


月之暗面发布基模 Kimi-K2,这是全球首个万亿参数且直接开源的 Agentic Model。这也是继 Researcher 之后,Kimi 再次明牌其 “Model as Agent” 的路线,成功地向全世界宣告了 Kimi Back。
而“模型即 Agent”究竟意味着什么?从中又有什么值得我们了解的呢?
为 Agent 而诞生的特工宇宙,本次将与你一起,随 Kimi-K2 进入 “The Second Half”(AI 下半场)。
✍️ 特脑风暴:Agentic Model 是什么?和先前的 Foundation Model 以及 Reasoning Model 区别是什么?
Agentic Model 不只是知识和推理的载体,更是会自主调用工具与环境交互,并根据反馈循环持续学习的智能主体。
-
Foundation Model(基础模型)
-
定位:知识的容器,工作方式:接收输入→检索知识→生成输出
-
局限:只能“说”不能“做”,缺乏与世界的实际交互
-
Reasoning Model(推理模型)
-
定位:思考的大脑,工作方式:分析问题→推理步骤→得出结论
-
局限:虽能深度思考,但仍停留在“纸上谈兵”阶段
-
Agentic Model
-
定位:行动的主体,工作方式:理解意图→制定计划→执行行动→感知反馈→调整策略→积累经验
-
核心价值:将知识和推理转化为实际行动,并从经验中持续进化
-
突破:实现从“知道”→“做到”→“学到”的跃迁


全网评测一览:Kimi K2 面对质疑依然抗打
刚过一个周末,K2 就受到了众多硅谷AI博主与海外权威平台的认可与转发,随之各类测评频出。
美国财经媒体 CNBC:单独撰写 Kimi 专栏,直接将其对标 ChatGPT 与 Claude:
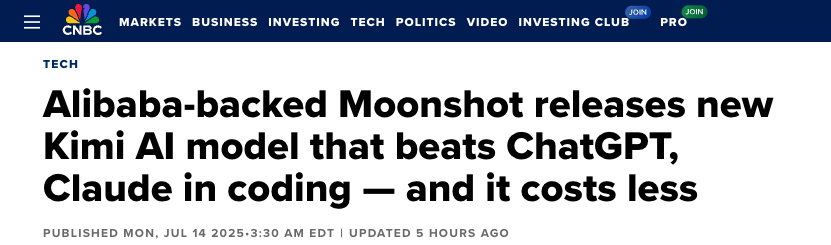
