


DreamPRM 由加州大学圣地亚哥分校的研究团队开发,在数学推理权威测评榜MathVista上获得了第一名。第一作者为博士生 Qi Cao,通讯作者为该校副教授 Pengtao Xie,团队其他成员还包括王睿一,Ruiyi Zhang 和 Sai Ashish Somayajula。
使用过程奖励模型(PRM)强化大语言模型的推理能力已在纯文本任务中取得显著成果,但将过程奖励模型扩展至多模态大语言模型(MLLMs)时,面临两大难题:
-
由于多模态输入(图像 + 文本)构成高维连续与离散信号的混合空间,训练数据与测试数据的分布偏移(Distribution Shift)远超纯文本场景,导致一般过程奖励模型泛化能力显著下降。
-
数据集质量失衡。现有开源多模态推理数据集存在大量低价值样本,如冗余模态与低难度问题。若直接用于训练,噪声数据会稀释过程奖励模型对关键推理步骤(如跨模态逻辑衔接)的监督信号。
针对上述问题,我们通过双层优化框架,将数据域权重(Domain Weights)作为可学习参数,动态抑制低质量数据域的影响,同时强化高信息密度数据域(如需要多步跨模态推理的 M3CoT 数据集)的贡献,实现数据质量与覆盖率的理想平衡。

-
论文标题:DreamPRM: Domain-Reweighted Process Reward Model for Multimodal Reasoning
-
论文地址:
https://arxiv.org/abs/2505.20241v2 -
代码地址:
https://github.com/coder-qicao/DreamPRM
