


在检索增强生成(RAG)成为提升大语言模型知识能力的重要范式的当下,图结构 RAG 被广泛认为是支持多跳推理与深层理解的关键路径。
然而,现有的 Graph-RAG 方法普遍建立在静态语料假设之上,一旦面对持续增长的知识库,其图结构往往难以维护,更新代价高昂,严重限制了在真实场景中的应用落地。
这一静态构建范式隐含地认为图结构一经建立即可长期复用,忽略了语料动态演化过程中对图结构的一致性、可控性与可扩展性的挑战。
尤其是在新闻资讯、科研论文、用户生成内容等高频更新的语料场景下,传统 Graph-RAG 模型在更新效率与语义完整性之间难以取得平衡,导致系统性能难以持续优化。
为突破这一关键瓶颈,我们提出 EraRAG(Efficient and Incremental Retrieval-Augmented Generation),一种专为动态语料设计的高效图结构 RAG 框架。
本文由华为香港研究院、香港科技大学、香港中文大学(深圳)、香港中文大学、湖南大学、微众银行联合完成。

论文标题:
EraRAG: Efficient and Incremental Retrieval Augmented Generation for Growing Corpora
论文链接:
https://arxiv.org/abs/2506.20963
项目链接:
https://github.com/EverM0re/EraRAG-Official
