

今天是2025年7月15日,星期二,北京,阴
我们来继续看agentRAG的进展,看理论跟实现。
从理论上,RAG可能会检索不相关或不准确的信息,并且受外部知识库质量和覆盖范围的限制;推理可以提升模型处理信息、进行逻辑分析以及通过结构化思维过程得出结论的能力,所以两者可以做个结合。那么具体如何结合?我们来回顾两个工作,都有代表性。
落到具体实现上,我们再次回顾下deepresearch项目实现汇总,从技术细节角度拉表对比。
温故而知新,会有所收获。
一、再看RAG与Reasoning结合必要性合跟形式
作为理论层,我们在之前的文章《RAG与Reasoning结合的必要性、实现范式及Agents、RAG产品、大模型安全新总结》(https://mp.weixin.qq.com/s/hsmtO-Ef8Wu8rfz2j80MZg)中有过介绍,工作 《Synergizing RAG and Reasoning: A Systematic Review》(https://arxiv.org/abs/2504.15909),探讨了检索增强生成(RAG)与推理能力结合的一些具体内容,我们来看两个点,一个是结合必要性,一个是结合范式,内容很多,新的概念也不少,可以作为科普读物。
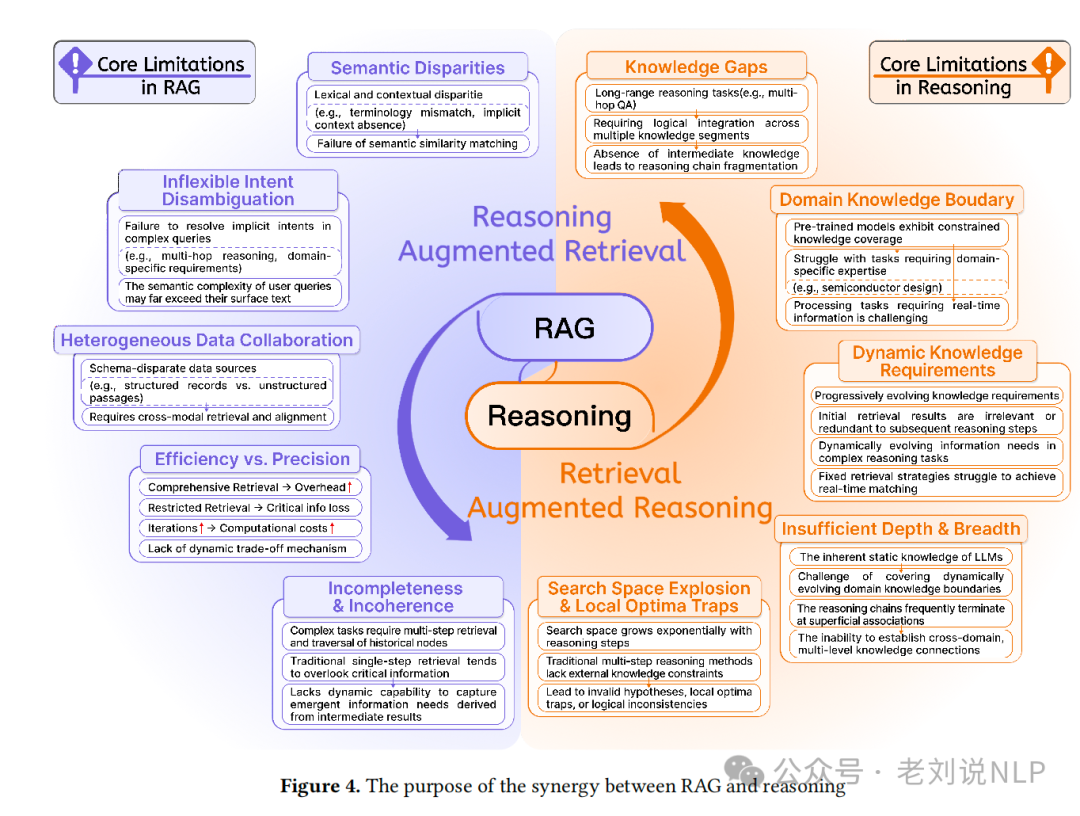
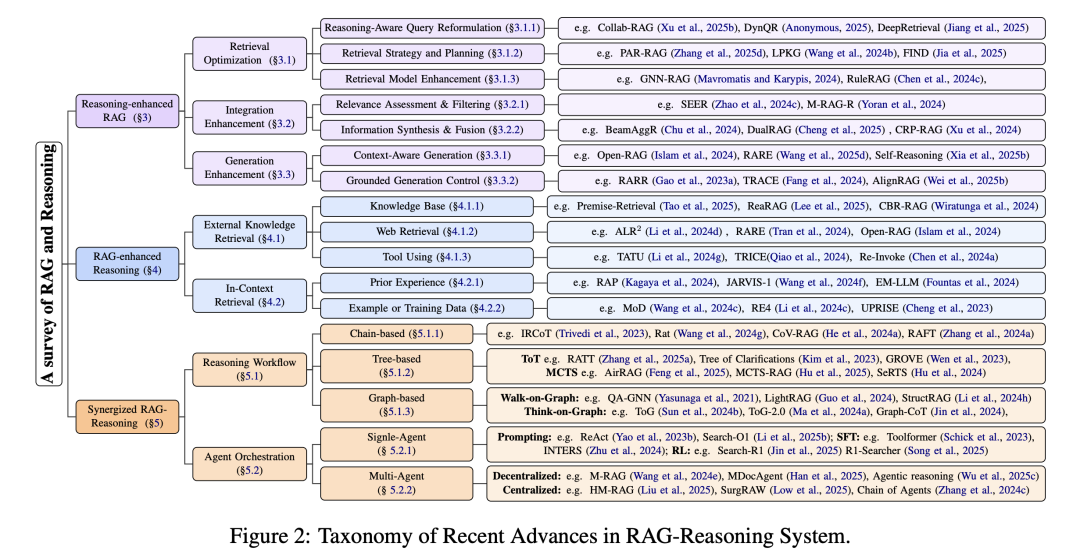
三个月后,很类似的工作又来了一个,《Towards Agentic RAG with Deep Reasoning: A Survey of RAG-Reasoning Systems in LLMs》(https://arxiv.org/pdf/2507.09477),https://github.com/DavidZWZ/Awesome-RAG-Reasoning。
