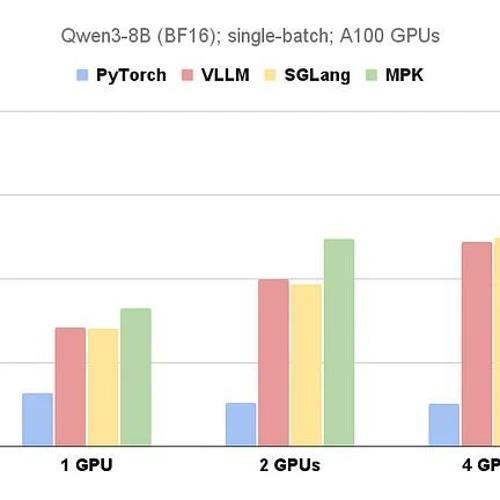
63页的面向AI搜索范式:Multi-agent、MCP、DAG、RL
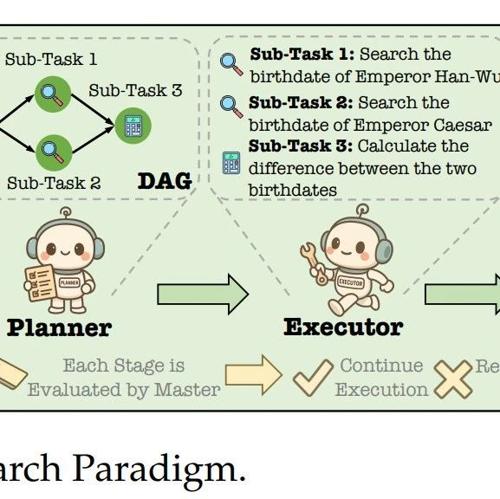
百度搜索发布了一篇关于多智能体框架的论文,该框架重新构想了大型语言模型时代的搜索方式,包括主管、规划者、执行者和撰写者的分工协作机制,旨在实现更加灵活高效的信息检索过程。
百度搜索发布了一篇关于多智能体框架的论文,该框架重新构想了大型语言模型时代的搜索方式,包括主管、规划者、执行者和撰写者的分工协作机制,旨在实现更加灵活高效的信息检索过程。
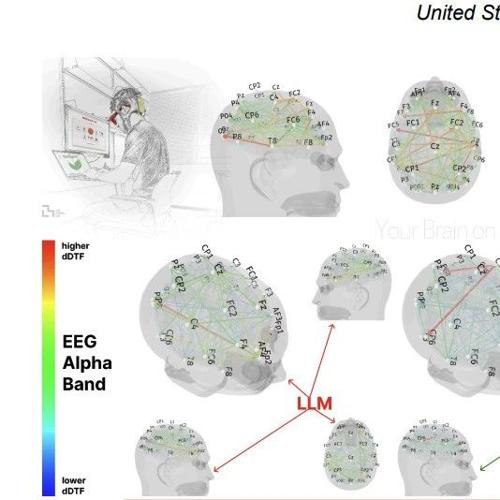
近期MIT研究发现,使用AI语言模型如ChatGPT可能会降低写作任务的认知负荷,但同时也可能影响记忆、批判性思维和写作技能。该研究通过脑电图记录参与者的大脑活动,并收集反馈数据,揭示了不同组别在写作质量、神经活动以及认知成本方面的差异。

在AI智能体构建中,单智能体系统作为单一进程运行,而多智能体系统则像是一个团队。Cognition和Anthropic分别提倡『不要构建多智能体』和『如何构建多智能体研究系统』的观点。文章强调上下文管理、执行速度、令牌使用等关键因素,并指出写任务更适合单智能体,读任务更适合多智能体系统。

Andrej Karpathy 在 YC 的旧金山创业大会上分享了关于 AI 时代软件开发的新范式。他定义了从传统代码到神经网络权重再到大型语言模型(LLMs)的发展路径,讨论了 LLMs 的超能力和认知缺陷,并介绍了如何通过应用如 Cursor 实现部分自主应用来优化用户体验。