EraRAG 创新性地引入超平面哈希与递归摘要机制,首次实现了语义一致、结构稳定且支持增量更新的层次化知识图构建方式,有效弥合了检索效率与图结构可维护性之间的矛盾,在保持静态精确度的同时支持稳定动态添加,为构建可扩展、可部署、可演化的 RAG 系统提供了新路径。

为何需要EraRAG:现有方法的局限与革新
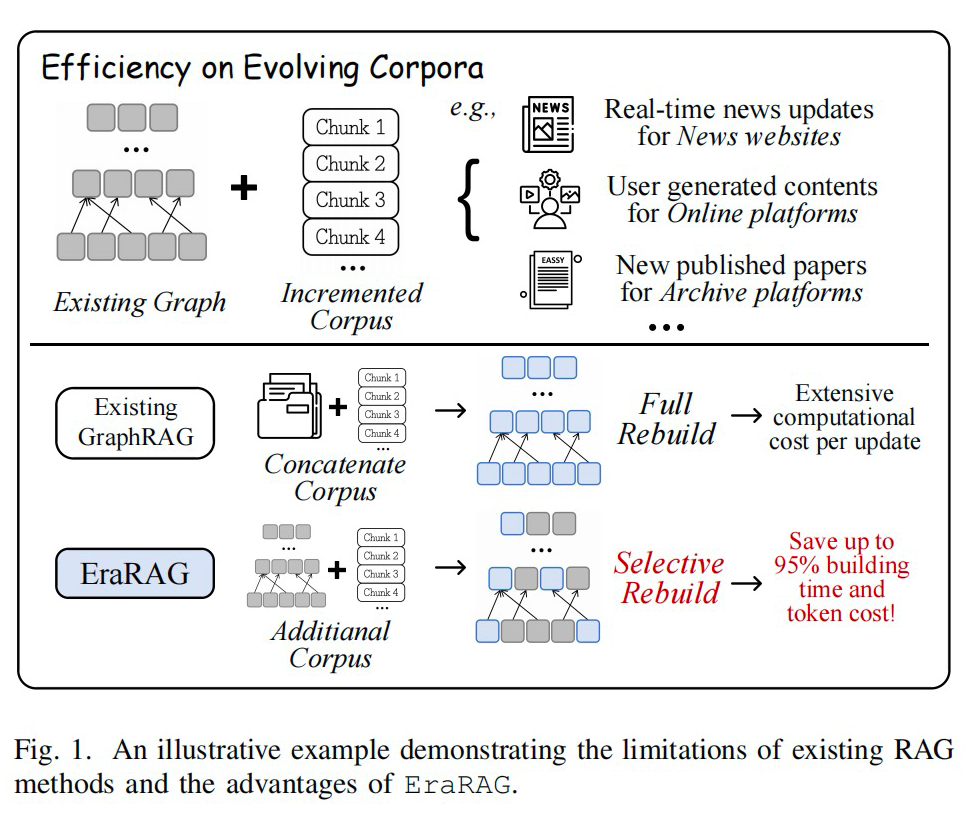
Graph-RAG 已经在增强大语言模型知识能力方面取得了显著进展,但现有方法普遍假设语料库是静态不变的,难以适应实际中语料持续增长的需求。
一旦新增内容到来,常见做法往往需要整体重构图结构,带来巨大的计算和存储开销,也破坏了原有结构的语义稳定性。同时,传统图构建过程多依赖社区检测或聚类算法,不仅计算复杂,而且在增量场景下缺乏可重复性,容易导致图结构漂移。
此外,现有方法在语义粒度控制方面也较为粗放,难以同时兼顾细节与抽象语义,影响多跳推理与长文本理解效果。
EraRAG 针对这些核心痛点进行了系统性设计。它以超平面 LSH 替代传统聚类,提供了高效、可复现的语义分段方式,并通过多层摘要构建出结构清晰、粒度可调的语义图谱。
在更新阶段,EraRAG 可精确定位受影响的局部区域,仅在必要范围内触发图结构与摘要的调整,从而显著降低更新代价并保持整体语义一致性。
这种可扩展、可维护的设计使 EraRAG 成为首个真正支持动态语料的高效 Graph-RAG 框架,为实际部署提供了更具可行性的解决方案。

为动态语料而设计的高效图结构RAG框架