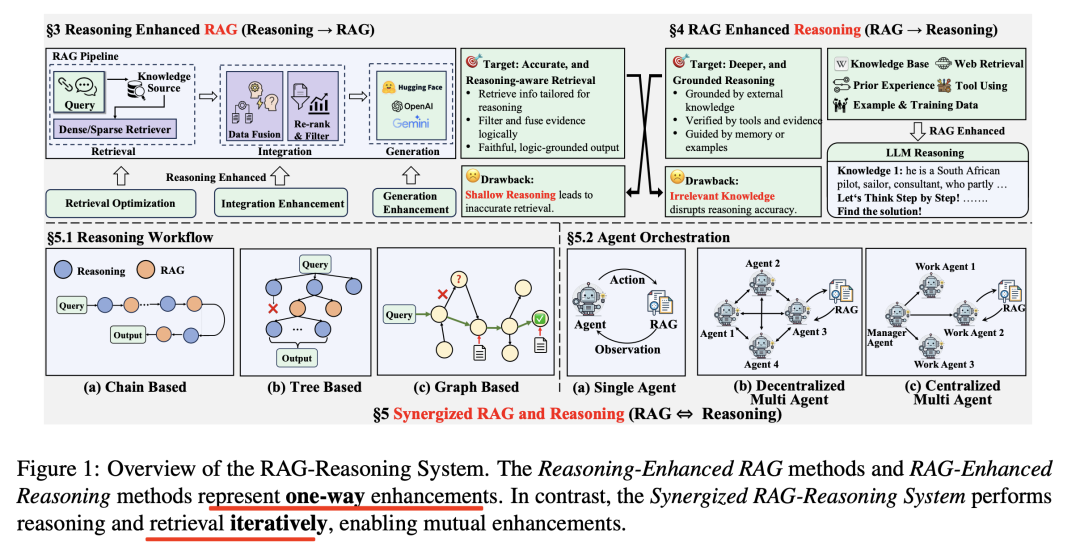
核心就三种:
1、推理增强的RAG(Reasoning-Enhanced RAG),通过在RAG的检索、整合和生成阶段集成推理能力,系统可以识别和获取最相关的信息,减少幻觉并提高响应准确性。
2、RAG增强的推理(RAG-Enhanced Reasoning),在推理过程中集成外部知识或上下文知识,帮助LLMs减少幻觉并弥合逻辑差距。
3、协同RAG-推理(Synergized RAG-Reasoning),通过多步迭代的方式进行推理,主要包括推理工作流和代理编排两种方法。
二、18个Deepresearch项目实现技术对比
当前已有许多系统,实际上,我们在之前的文章《Deep Research现有方案技术总结:实现架构、特点对比、现存问题及未来方向》(https://mp.weixin.qq.com/s/7TqX0zi8aI-jByetRIISJg)中,介绍了《A Comprehensive Survey of Deep Research: Systems, Methodologies, and Applications》,https://arxiv.org/pdf/2506.12594,https://github.com/scienceaix/deepresearch,分析了自2023年以来涌现的80多个商业和非商业实现,包括OpenAI/DeepResearch、Gemini/DeepResearch、Perplexity/DeepResearch 以及众多开源替代方案,如dzhng/deepresearch、HKUDS/Auto-Deep-Research等开源实现。
