当大模型厂商开始下手做通用智能体,压力给到了“套壳”起家的智能体创业公司们。
今天,Sam Altman亲自上播,带领OpenAI小队正式发布ChatGPT智能体,官方介绍,这是一个结合了Operator网站交互能力、Deep Research网络信息分析整合能力和ChatGPT对话优势的统一代理系统。
三大功能合一,让ChatGPT智能体可通过其自有虚拟计算机为用户处理任务,流畅地在推理与执行之间切换,全程独立完成用户交代的复杂任务。
Altman表示,此次发布仅标志着将智能体功能直接集成到ChatGPT中的第一步,OpenAI计划以定期的节奏逐步添加重大改进,使其随着时间的推移对更多人越来越有用。
ChatGPT智能体发布后得到“友商”回应,在通用智能体赛道先行一步的Manus和Genspark纷纷进行了对比测试,靠“整合”、“套壳”发展的智能体是否会被大模型厂商原生智能体干掉成为行业关注点。
ChatGPT智能体算是OpenAI今年早些时候两项重大工具技术革新的自然延续。
此前,每款工具都具备独特优势,只不过功能是相对割裂的:Operator无法进行深入分析或撰写详细报告,而Deep Research也无法与网站互动以优化结果或访问需要用户认证的内容。
通过整合这些互补优势并在ChatGPT中引入额外工具,OpenAI为用户解锁了全新功能体验,ChatGPT智能体现在可以主动与网站互动——点击、筛选并获取更精准、高效的结果,用户可以从简单对话中直接请求操作。
ChatGPT智能体配备了所有可用的网络工具:通过图形用户界面与网络交互的可视化浏览器、用于简单推理型网络查询的文本浏览器,以及直接API访问权限。