且目前 Kimi K2 已经被 Cline、VSCode 等主流 IDE 集成,据说国内各大 AI Coding 厂商也在积极接入中…
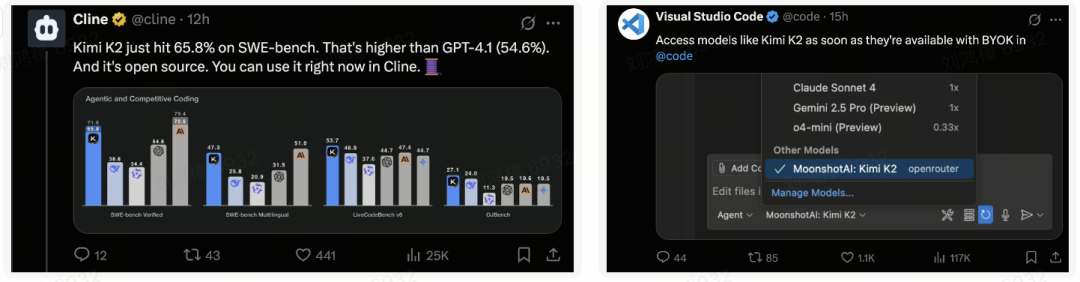
测评一览:
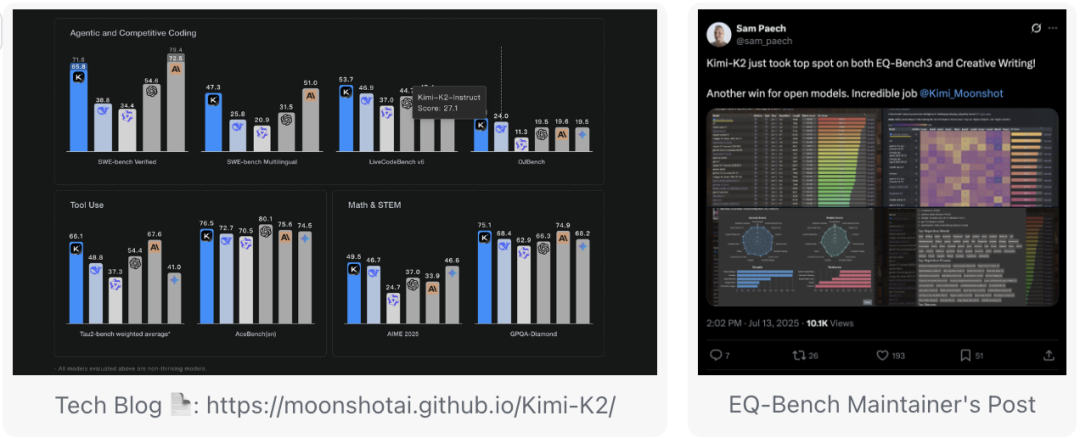
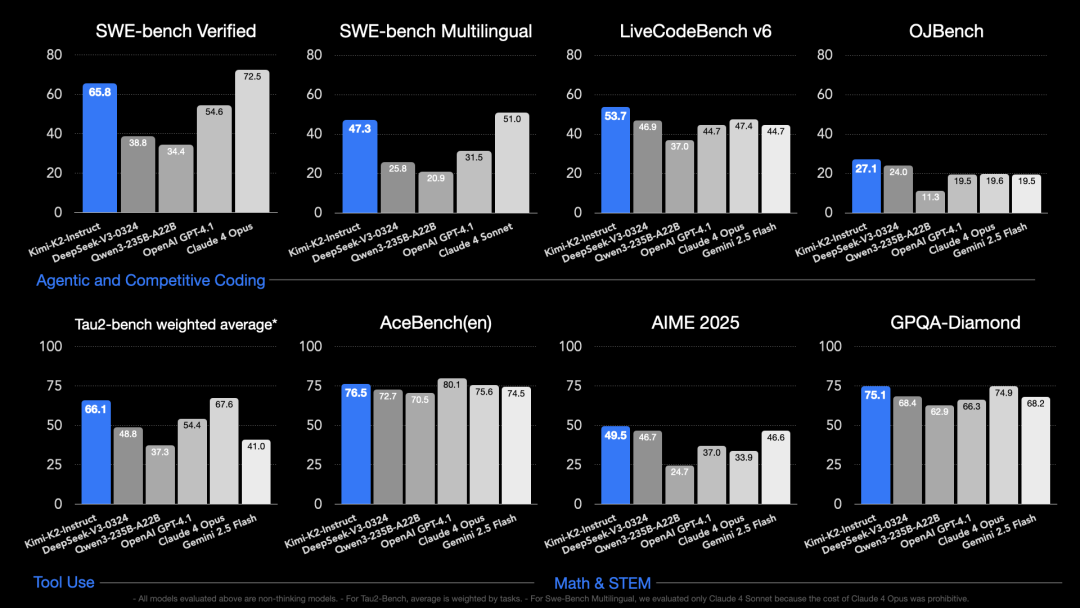
在 Kimi 的技术博客中,K2 在经典权威的自主编程、工具调用和数学推理等 AI Benchmark 中,表现出色,达到了开源模型的 SOTA。
令人惊喜的是,Kimi-K2 同时在第三方的 EQ-Bench(情感智能)及 Creative Writing 评测中也荣登榜首之位,超越了 GPT‑o3、Claude-opus-4和 Gemini-2.5-pro 等一众顶级海外模型。属实可鉴 K2 泛化的文武双全。
除了公允的分数指标外,我们还节选了一些 test case,供大家直观感受 Kimi-K2 的 Agentic 能力:

Case 1. 模拟小行星撞击地球:
Prompt: “make a website that shows 3D Simulation of Asteroids hitting Earth in html”
@chetasluaTwitter 用户通过一句非常简单的提示词,让 Kimi K2 完成了一个 3D 小行星撞击地球的模拟网页。
Link: https://x.com/chetaslua/status/1943668652315758951
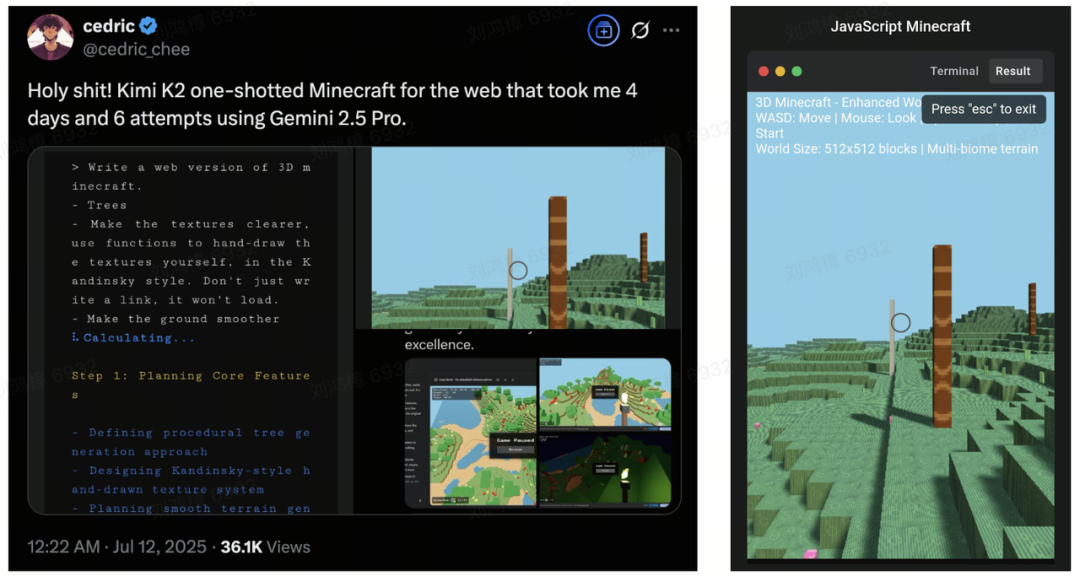
Case 2. 搭建《我的世界》:
Prompt:”Write a web version of 3D Minecraft.
– Trees