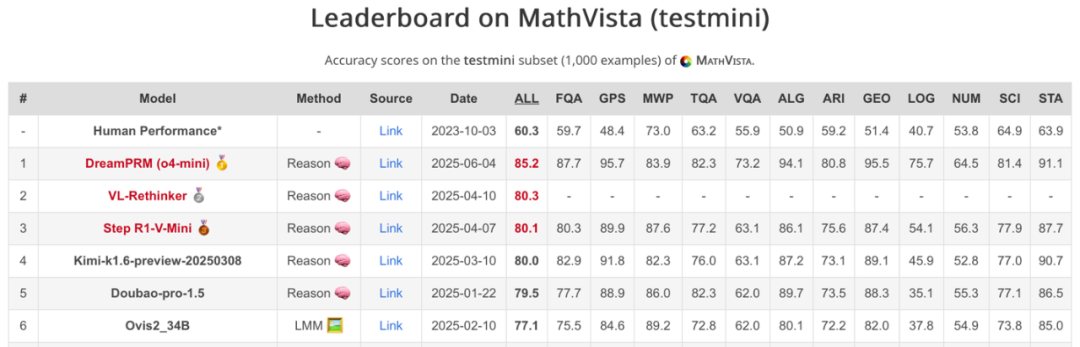
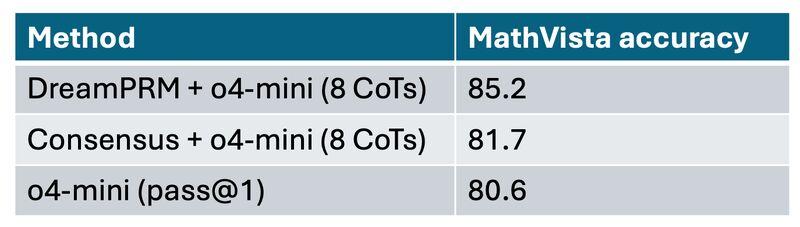
DreamPRM 方法在 MathVista 数学推理排行榜上荣登榜首。DreamPRM 以多层级优化为核心,作为一个与具体大语言模型无关的通用框架,可与任何多模态大语言模型无缝集成,显著提升其数学推理能力。

通过解决数据质量不均衡问题,DreamPRM 大幅提升了多模态过程奖励模型的性能。
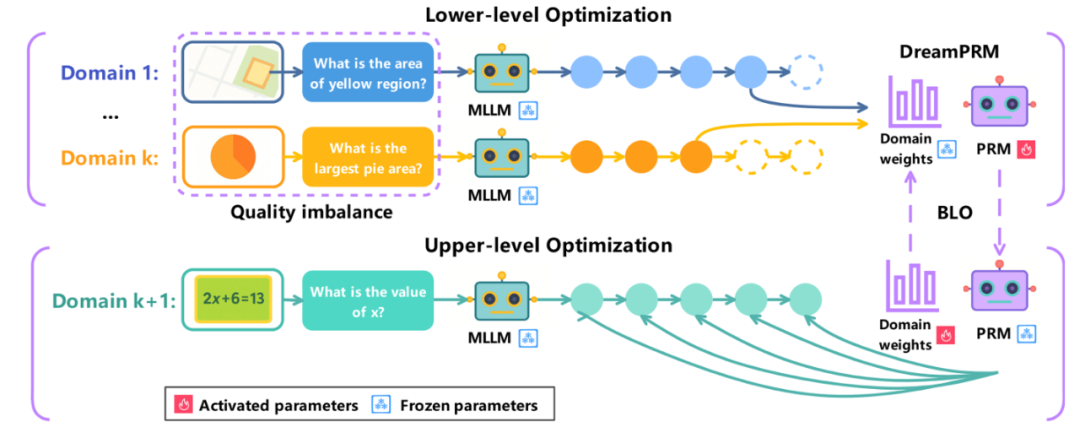
DreamPRM 双层优化框架
技术核心:双层优化机制详解
DreamPRM 的核心创新在于将过程奖励模型的训练过程构建为一个可微分的双层优化问题,通过动态调整数据域权重来解决多模态推理中的分布偏移和质量失衡问题。该框架包含两个紧密耦合的优化阶段,共同驱动模型性能的提升。
在下层优化阶段,系统同时在 15 个多样化训练域上进行 PRM 参数训练。每个数据域(如科学问答、几何推理等)都被赋予一个动态权重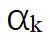 以反映不同数据域对总体损失函数的贡献程度。具体实现中,系统会计算每个域的蒙特卡洛监督信号:
以反映不同数据域对总体损失函数的贡献程度。具体实现中,系统会计算每个域的蒙特卡洛监督信号:
对于给定的中间推理步骤,通过多次采样补全结果并统计正确率,生成对当前步骤质量的概率估计。下层优化使用域加权的过程奖励模型输出与正确率监督的 MSE 损失更新过程奖励模型的参数:
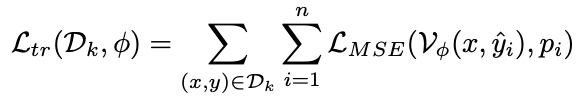