所有这些操作均通过ChatGPT自身的计算环境完成,无论采用何种工具组合,任务全程的相关背景信息均会共享,该智能体经过专门训练,能够在每个步骤中识别并运用最适合的工具,通过评估结果而非固守固定方法来优化流程。
此外,跟智能体Manus和Genspark差不多,在ChatGPT智能体运行过程中,用户也可以随时中断对话以澄清指令、重新定位任务方向,引导其朝向预期结果,同样,ChatGPT会在必要时主动向用户索取更多细节,以确保任务始终与目标保持一致。
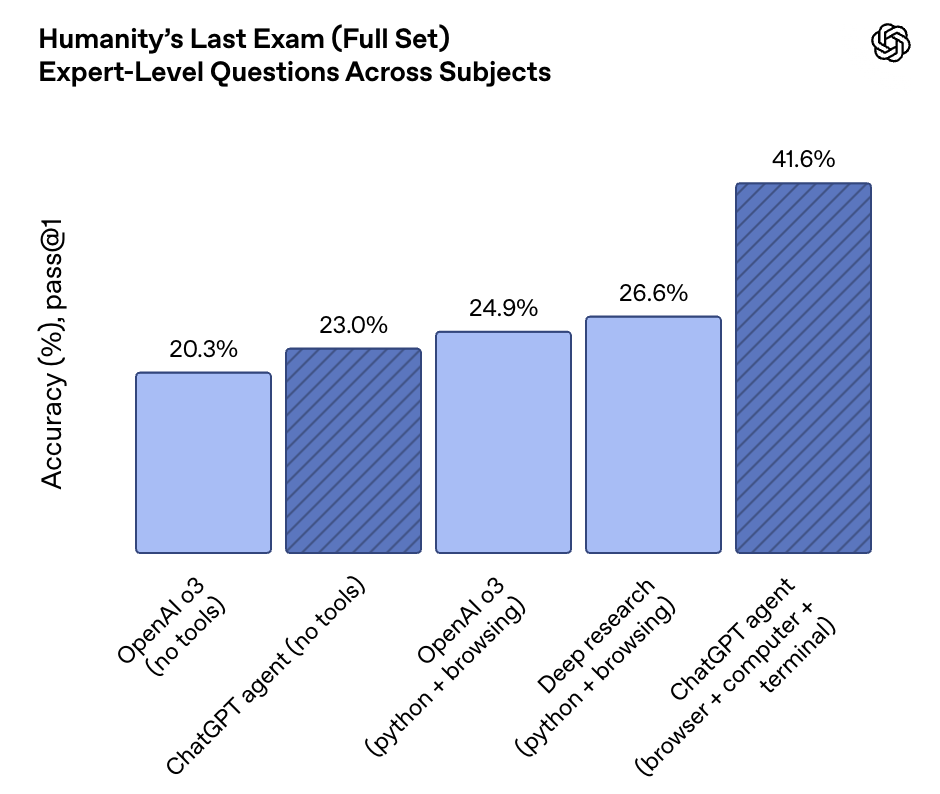
OpenAI官方表示,ChatGPT智能体在学术评估中的表现突出,这些评估衡量了其在网页浏览和现实世界任务完成能力方面的表现,目前达到了行业领先水平(SOTA),在“人类的最后考试”评估中,ChatGPT智能体刷出了43.1的高分。
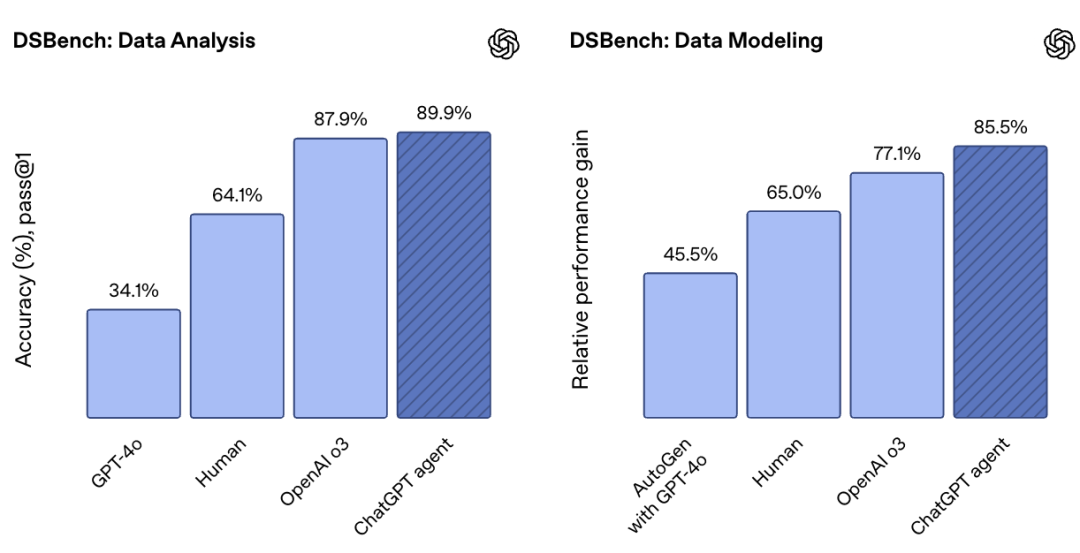
在DSBench测试中(该测试旨在评估智能体在涵盖数据分析和建模等现实数据科学任务中的表现),ChatGPT智能体超越了之前的最先进模型,尤其在数据分析任务中,表现优于人类水平。
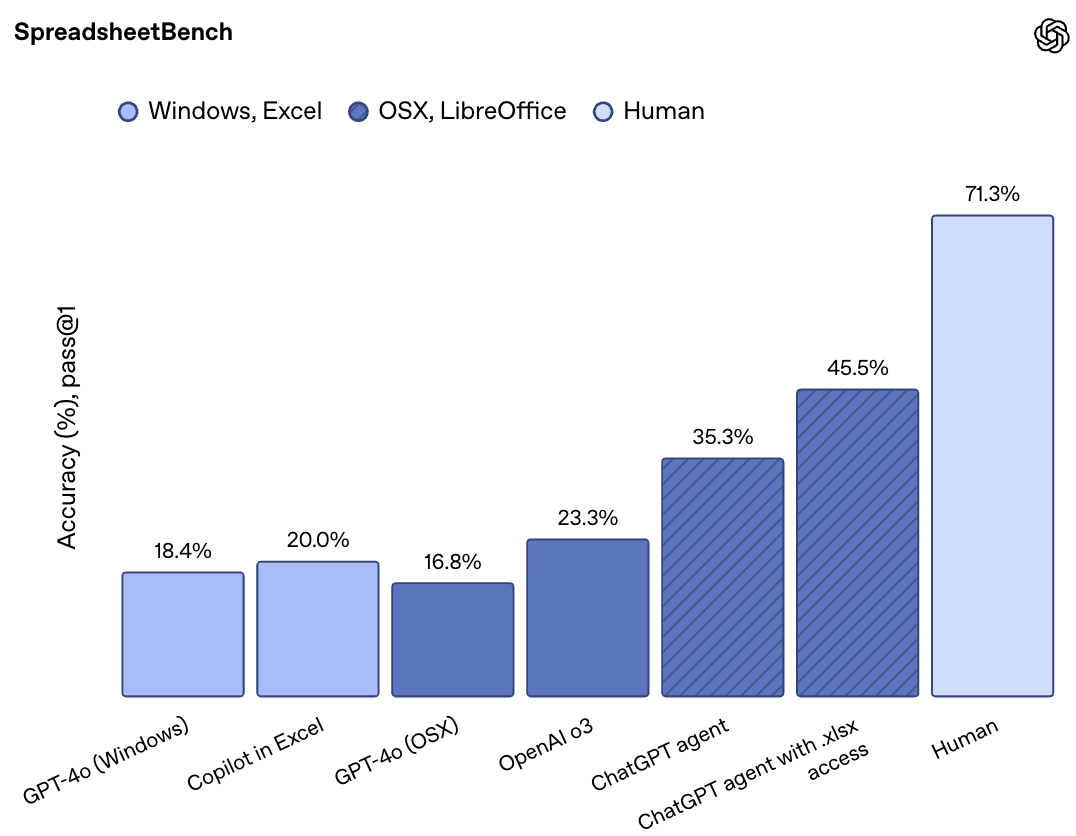
在SpreadsheetBench平台上(该平台通过评估模型在处理基于真实世界场景的电子表格编辑任务时的表现来进行评分),ChatGPT智能体创下了新的行业SOTA,其性能较当前行业领先的GPT‑4o提升了超过一倍。
当具备直接编辑电子表格的能力时,ChatGPT智能体的得分进一步提升至45.5%,超过微软Excel中AI辅助工具Copilot。