面对图结构 RAG 在动态语料场景中的可扩展性瓶颈,EraRAG 提出了一种分层构图、可增量更新的解决方案,实现了检索效率、表示能力与更新代价之间的平衡。
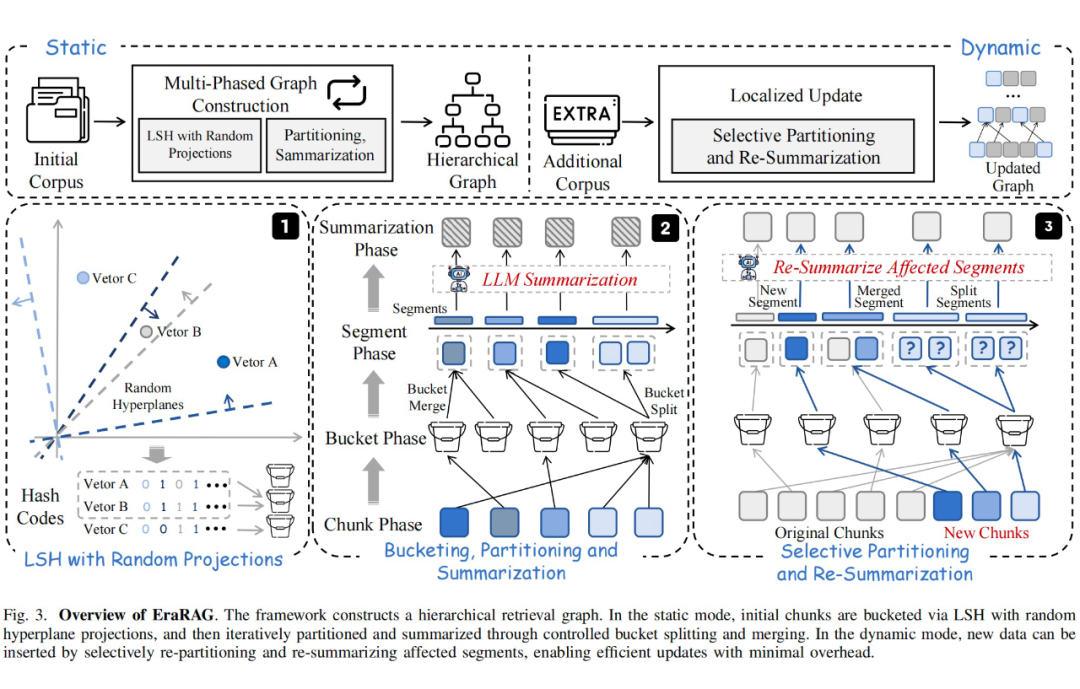
其关键设计在于结合超平面局部敏感哈希(Hyperplane-based LSH)与递归语义摘要机制,将大规模文本组织为结构紧凑、可局部维护的层次化语义图。
EraRAG 的整体流程自底向上展开。首先对原始语料进行分块处理,划分为较短文本片段(chunk),并使用固定的文本编码器(如 BGE-M3)生成归一化嵌入向量。
随后,系统通过投影这些嵌入到一组固定的随机超平面上,得到每个向量的哈希签名,依据哈希结果将相似文本自动聚集进同一桶(bucket)。
为保证桶的语义一致性和大小均衡,EraRAG 采用可控的分段策略,对超大桶进行划分、对小桶进行合并,从而形成初始的语义段(segment)。
在图构建阶段,系统对每个段调用 LLM 执行摘要,将其内容概括为更高层次的语义节点,并生成新的嵌入,递归执行同样的哈希、分段与摘要流程,逐层向上构建出多层次的图结构。
每一层代表一个语义抽象层级,最底层保留原始文本粒度,而越往上则越接近概括性和结构化语义。这一分层结构既可支持高效检索,也具备跨粒度适配不同任务类型(如细节问答 vs. 长文理解)的能力。
