
这个扩散LLM太快了!没有「请稍后」,实测倍速于Gemini 2.5 Flash

Mercury 是一款专为聊天应用设计的扩散 LLM,其速度和效率显著提升,能够实现即时响应。Inception Labs 在 X 上宣布了这款新产品,它在性能测试中表现优异,接近 GPT-4.1 Nano 和 Claude 3.5 Haiku 等前沿模型。
Mercury 是一款专为聊天应用设计的扩散 LLM,其速度和效率显著提升,能够实现即时响应。Inception Labs 在 X 上宣布了这款新产品,它在性能测试中表现优异,接近 GPT-4.1 Nano 和 Claude 3.5 Haiku 等前沿模型。
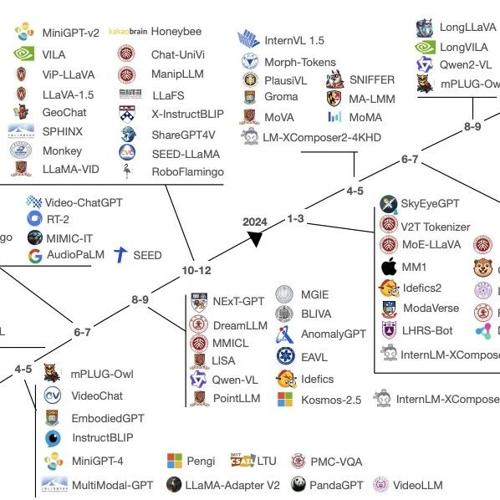
两篇论文综述了从2021年至2025年开发的至少125个多模态大型语言模型,涵盖文本到图像、音乐、视频、人类动作和3D对象等多种生成任务。文章强调自监督学习、专家混合等关键技术,并提出了MLLMs融合策略和技术分析框架。

本文提出了一种双专家一致性模型DCM来解决视频生成中的一致性蒸馏问题,通过解耦语义合成与细节精修,显著减少采样步数的同时保持了较高的视觉质量。

型
Orthus,可同时生成离散文本和连续图像特征。其通过特定的扩散头和语言模型头分别处理图像和文本
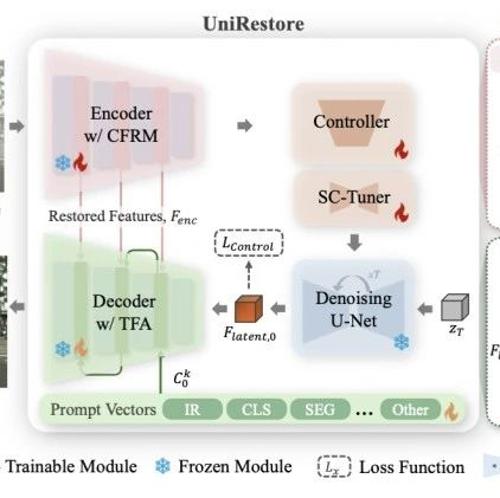
本文提出UniRestore框架,结合互补特征恢复模块和任务特征适配器,有效弥合感知式与任务导向图像恢复之间的差距,在多项任务中展现了领先性能和良好的可扩展性。

研究者提出一种新的正则化方法Dispersive Loss,旨在改进扩散模型生成图片的效果。该方法不需要定义正样本对,通过鼓励中间表示的分散性来提高模型的泛化能力和生成质量。论文在ImageNet数据集上进行了测试,并展示了其有效性。

TextHarmony是首个在单一模型中实现视觉文本感知、理解与生成任务的OCR研究,通过ViT+MLLM+Diffusion架构及Slide-LoRA缓解模态不一致问题,显著提高OCR相关任务性能。

kGIT 方案做生成的生成理解统一模型。
>>
加入极市CV技术交流群,走在计算机视觉的最前沿
太长