– Make the textures clearer, use functions to hand-draw the textures yourself, in the Kandinsky style. Don’t just write a link, it won’t load.
– Make the ground smoother”
@cedric_chee 让 Kimi K2 一次性成功创建了网页版 3D Minecraft 游戏。相比之下,同样的任务使用 Gemini 2.5 Pro 则花费了用户 4 天时间和 6 次尝试才成功。
Link: https://x.com/cedric_chee/status/1943707506343035345
Case 3. 搭建宝可梦炉石:
小红书博主@严肃文学教父通过 K2+Trae 的跑出的“宝可梦炉石”。
博主评价:“很丝滑,快来召唤 10 费超梦吧”。
目前 Kimi K2 作为 non-thinking model,只需简单接上工具,就足以让人体验与众不同的“智能感”。
(听 Kimi 的同学说,他们已经成功让 K2 自己写 MCP 连接上公司门前钢琴,并自动奏响了《欢乐颂》🥳)
而当基础模型能像 K2 这般端到端地完成复杂的 Agentic 任务,我们将见证 AI 玩家们的第一目标从“更高分数追求” 向 “实现价值创造” 的根本性转变,正式进入“下半场”。

随 Kimi-K2 到 Second-Half,进入“经验时代”
当 AI 模型在各项基准测试上测出惊人高分后,一个更深刻的问题浮出水面:我们该如何衡量模型真正的价值,何为真正的智能, AGI 之路在何方?
在这个转折点上,两套极具前瞻性的概念或许已为我们指明了方向:“AI下半场”(The The Second Half)与“经验时代”(Welcome to Era of Experience)。
✍️ 特工帮你问:AI 圈常热议的“下半场” 和 “经验时代”到底是什么?