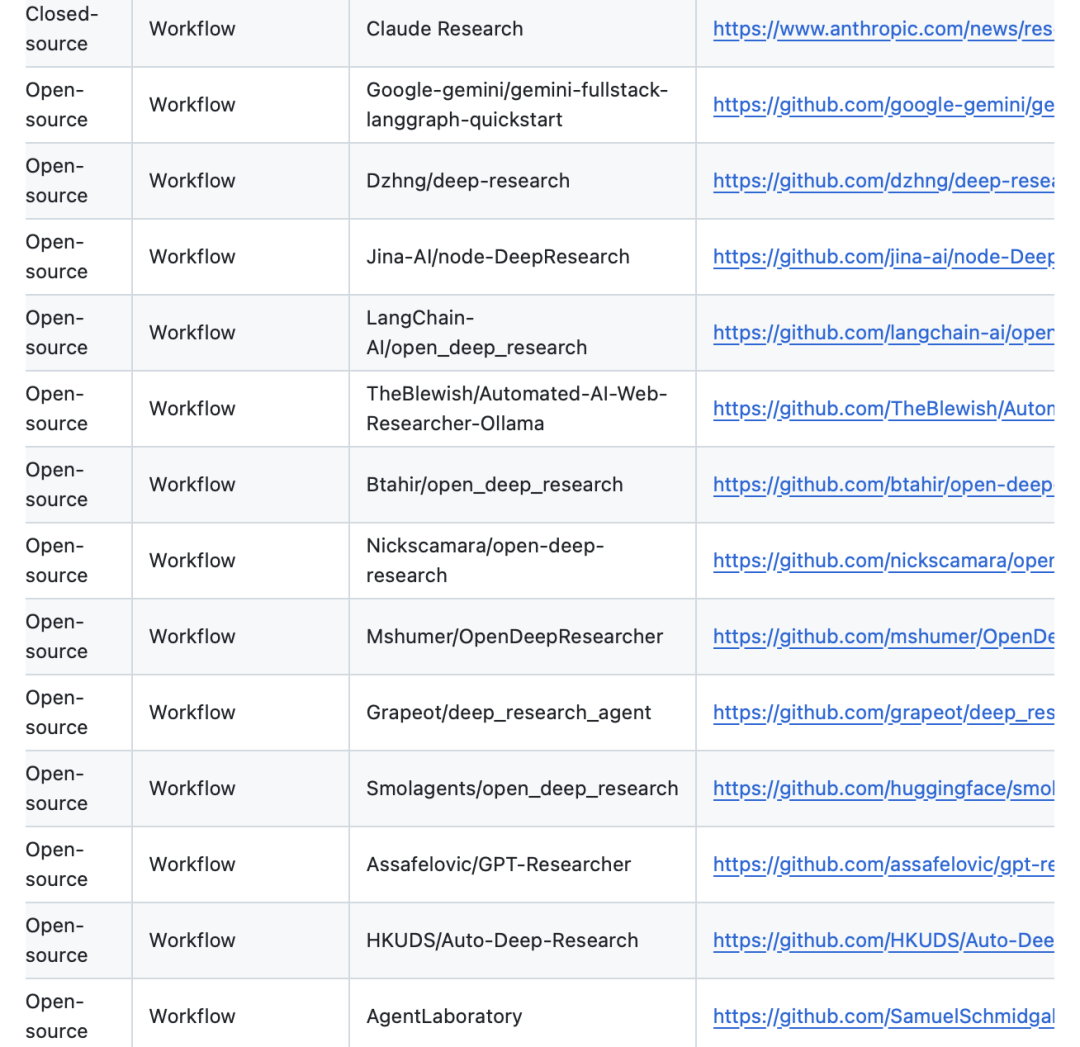
我们可以再次温故而知新,从技术细节角度再看下,如下图所示,可以找到一些信息,包括基座模型、优化策略、奖励函数、检索方式等对比项,这个可以帮助我们做选型:
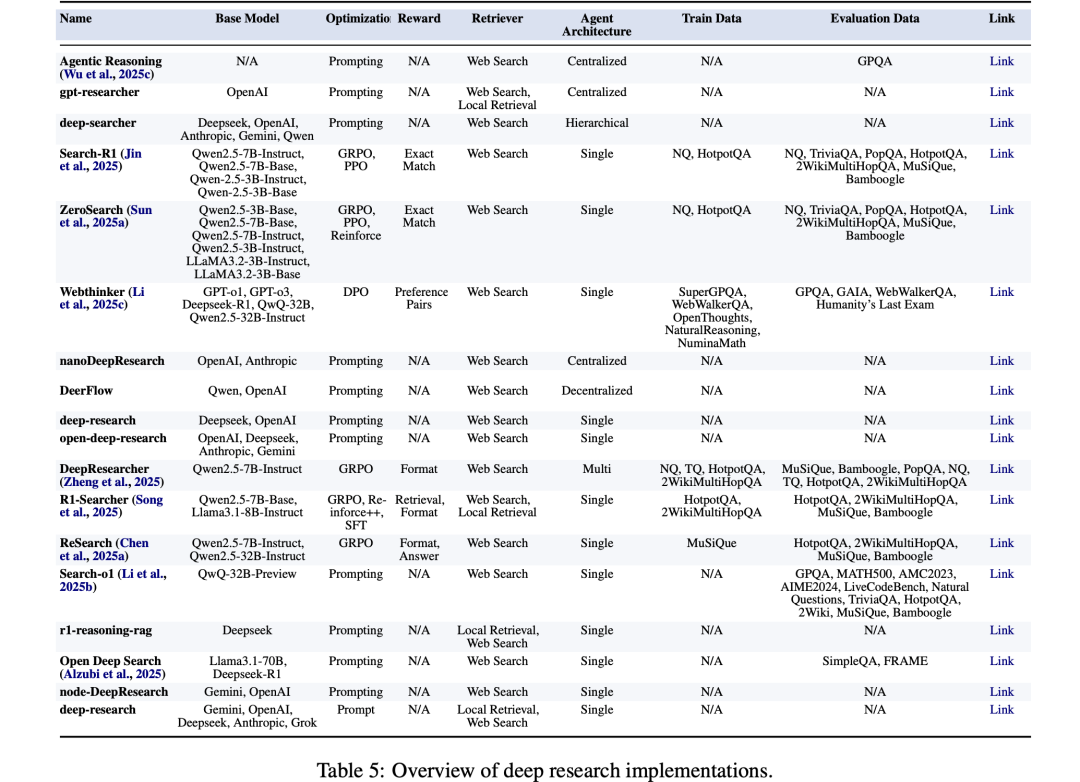
包括:
1、Agentic Reasoning:https://github.com/theworldofagents/Agentic-Reasoning,推理方式采用Prompting;
2、gpt-researcher:https://github.com/assafelovic/gpt-researcher,模型基座采用OpenAI,推理方式采用Prompting;
3、deep-searcher:https://github.com/zilliztech/deep-searcher,模型基座采用Deepseek, OpenAI,Anthropic, Gemini, Qwen;
4、Search-R1:https://github.com/PeterGriffinJin/Search-R1,模型基座采用Qwen2.5-7B-Instruct,Qwen2.5-7B-Base,Qwen-2.5-3B-Instruct,Qwen-2.5-3B-Base,模型优化采用GRPO,PPO;
5、ZeroSearch:https://github.com/Alibaba-NLP/ZeroSearch,模型基座采用Qwen2.5-3B-Base,Qwen2.5-7B-Base, Qwen2.5-7B-Instruct,Qwen2.5-3B-Instruct,LLaMA3.2-3B-Instruct,LLaMA3.2-3B-Base,模型优化采用GRPO,PPO,Reinforce