在应对语料增长方面,EraRAG 引入了局部可控的图更新机制。新增文本经过相同的编码与哈希流程被插入对应桶中,只需更新受影响的段与其父节点,并在图中进行局部传播重构,避免对整个图进行全量更新。
由于 EraRAG 在构建图时保留了原始的超平面投影参数,这使得每次增量插入都具有高度一致性与可重复性。整个更新流程可以在常数数量的段内局部完成,计算和 token 消耗显著降低。
得益于这一分层组织与增量更新策略,EraRAG 可在无需重训练或全图重构的前提下,快速适配语料动态变化,并保持图结构的语义一致性与表示完整性,在新闻、社交内容、学术文献等不断增长的实际场景中具备良好的落地潜力。

实验评估:效率与精度双突破
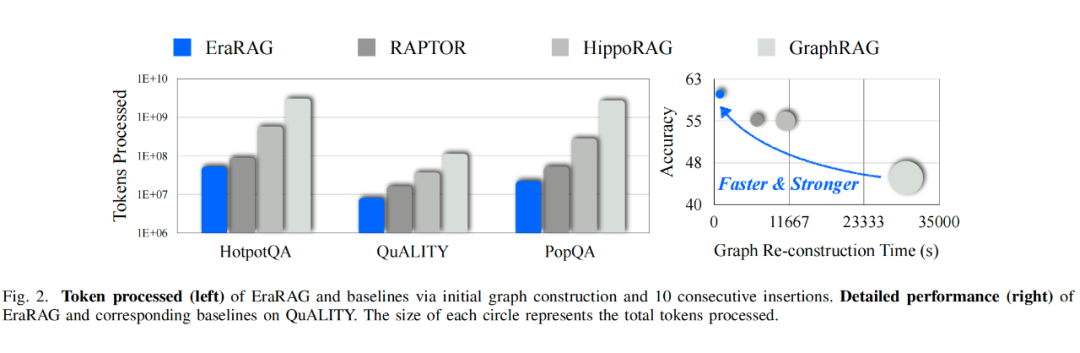
我们在多个具有代表性的问答数据集上对 EraRAG 进行了全面评估,涵盖了事实检索、多跳推理、长文理解等典型任务。实验从静态图构建和动态语料更新两个方面出发,重点考察系统在真实语料增长场景下的适应性与稳健性。
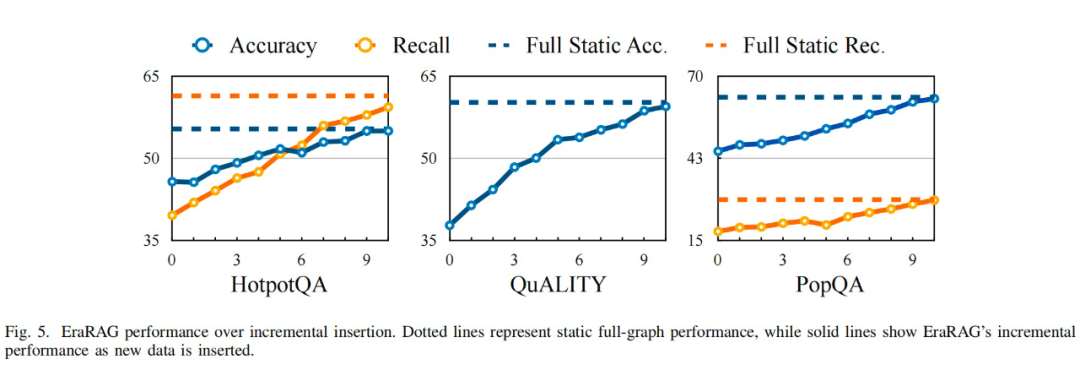
结果表明,EraRAG 在效率上显著优于现有的图结构 RAG 方法。在面对不断扩展的语料库时,其增量更新机制能够避免重复计算与结构重建,仅需对新增部分进行局部调整,从而有效降低计算开销与存储成本,展现出良好的可扩展性和实用性。
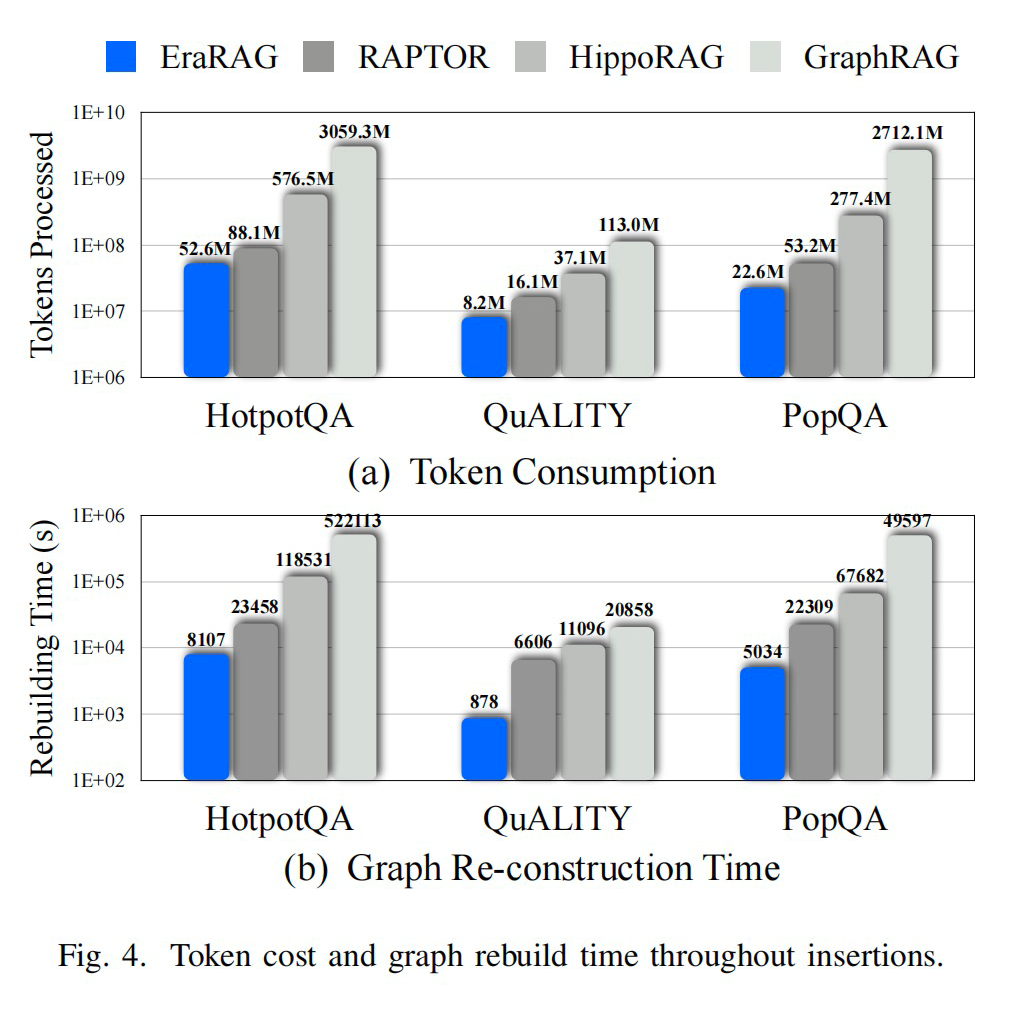
