
传统注意力机制统治地位或将终结?谷歌最新研究让AI「会学会记」!

让人工智能像人一样学会「记忆」一直是研究人员的梦想。
谷歌研究团队最新推出的Titan架构,通过模拟人类的长短期记忆系统,让AI不仅能关注当前信息,还能学会主动记忆和遗忘。
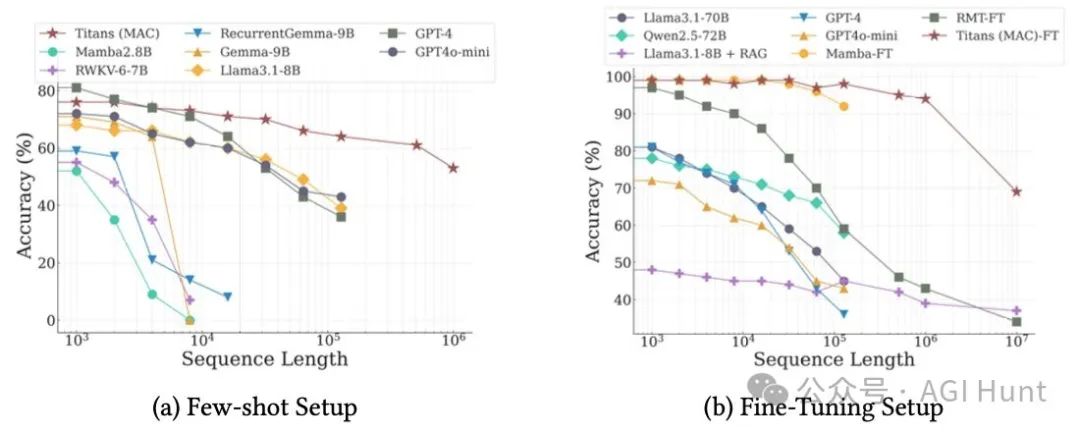
更令人惊喜的是,实验表明Titan在200万以上的长文本处理中,性能竟超过了GPT-4和Llama3-80B等超大模型!
为什么要颠覆注意力机制?
自从Transformer横空出世,注意力机制就成为了大语言模型的核心组件。但它有个致命问题:处理长文本时计算量呈平方增长。
谷歌研究员Ali Behrouz团队从人类记忆系统获得灵感:人类的短期记忆虽然精确,但只能维持30秒。
那么我们是如何处理更长的信息的?
答案是:通过其他类型的记忆系统来存储有用信息。

会「惊喜」的记忆系统
