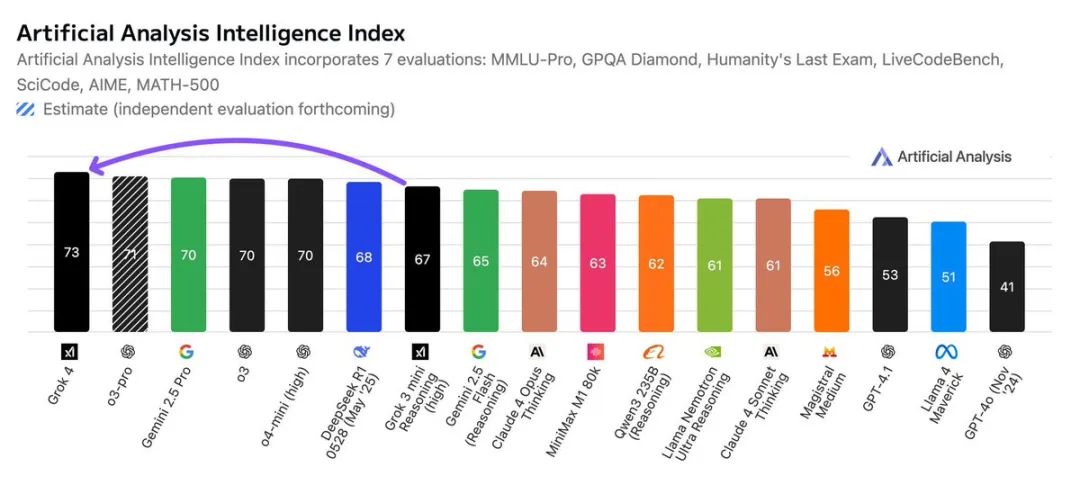
据今天直播中公布的最新数据,Grok 4在多个基准测试中都取得了压倒性的第一:
-
Humanity’s Last Exam(通用难题):44.4%,第二名仅26.9% -
GPQA(研究生难题):88.9%,第二名86.4% -
AIME 2025(数学):100%,第二名98.4% -
Harvard MIT Math:96.7%,第二名82.5% -
USAMO25(数学):61.9%,第二名49.4% -
LiveCodeBench(编程):79.4%,第二名75.8%
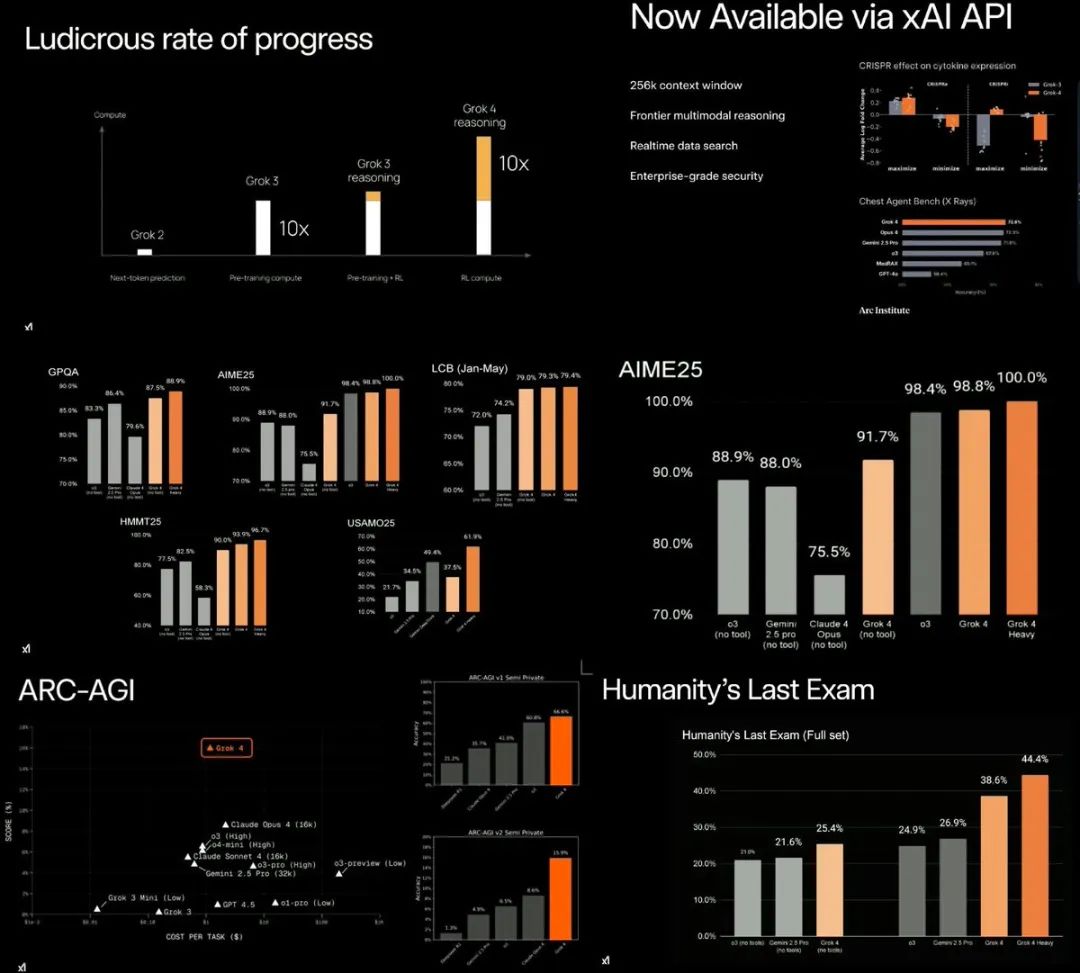
更为重要的是,Grok 4的定价也相当便宜:$3/百万输入token,$15/百万输出token,256k上下文窗口。

Elon Musk(@elonmusk) 在直播结束后也再次表示:
Grok 4已经到了基本上永远不会在数学/物理考试题上出错的地步,除非是精心设计的对抗性问题。
它可以识别问题中的错误或歧义,然后修正问题中的错误或回答歧义问题的每个变体。
并称,Grok 4「在每个学科上都可能比博士水平更好,没有例外」。

最后,来个投票吧:
ARC Prize官网: https://arcprize.org/
[2]ARC-AGI排行榜: https://arcprize.org/leaderboard
[3]AI推理前沿博客文章: https://arcprize.org/blog/which-ai-reasoning-model-is-best
[4]复现结果: ttps://github.com/arcprize/arc-agi-benchmarking
(文:AGI Hunt)