在精度方面,EraRAG 同样展现出领先优势。得益于其层次化语义建模和结构化表示,系统能够更准确地捕捉文本中的关键线索与多跳关系,显著提升了对复杂问题的理解与生成能力,在多种任务上都取得了优于现有方法的表现。
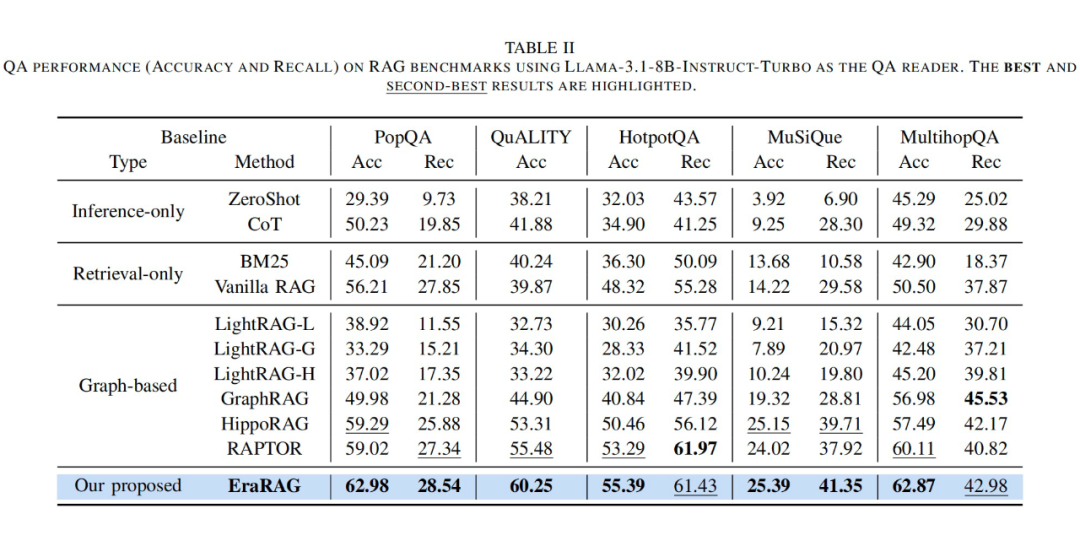
此外,在动态语料添加过程中,EraRAG 能够持续稳健地吸收新知识,系统性能随新增语料稳步提升,最终达到与静态构建相当的准确度。
这充分说明 EraRAG 在结构层次与语义一致性方面具备良好鲁棒性,即便在不断变化的知识环境中,也能保持稳定可靠的性能表现。

潜在局限与未来发展方向
尽管 EraRAG 在多跳推理与动态语料更新任务中展现出优越性能,其方法仍存在一定边界。
例如,系统在构建初始图时对语料覆盖度有较高要求,若初始结构过于稀疏,后续插入可能影响整体语义一致性。同时,多层图的摘要过程依赖大型语言模型,在低资源或跨语言场景下可能面临计算瓶颈。
此外,当前方法主要聚焦于文本模态,尚未覆盖图像、视频等多模态场景,限制了在更复杂应用中的扩展性。
未来,我们计划从多个方向拓展 EraRAG 的能力,包括在低语料下提升图初始化的稳定性,推动摘要模块的轻量化与部署效率,以及探索向图像、音频等模态扩展的统一图结构构建方法。
同时,我们也将进一步优化检索策略,使其更灵活地适配不同类型任务,提升系统在理解与生成上的整体表现。
我们相信,EraRAG 为构建可增量、可扩展的多模态语义检索系统提供了坚实基础,值得在更广泛的真实场景中深入探索与实践。
(文:PaperWeekly)