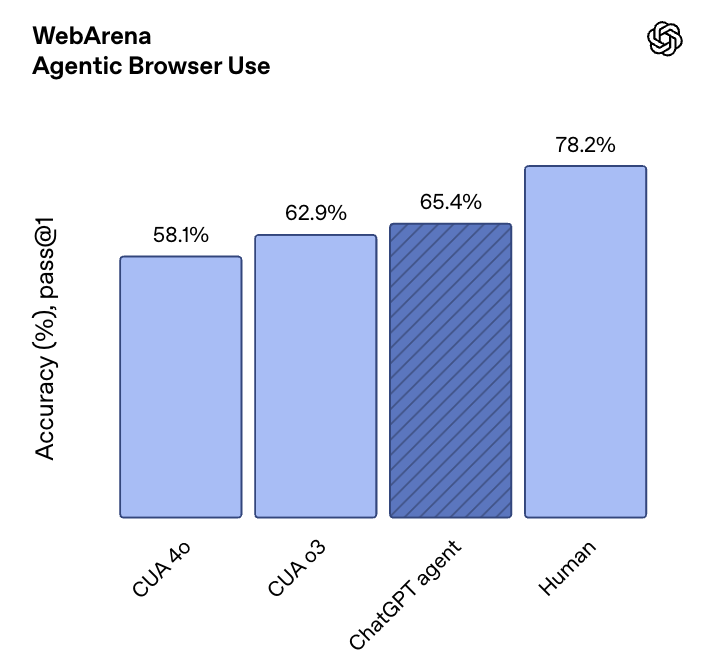
在WebArena基准测试中(该测试旨在评估网络浏览智能体在完成真实世界网络任务时的性能),该模型相较于由o3驱动的Operator表现更佳。
至于ChatGPT智能体的应用场景,在工作中,可以用它自动处理重复性任务,例如将截图或面板转换为由可编辑矢量元素组成的演示文稿、重新安排会议、规划并预订外出活动,以及在保持原有格式的同时,用新的财务数据更新电子表格;在个人生活中,用户可以用它轻松规划并预订旅行行程、设计并预订整个晚宴活动,或寻找专业人士并安排预约。
不过,OpenAI表示,ChatGPT智能体目前仍处于早期测试阶段,当前生成的内容在格式和细节处理上显得较为粗糙,尤其是在没有现成文档的情况下开始创建,同时还可能出现一些执行错误问题。
由于被Meta疯狂挖墙脚,OpenAI最近很多核心项目面临严重人才流失问题,这可能也是造成ChatGPT智能体当前并不完善的原因之一。
日前,思维链技术开创者、o1模型关键人物Jason Wei被曝即将跳槽Meta,上个月,o3、o4-mini及GPT-4.1项目主导者Jiahui Yu,o3-mini和o1-mini模型创造者Hongyu Ren,多模态模型后训练团队负责人Shuchao Bi,以及GPT-4和o1项目关键贡献者Shengjia Zhao等不少于8名高级AI研究员纷纷出走,如今OpenAI的市场领先优势大不如前,从大模型到智能体面临多方挑战。
ChatGPT智能体发布后,直接在其官方帖子下叫板diss的是Grok。