Titan最独特的设计在于其「惊喜度」评估机制。就像人类会对意外事件印象深刻一样,Titan的记忆系统会特别关注「令人惊喜」的信息。
这种「惊喜」分为两种:
-
瞬时惊喜:通过计算记忆对输入的梯度来衡量
-
过去惊喜:之前积累的惊喜程度的衰减值
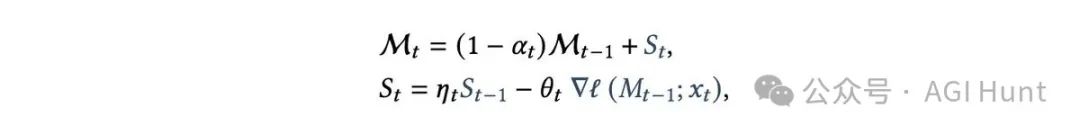
会「遗忘」的智能
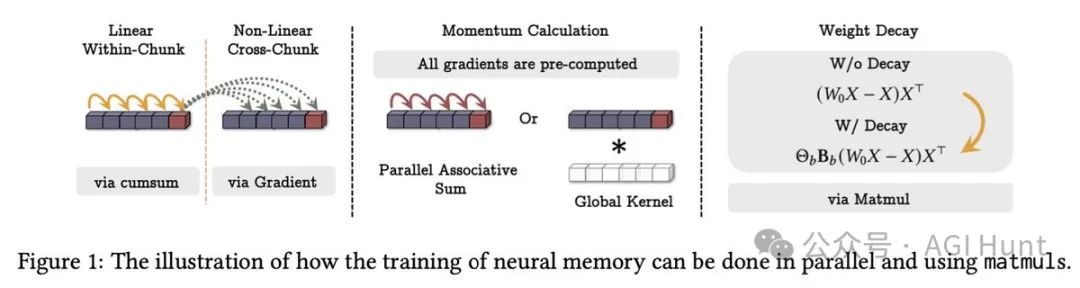
在处理数百万级别的长文本时,「遗忘」变得同样重要。Titan引入了自适应遗忘机制,能根据信息的重要性决定是否保留。
更巧妙的是,研究团队发现这种遗忘机制实际上是RNN中数据依赖门控机制的泛化版本。
三种记忆融合方式
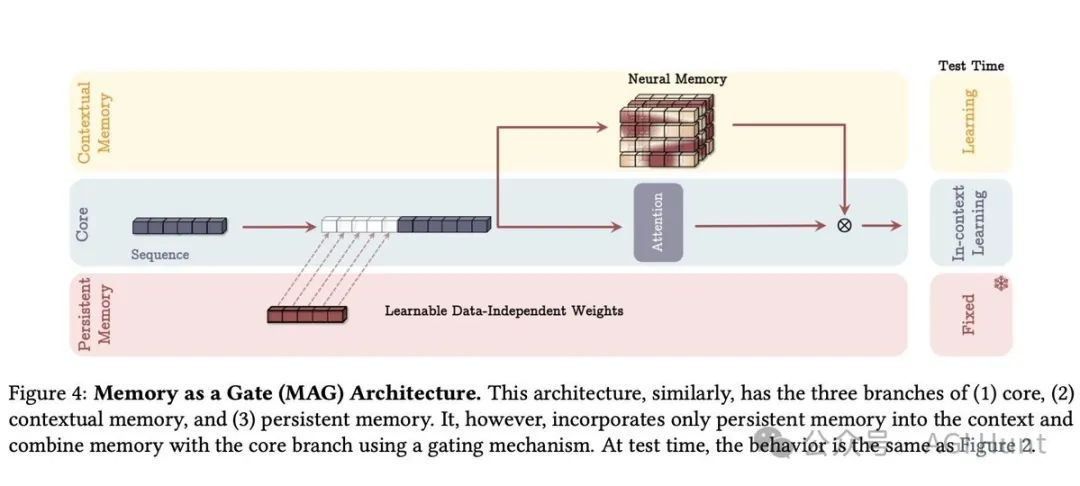
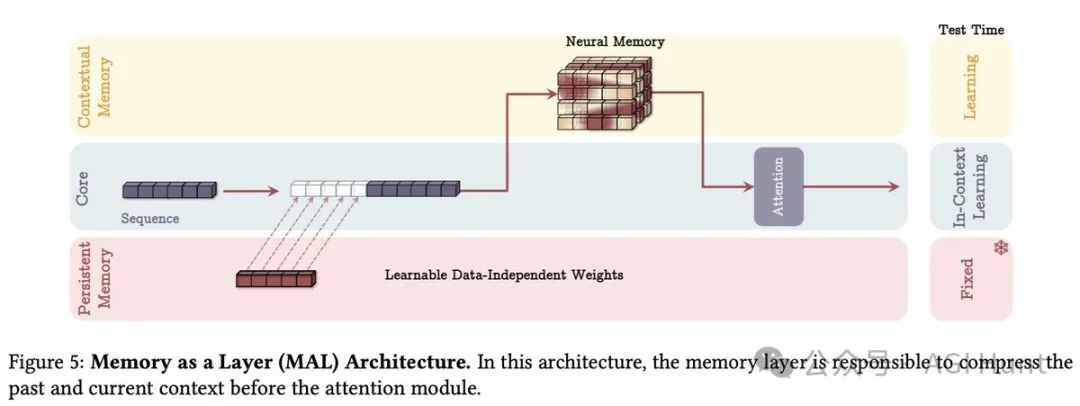
Titan提供了三种将记忆融入架构的方案:
-
记忆作为上下文(MAC)
-
记忆作为头部(MAH)
-
记忆作为层(MAL)
