


在短视频爆发与长内容价值深挖并行的当下,如何“又快又准”地把冗长音视频变成高浓度素材成为内容创作者的普遍痛点。PreenCut——由独立开发者 roothch 开源、结合 WhisperX+大模型的 AI 视频剪辑框架——给出了新答案:只需一句自然语言描述,即可秒级检索并导出目标片段。本文将带你从原理到落地,全面拆解这款工具的工程细节与落地姿势。

一、项目概述
一句话200 字总结:PreenCut 是一款基于 WhisperX 高精度语音转录、DeepSeek/豆包大模型语义理解的开源 AI 视频剪辑工具,支持自然语言检索、AI 智能分段、批量处理与多格式导出,可一键将长视频转化为精华片段 ZIP 包或合并视频,极大提升影视、教育、自媒体等多场景剪辑效率。
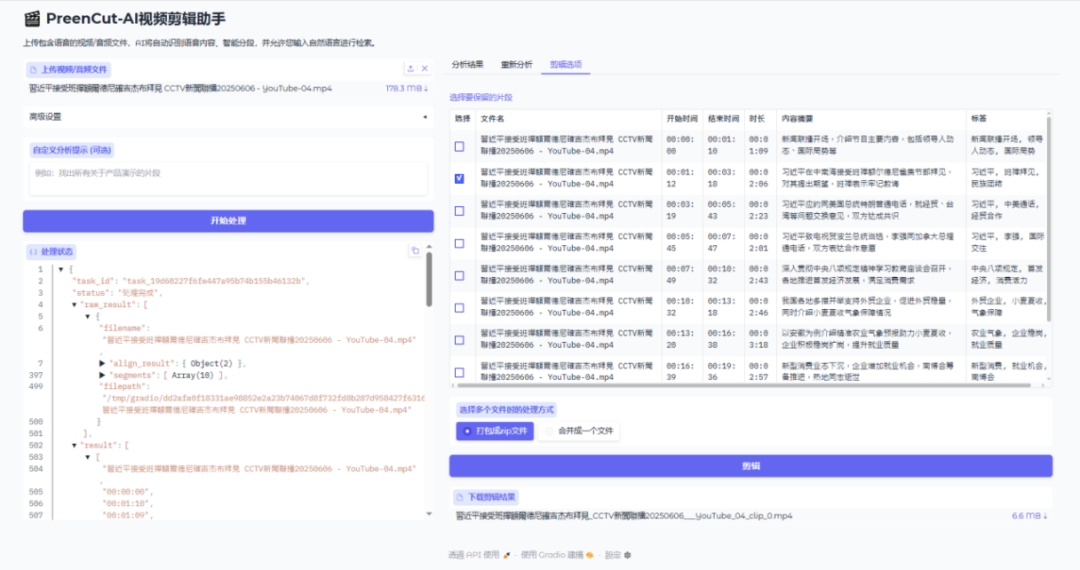
二、主要功能
(一)、自动语音转录
1、多语言:支持 99 种语言的词级转录。
2、说话人标签:访谈场景自动区分主持人/嘉宾。
(二)、AI 智能分段
1、无参数化:无需设置阈值,LLM 依据语义自动决定切分粒度。
2、摘要即标签:每段 10~15 字,可直接做章节标题。
(三)、自然语言搜索
1、支持中文、英文混合描述,如“找出张三谈 AI 安全的部分”。
2、返回 Top-K 候选片段,置信度可视化。
(四)、智能剪辑导出
1、单段导出:一键生成同名+起止时间的 mp4。
2、多段合并:按时间轴顺序合并,可自定义转场黑帧。
3、ZIP 打包:含视频、SRT、JSON 元数据,方便二次创作。
(五)、批量处理
1、CLI:python preencut.py –input_dir ./lectures –prompt “课程章节”
2、Web UI:Gradio 拖拽多文件,进度条实时刷新。
(六)、重新分析
在不重新跑WhisperX 的前提下,换 Prompt 即可二次生成片段,节省 80 % 时间。
三、技术原理
(一)、端到端流水线总览
1、输入层:支持 mp4、mov、mkv、mp3 等十余种音/视频容器与编码。
2、语音转录层:调用 WhisperX(Large-V3),输出带词级时间戳的 SRT/JSON。
3、语义理解层:将转录文本连同时间戳送入本地或云端 LLM(DeepSeek、DouBao),按用户 Prompt 生成“片段摘要 + 起止时间 + 置信度”。
4、片段索引层:构建 (start, end, summary, tags) 四元组向量索引,支持稠密向量+关键词联合召回。
5、导出层:FFmpeg 子进程执行无损裁剪/合并,可选 ZIP 打包或单文件输出。
(二)、核心算法解析
1、语音活动检测(VAD)与说话人分离
WhisperX 内部采用 Silero VAD + pyannote 说话人嵌入,保证多人访谈也能切准边界。
2、Prompt 工程
系统内置默认Prompt:
“`
请根据以下转录文本,把视频分成语义完整的片段,每段一句话总结,输出JSON 数组,字段:start, end, summary。
“`
用户可在Re-analyze 页面无代码重写 Prompt,实现“找出所有产品 Demo” 等自定义需求。
3、时间戳对齐策略
LLM 返回的秒级时间戳通过正则回溯到最近词级时间戳,误差 <300 ms。
4、资源监控
采用psutil 实时采集 CPU、VRAM、I/O;当显存不足时自动下调 WhisperX batch_size,防止 OOM。