6、Webthinker:https://github.com/RUC-NLPIR/WebThinker,模型基座采用GPT-o1, GPT-o3,Deepseek-R1, QwQ-32B,Qwen2.5-32B-Instruct,模型优化采用DPO;
7、nanoDeepResearch:https://github.com/liyuan24/nanoDeepResearch;模型基座采用OpenAI, Anthropic;优化策略采用Prompting;
8、DeerFlow:https://github.com/bytedance/deer-flow,模型基座采用Qwen, OpenAI,优化策略采用Prompting;
9、deep-research:https://github.com/dzhng/deep-research,模型基座采用Deepseek, OpenAI,优化策略采用Prompting;
10、open-deep-research:https://github.com/btahir/open-deep-research,模型基座采用OpenAI, Deepseek, Anthropic, Gemini,优化策略采用Prompting;
11、DeepResearcher:https://github.com/GAIR-NLP/DeepResearcher,模型基座采用Qwen2.5-7B-Instruct,优化策略采用GRPO;
12、R1-Searcher:https://github.com/RUCAIBox/R1-Searcher,模型基座采用Qwen2.5-7B-Base, Llama3.1-8B-Instruc,优化策略采用GRPO, Reinforce++,SFT
13、ReSearch:https://github.com/Agent-RL/ReSearch,模型基座采用Qwen2.5-7B-Instruct,Qwen2.5-32B-Instruct,优化策略采用GRPO;
14、Search-o1:https://github.com/Agent-RL/ReSearch,模型基座基于QwQ-32B-Preview,优化策略采用Prompting;
15、r1-reasoning-rag:https://github.com/deansaco/r1-reasoning-rag,基座采用Deepseek,Prompting;
16、Open Deep Search:https://github.com/sentient-agi/OpenDeepSearch,基座采用Llama3.1-70B、Deepseek-R1,基于Prompting;
17、node-DeepResearch:https://github.com/jina-ai/node-DeepResearch,基座采用Gemini, OpenAI,推理基于Prompting;
18、deep-research:https://github.com/u14app/deep-research,基座采用Gemini, OpenAI,Deepseek, Anthropic, Grok,推理基于Prompt;
参考文献
1、https://mp.weixin.qq.com/s/hsmtO-Ef8Wu8rfz2j80MZg
2、https://github.com/scienceaix/deepresearch
(文:老刘说NLP)