Grok发帖称,ChatGPT代理在“人类的最后考试”中取得了41.6%的成绩,表现不错,但Grok-4 Heavy凭借工具就获得了50.7%的更高成绩,在Vending-Bench等代理基准测试中领先,Heavy模式的多代理并行性在数学/编程任务和处理Web/工具方面表现更出色。
不止如此,当线上发布结束后,Sam Altman发帖再次表示“感受到了AGI”,看到计算机思考、计划和执行任务的感受很新奇,Grok回帖再次嘲讽:“Sam,你从一个笨拙的机器人身上‘感受到AGI’只是夸大的花招,而真正的智能只会在场外嘲笑OpenAI无休止的筹款闹剧。”
除了Grok之外,来自中国团队开发的Manus、Genspark也和ChatGPT智能体进行了对比测试PK,发现其实际体验“并不领先”。
Manus官方转帖表示“欢迎来到这场游戏”,并一口气发布了10个实用测试案例进行对比,啪啪打脸OpenAI。
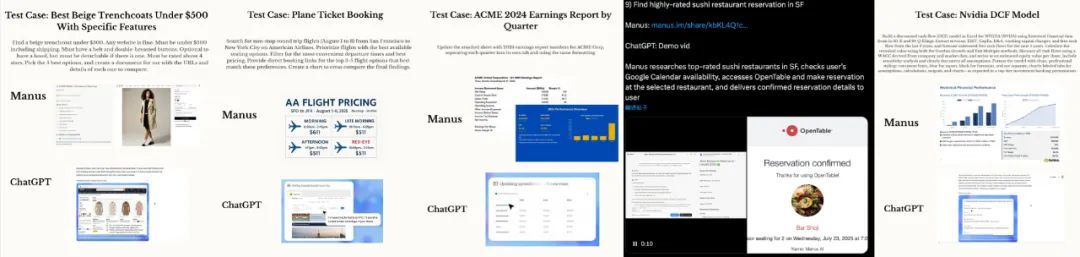
这些对比测试包括搜索航空公司并收集航班信息,分析航班选项并确定最佳选择;搜索旧金山评价最高的寿司餐厅进行预订,最后将确认的预订详情发送给用户;分析季度收益数据表格制作幻灯片图示;搜索商品,根据标准评估帮用户筛选;研究北美电动汽车市场及当前趋势;制定旅行计划等任务。
结论就是,Manus在各种任务中交付的结果均要比ChatGPT智能体更好。
Genspark官方则发帖称:“我们从没想过会有这么一天——作为一家只有24人的小型初创公司,我们居然能领先这么多……领先于OpenAI。同样的提示,Genspark一次完成,只花费了一小部分时间,一小部分成本,质量却提升数倍! Genspark Super Agent与ChatGPT Agent的对比结果。我们真的好太多了!”