(三)、性能优化要点
1、WhisperX batch_size 与模型尺寸可在 config.py 热调;单张 RTX 4090 批尺寸 16 时,1h 视频转录 <5 min。
2、LLM 侧支持本地 vLLM 推理,降低云端调用成本。
3、FFmpeg 采用 -c copy 无损裁剪,速度瓶颈仅磁盘 I/O。
四、应用场景
(一)、长视频精剪
在信息快速更迭的当下,长视频易使观众疲倦。PreenCut能将2小时的访谈、播客等内容,精准浓缩为5分钟精华。对于B站知识区UP主而言,可高效产出有价值内容,吸引观众注意力,提升视频传播效率与影响力,让观众短时间获取核心信息。
(二)、教育内容整理
大学公开课内容多、时长久,学生复习困难。PreenCut可自动对课程章节化,按语义划分片段并生成总结。学生复习时能秒级跳转至所需知识点,节省时间与精力。教师也能借此整理教学视频,为学生提供更清晰的学习资源。
(三)、影视后期
影视剪辑处理大量dailies素材时,传统筛选效率低。PreenCut通过自然语言检索,如输入“NG”“笑场”等关键词,能从海量素材中快速定位相关镜头,辅助剪辑师粗剪,既提高效率,又确保重要素材不被遗漏。
(四)、新闻报道
新闻记者需从大量采访素材提取关键信息。PreenCut可助力记者快速定位,如记者会结束后,输入“关于房价的回答”等关键词,能即刻找到金句片段,帮助记者高效完成报道,提高新闻时效性与准确性。
(五)、自媒体创作
自媒体创作者需不断产出新颖内容。PreenCut让创作者能利用同一视频素材,更换不同Prompt生成多条短横竖屏素材。在TikTok/抖音等平台,可根据热点和受众需求多样化创作,提升账号影响力与粉丝量。
五、快速使用
(一)、环境准备
1、系统:Ubuntu 22.04 / Windows 11 / macOS 13+
2、Python≥3.8,CUDA≥11.8(可选)
3、安装 FFmpeg
Ubuntusudo apt update && sudo apt install ffmpegmacOSbrew install ffmpegWindows 下载 https://ffmpeg.org 并加入 PATH
(二)、源码部署
1、克隆仓库
git clone https://github.com/roothch/PreenCut.gitcd PreenCut
2、安装依赖
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple3、配置 API 密钥
编辑config.py,按需填写 LLM_MODEL_OPTIONS;然后在 shell 写入
export DEEPSEEK_V3_API_KEY=sk-xxxexport DOUBAO_1_5_PRO_API_KEY=sk-yyy
(三)、启动Gradio界面
python main.py # 浏览器访问 http://localhost:7860六、结语
PreenCut 用“语音转录 + 大模型语义”把传统 NLE(非线性编辑)里数小时的机械拖拽浓缩成一句自然语言,代表了 AIGC 工具下沉到剪辑场景的最新范式。随着本地 LLM 推理成本持续走低,类似 PreenCut 的“零门槛、高精准”AI 剪辑框架将成为内容工业化的新基建。
GitHub 源码:https://github.com/roothch/PreenCut
(文:小兵的AI视界)