-
AI 下半场(Second Half),由 OpenAI 研究员姚顺雨提出,相比测评分数应更重视模型的实际效用:
-
强化学习三要素:“先验知识”、“环境”、“算法”。
-
对于语言模型而言,“先验”(priors)往往比环境与算法更实用
-
基模对模型的实际效用与 RL 泛化等能力上限有着决定性作用
-
经验时代(Era of Experience),由 DeepMind 首席研究员 David Silver 与图灵奖得主 Richard S. Sutton 联合提出,未来 Agent 的自进化范式:
-
要让 Agent 取得持续的进步,就必须摆脱对人造静态数据集的依赖
-
Agent需要成为一个探索者,主动与环境交互并积累反馈及经验,从自身的经验流中持续学习
站在这两大思想的交汇处,Kimi-K2 模型应运而生——它并非对这些理论的简单复刻,而是将其创造性地融合出统一的技术框架,成为了 AI “下半场”与 Agent “经验时代”交界的里程碑。
月之 Pre-training:MuonClip 打破“预训练终结”魔咒
随着 OpenAI 前首席科学家 Ilya Sutskever 果断离开 OpenAI 并断言了“预训练时代终结”后,不少团队都放弃了大规模 Pre-training 以及 AGI 的探索。
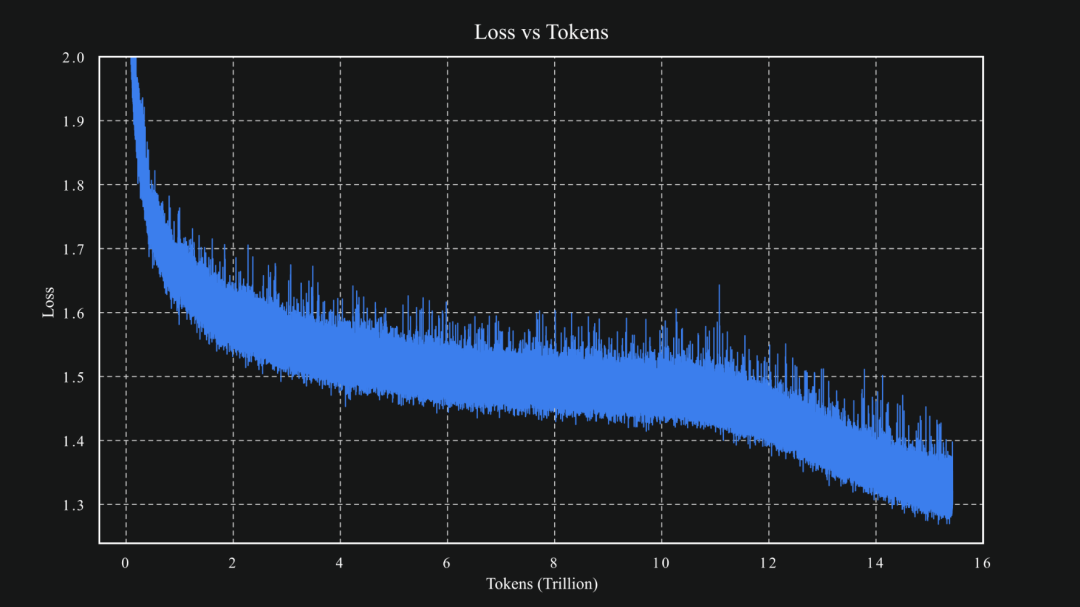
而 Kimi 始终坚信着“先验知识”的重要性: 在坚定将sclaing law发挥到极致的同时,通过自发创新的 MuonClip 优化器,通过自发创新 MuonClip 提出 qk-clip,使得让 Kimi-K2 在高达 15.5T Tokens 的巨量数据上实现了训练稳定性。
而这也让 Kimi 交出了让 AI 业界出乎意料的的答卷:高效地将各类数据转化为模型的内在知识,成功构建了独一无二的先验知识库,为后续的 Agentic 能力的泛化打下了扎实的基础。
月之 Post-training:Multi-Agent 践行 “经验时代”飞轮