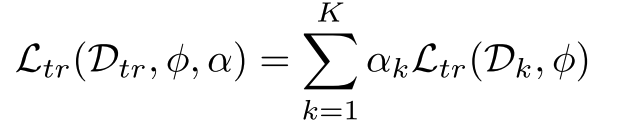
在上层优化阶段,系统使用独立于下层优化训练资料的基于 MMMU 筛选的元数据集作为训练数据。这个精心构建的元数据集覆盖 30 个学科 183 个子领域,能够真实且全面地模拟 PRM 的推理场景以评估其泛化能力。上层优化阶段通过最小化聚合后的过程评价与最终答案准确与否的差异,反向传播误差并更新各个数据域的权重。
这个双层架构创造了一个自适应的正反馈循环:高质量的推理数据域(如需要复杂跨模态推理的 M3CoT)会逐渐获得更高的权重,而包含大量简单样本的域(如 AI2D)的权重则会下降。整个优化过程展现出良好的收敛特性,初始设为 1.0 的域权重会在训练中自然分化,最终形成与数据域信息密度高度相关的权重分布。
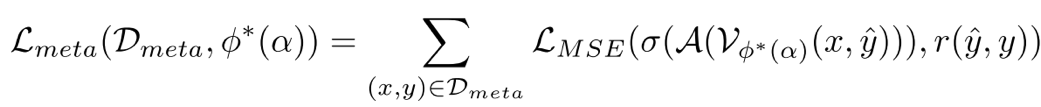
实验结果
主要性能表现
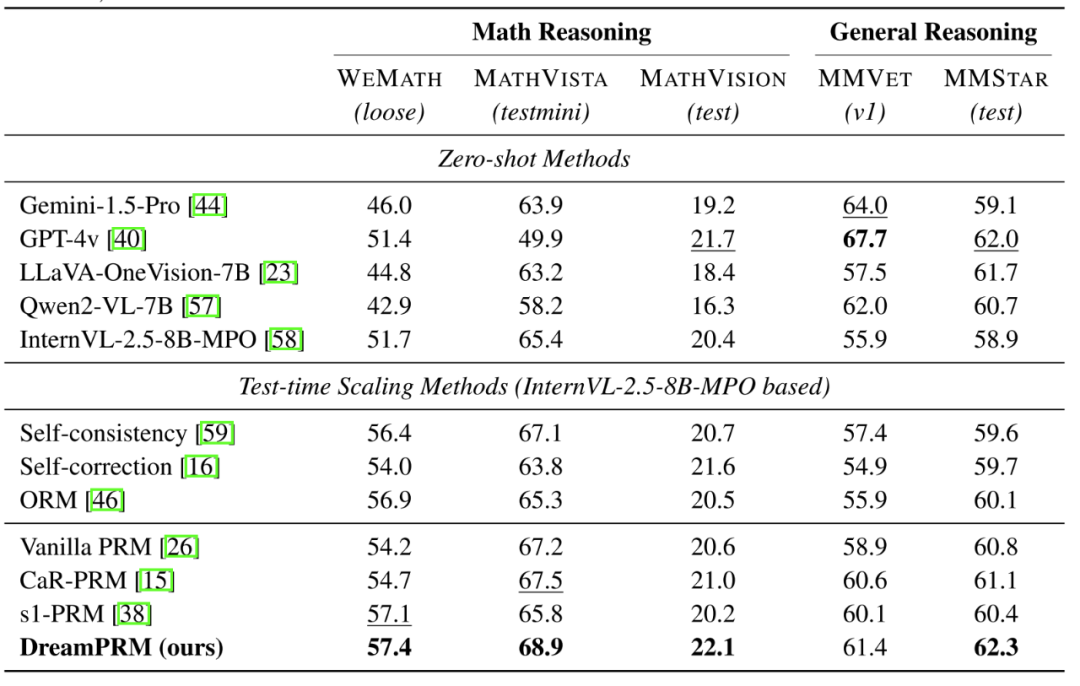
-
领域重加权优势显著:DreamPRM 在所有五项基准测试中稳定超越其他 PRM 方法,相比无数据选择的原始 PRM 提升 2-3%。其自动学习的域权重策略优于人工设计的启发式规则(如 s1-PRM 和 CaR-PRM),证明数据驱动的优化更有效。
-
小模型超越大模型:DreamPRM 使仅 80 亿参数的 InternVL-2.5-8B-MPO 模型在多数基准上表现优于大型闭源模型(如 GPT-4v 和 Gemini-1.5),展现了强大的推理能力提升。
-
细粒度评估带来提升:过程监督模型通过逐步评分机制超越其他测试时优化方法(如自洽性校验),验证了细粒度评估的关键作用。
