
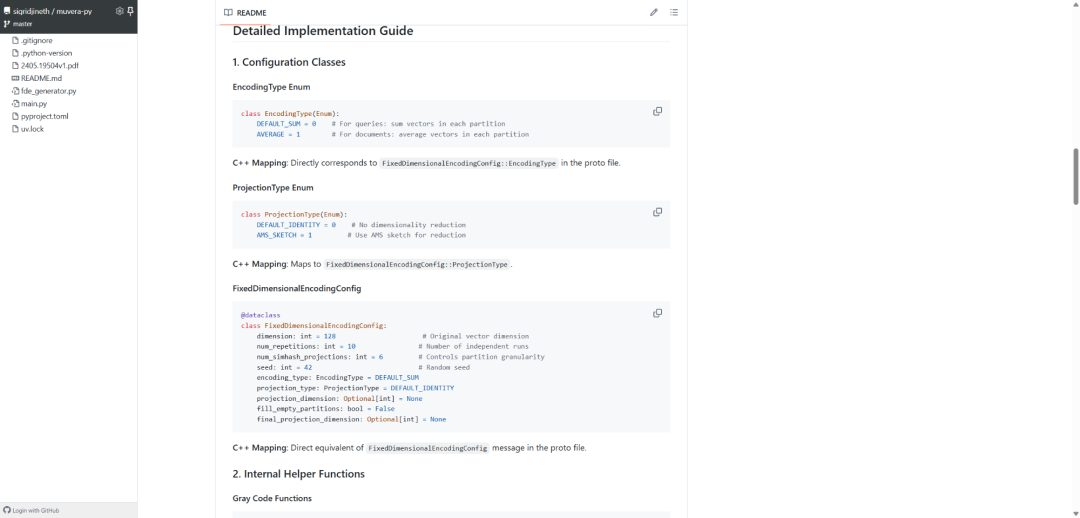
GitHub 上一个高效的多向量检索算法:MUVERA-PY,实现在海量文档中搜索又快有准。基于谷歌 FDE 算法的 Python 实现,通过固定维度编码技术将数百个向量压缩为单个向量,检索速度提升 8 倍以上。主要特性:
-
完全兼容 Google 原始 C++ 实现,保持算法准确性 -
支持 ColBERT 等主流多向量检索模型 -
提供查询和文档两种 FDE 生成模式 -
支持 AMS Sketch 等降维技术优化性能 -
包含完整的评估基准和性能测试
提供详细的算法实现指南和性能测试代码,可直接用于生产环境的搜索系统优化。
参考文献:
[1] GitHub:https://github.com/sigridjineth/muvera-py
[2] https://github.com/google/graph-mining/tree/main/sketching/point_cloud
知识星球:Dify源码剖析及答疑,Dify扩展系统源码,AI书籍课程|AI报告论文,公众号付费资料。加微信buxingtianxia21进NLP工程化资料群,以及Dify交流群。
(文:NLP工程化)