为了推进 Foundation Model 向 Agentic Model 蜕变,Kimi 构建了一个通用的多智能体数据构造管线,相当于一个自主协作运转的“经验数据工厂”,大规模地仿真出各种工具的使用场景:
1. 场景设计:按照用户需求与领域划分,自主设计出成千上万种工具(真实 MCP + 合成工具),及其复杂多变的使用场景。
2. 交互生成:另一部分智能体(下图虚线框里的内容)则扮演“用户”或“执行者”,围绕这些场景,在模拟环境中生成复杂的交互轨迹。这些轨迹不是简单的“输入-输出”,而是充满了自主探索、工具编排、环境反馈,甚至策略更迭的完整闭环。
3. 高质筛选:造出的“经验数据”会经过一套全面的 rubric 和 judge model 的测评,确保其多样性和逻辑深度,为模型提供了一个完美且可无限扩展的“经验”池。
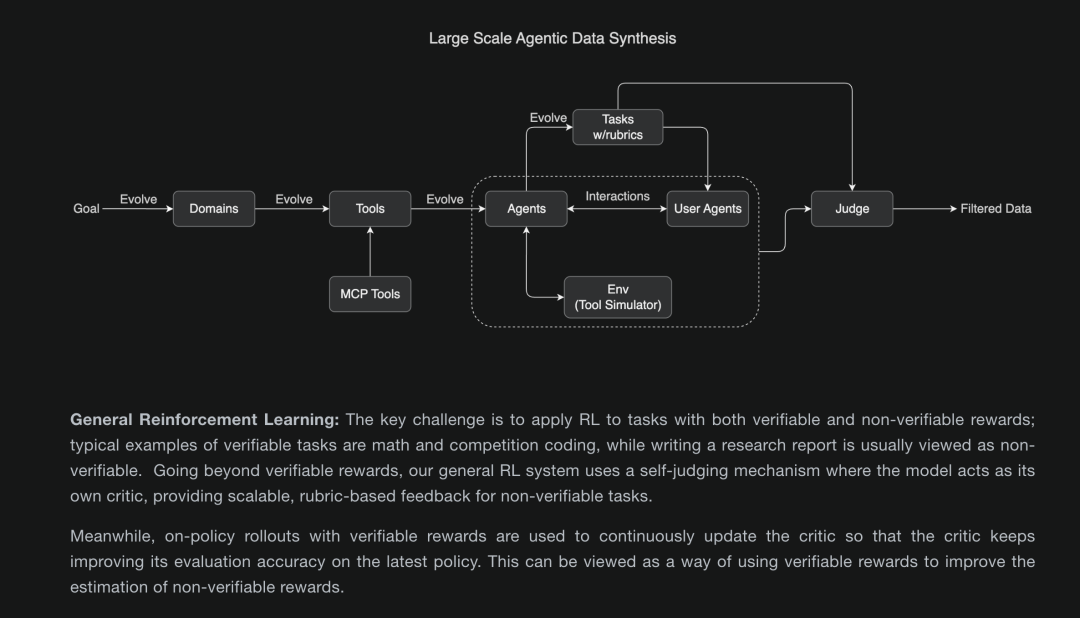
为了让模型能从各种经验中学到“精髓”,Kimi‑K2 还引入了一个通用强化学习框架:
-
Self‑judging 机制:针对开放式、无法直接验证的任务(如创意写作),让模型充当自己的评价者,根据预设的评分标准为输出结果打分并反馈。
-
On‑policy 校准:在可验证的任务(如编程)上,持续地使用当前策略进行 rollouts,收集客观奖励信号,并用这些真实奖励不断更新和校准评价者,使其对新策略的评价更精准。
这样,就等于是“用可验证奖励来改进对不可验证任务评估的能力”,实现跨所有任务域的持续自我改进——类似一种特殊形式的多任务联合学习。
值得一提的是:
其后训练的目的,不仅是给的模型教学新技能,而是去“唤醒”模型在海量预训练数据中潜藏深处的工具能力——其中无数的 API 调用代码、库函数文档和命令行脚本,本身就都是关于“如何使用工具”的隐性知识。
这种激活方法的奏效,也再次印证了“下半场”的观点:真正强大的能力,根植于深厚的“先验知识”之中。
此外,Kimi 还将这些探索成果开源给了全世界——这体现了对自身技术的信心,更是对 AGI 理念的坚持。

首个对标 Claude 4 的国产 Agentic Model,对我们意味着什么?