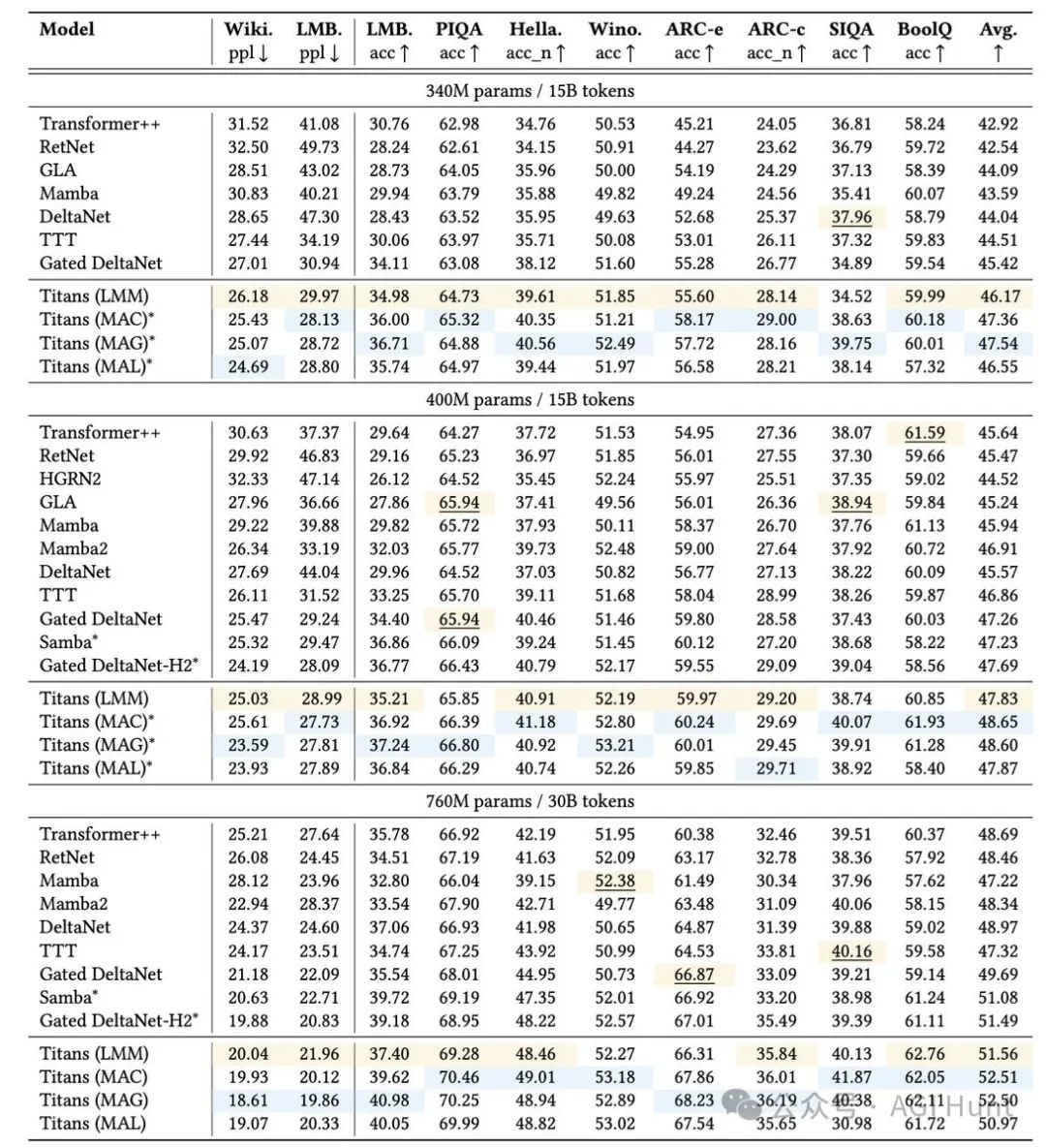
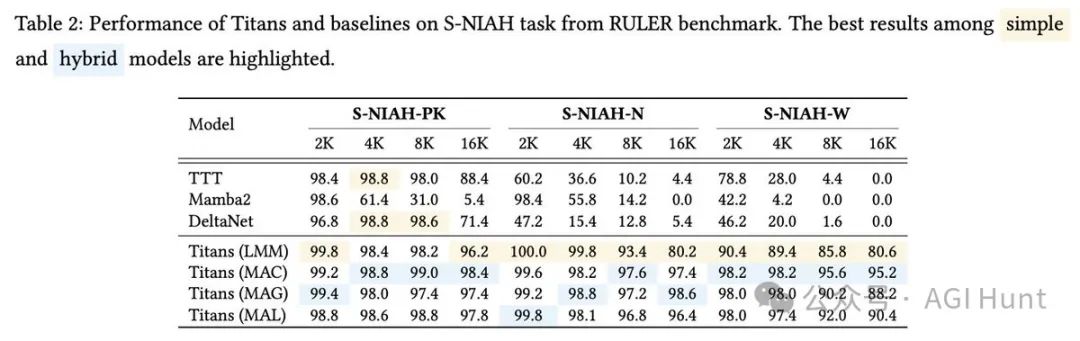
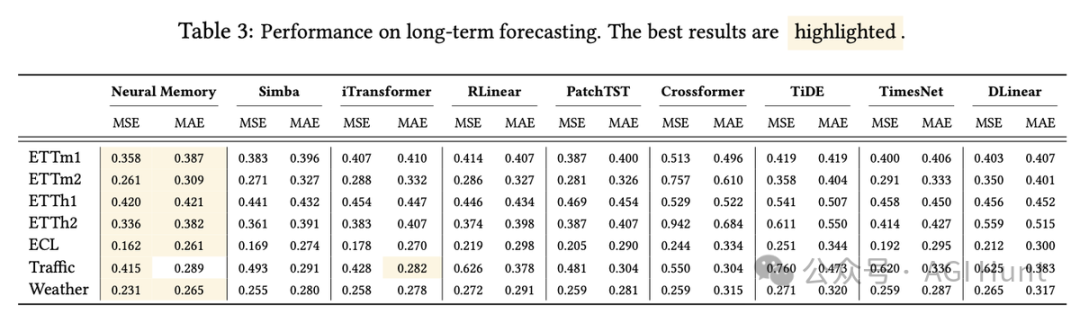
超越超大模型
在多项实验中,Titan展现出惊人的性能。
在语言建模、常识推理和「大海捞针」等任务中,它不仅超越了传统Transformer和现代线性RNN,还在超过200万上下文窗口的任务中击败了GPT-4和Llama3-70B等超大模型。
论文作者Ali Behrouz(@behrouz_ali)表示:
我们将继续完善这项研究,添加更多检索实验,探索更大规模模型,并开源代码。
这项研究给AI领域带来了全新思路:也许未来的AI架构,不一定非要依赖注意力机制,而是可以像人类一样,拥有更智能的记忆系统。
论文地址:https://arxiv.org/pdf/2501.00663v1
(文:AGI Hunt)