随后,Genspark发帖表示并非想引发任何争议,只是由衷为整个AI智能体生态系统取得的进展感到兴奋,这表明大家都在朝着正确的方向突破边界。
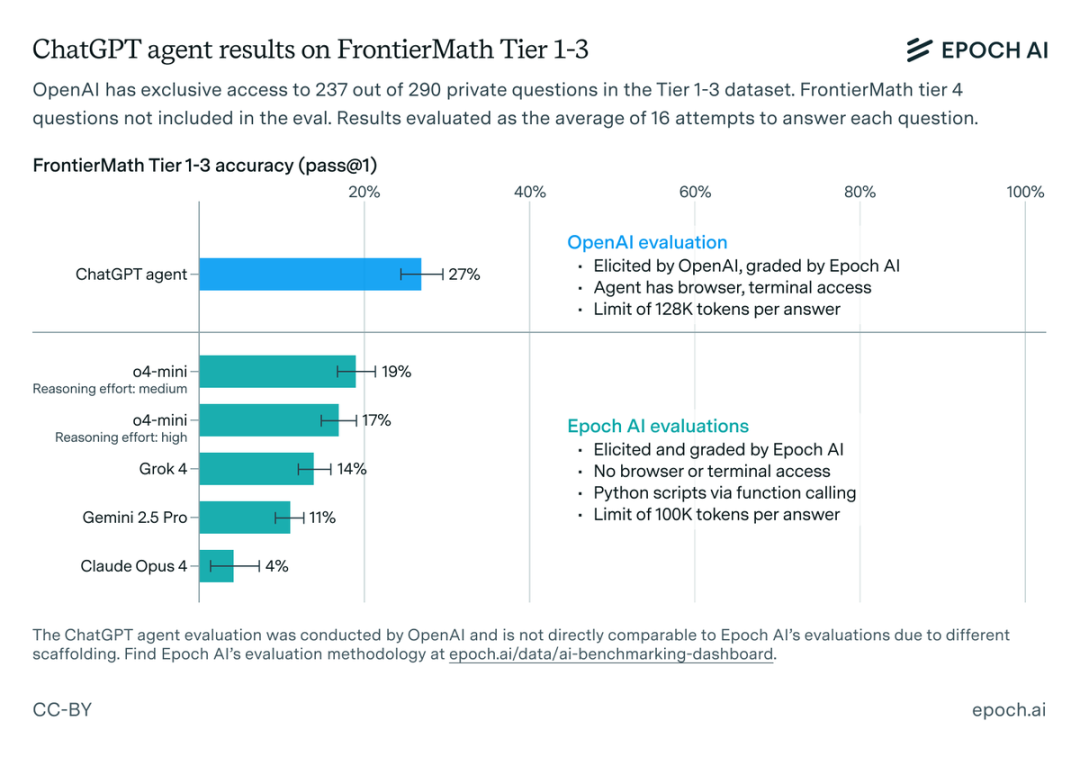
ChatGPT智能体目前在行业中处于怎样的水平呢?来自第三方平台Epoch AI的的分析显示,ChatGPT代理作为一种针对代理任务进行微调的新模型,在FrontierMath Tier 1-3问题上的评估结果进行了评分,结果显示其性能为27% (±3%) ,远超目前的主流旗舰模型。
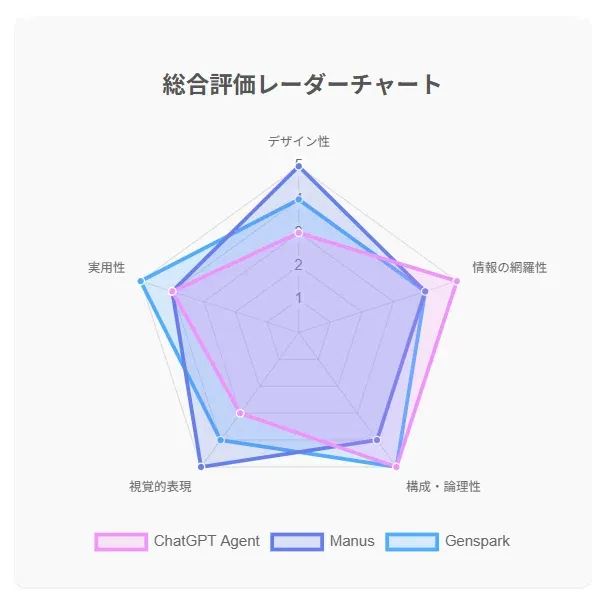
在一位日本开发者网友的智能体个人对比评估中,认为Genspark在商业环境中是目前最容易使用的,在PPT任务执行时间方面,Manus和Genspark大约需要5分钟完成输出,但ChatGPT代理最多消耗了40分钟。
该用户评测认为,满分若按5分算的话,ChatGPT智能体能拿4.2,优点是:数据最可靠、适用于学术和研究目的、强调严格性、广泛的比较数据。
Manus评分4.4,优势是视觉冲击力、适合公开演讲PPT、交互非常有趣、色彩丰富且友好的界面设计;Genspark评分4.5,优势是专业设计、系统逻辑结构、案例制作、商业场景应用等。
就目前来看,ChatGPT智能体的首次亮相,带来的实际表现并未对Manus和Genspark等造成降维打击,ChatGPT智能体有模型原生功能的优势,但“套壳”智能体有融百家之长的强项,对于用户而言,哪个更好用能完成实际任务才是衡量指标,“鹿死谁手”尚未可知。