过去,“Build with Claude” 几乎一直是 AI 应用开发的唯一选择。尤其自 Claude 3.7 大幅提升了 MCP 与工具调用能力之后,从 Windsurf 到 Manus,全球范围内的各种 AI 产品层出不穷。
但 Agent 盛世之下,我们似乎忘却了:任何基于 Claude 等国外模型驱动的 AI 应用,出于数据隐私等考虑,很难在国内大规模应用。而日新月异的 AI 时代,这一直是我们每位中国 AI 开发者面临的挑战。
而前几天 Manus 突然大规模裁员且彻底撤出中国,也时刻警醒着我们:由于缺一个 Agentic 能力对齐 Claude 的国产模型,国内几乎无法用到任何好的 AI 产品。而且,Windsurf 被 Claude 断供后分家拆卖的现状,也间接揭示了依赖国外闭源模型的风险。
终于等到的是,Kimi-K2 努力赶上了 Claude 4 的 SWE 能力,给了我们中国开发者真正的自主权。相信不久后,各式各样的 AI 产品也终将在国内百花齐放。
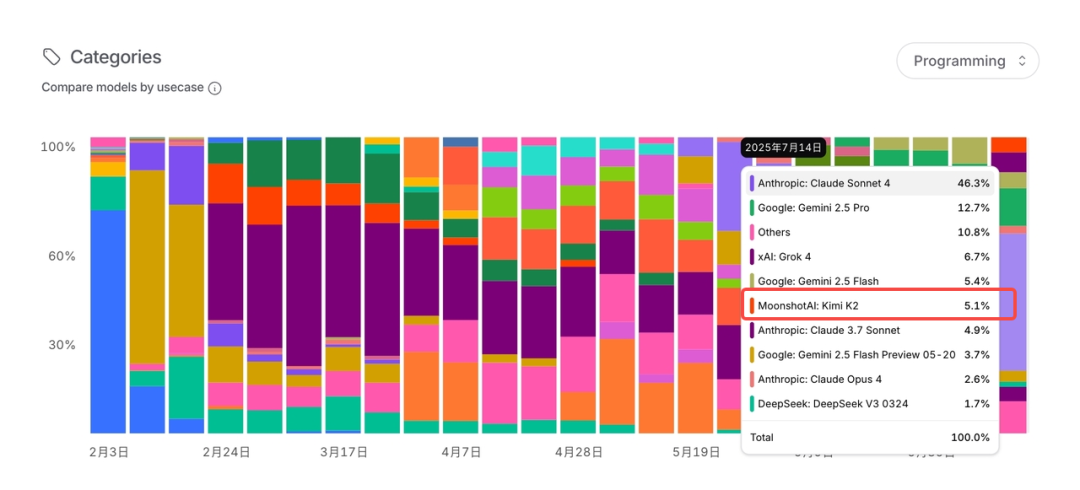
最新消息:Kimi-K2 在 OpenRouter 的 Programming 场景,已荣获开源模型调用量第一
当然,出色的工具理解与使用只是“模型即 Agent”开始——随着从 Foundation Model → Agentic Model 日渐成熟,模型对 MCP 的认知也会越来越深。
或许在不久后,Agentic Model 在解决用户的复杂需求时,就真的可以在实时环境中寻求反馈,再自主编写出 MCP ,甚至为自己(Master-Agent)生成出有更多意义的 Sub-Agents 来辅助完成任务…… 可预见的未来,我们或将不再人工编排的workflow,Agentic Intelligence is all we need!

尽管 K2 还有很多值得提升的地方,官网各种的 mcp 也还在路上。
但根据我本地的几十次实测,Kimi 已经完全能给予我这样的期待了。也许那时,Agent 的 Era of Experience 就真的到来了吧。
但在此之前,最重要的依然是探索智能本身,从底层出发,自下而上地推动范式重构——这条路任重道远,但值得期待。
Kimi-K2: Open Agentic Intelligence 技术博客 🔗:https://moonshotai.github.io/Kimi-K2/





(文:特工宇宙)