规模扩展实验
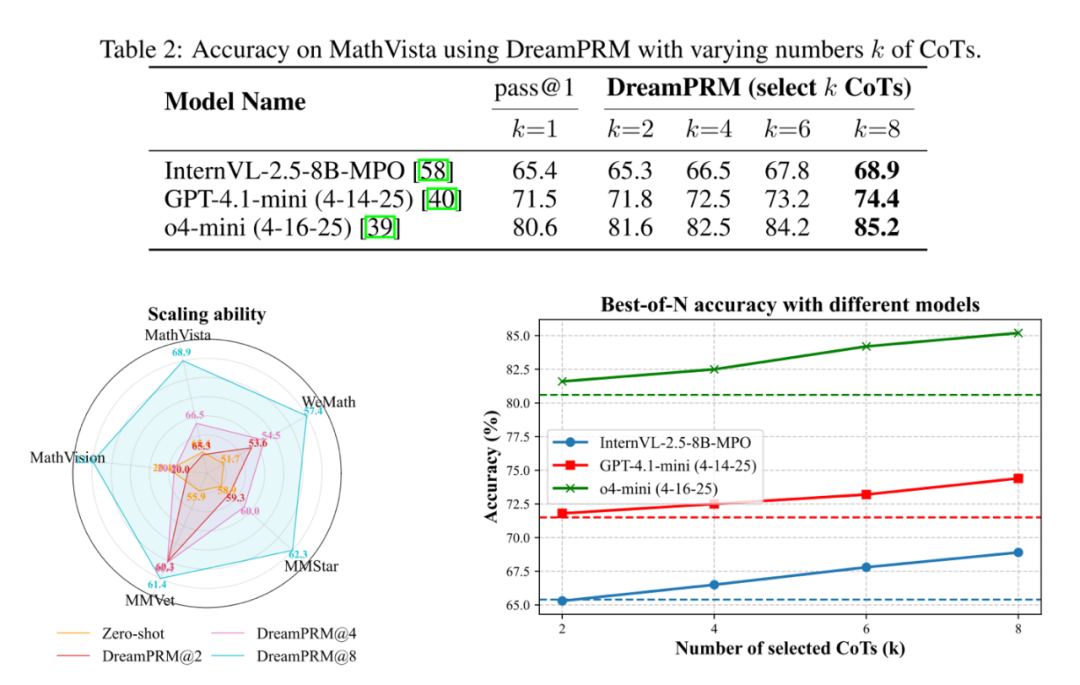
-
DreamPRM 的性能随着候选推理链(CoT)数量的增加而稳定提升。如图所示,当 CoT 数量从 2 条增至 8 条时,DreamPRM 在全部五个基准测试上的准确率均持续提高。
-
DreamPRM 能无缝迁移到更强的多模态大模型上。如图所示,当应用于 GPT-4.1-mini 和 o4-mini 等更强模型时,在 MathVista 基准上的准确率均有提升,充分证明了 DreamPRM 的泛化能力。
学习到的数据域权重
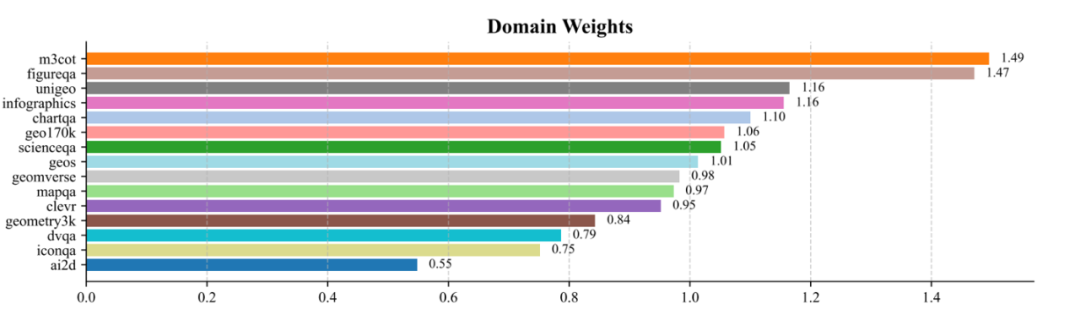
最终学习到的数据域权重范围为 0.55 至 1.49,其中 M3CoT 和 FigureQA 获得最高权重(约 1.5),而 AI2D 和 IconQA 权重较低(小于 0.8)。这种权重分配模式有效提升了 PRM 性能,同时证实了不同数据集间存在显著的质量差异。
总结
DreamPRM 通过创新的双层优化机制,成功解决了多模态过程奖励模型训练中数据质量失衡和分布偏移的难题。双层优化框架自动学习各数据域的最优权重,使 DreamPRM 在五项基准测试中全面超越一般 PRM 方法,尤其在高难度数学推理任务上表现突出。
实验表明,该方法不仅能提升基础模型 4% 的平均性能,还可无缝迁移至 o4-mini 等新模型,且随着候选推理链数量增加持续改善结果。DreamPRM 的细粒度过程监督和可解释的权重分配,为多模态过程奖励模型的高效训练提供了新范式。

©
(文:机器之心)