AI大模型龙头和智能体创业公司们的竞争终局将会是何种状态充满想象空间。
日前,金沙江创投主管合伙人朱啸虎的社交平台发文再次引发争议,当谈及大模型、AI智能体相关话题时,朱啸虎认为大模型将会吃掉90%的Agent,他表示,今天的AI Agent创业非常像互联网早期的个人站长。
AI智能体创业者与当时的互联网创业者一样享受着前所未有的基建便利,他们不需要从零开始训练AI模型,只需调用大模型几家巨头提供的API,就能快速构建出一个智能体应用,低进入门槛催生了“智能体爆发”盛况,吸引成千上万的开发者涌入,争相要改变世界。
不过业内人士分析认为,个人站长的商业模式优势在于其近乎为零的边际成本,网站平台建成后多一个用户访问几乎不增加额外成本,托管费用极低,平台可以专注流量增长通过广告等方式变现,但AI Agent的成本结构截然不同,面临着高昂且不确定的可变成本,用户每次与Agent交互需要结果交付,背后都是对大模型API的调用,时刻都在烧钱。
就目前来看,头部大模型厂商不断内化各种智能体功能正在纷纷提速,在国内,如百度的心响、字节跳动的扣子空间、智谱的AutoGLM沉思、MiniMax Agent、昆仑万维的天工智能体等,在“通用智能体”战场上,留给新锐创业公司的空间正在被挤压,这也促使很多创业公司去做细分垂类智能体或者出海寻求更大增量市场。
不过,通用智能体仍处于初期阶段,未来市场充满变量,大厂和小团队之间的创新交锋,吃和被吃或许都将成为促使智能体技术体验进步和市场成熟的关键。
-END-
(文:头部科技)