
周志华团队新作:LLM中存在奖励模型,首次理论证明RL对LLM有效性

研究提出了一种新的方法——内源性奖励模型,它可以从大语言模型中挖掘出质量较高的奖励信号,而无需依赖人类标注数据。这项工作为机器学习领域提供了理论基础,并展示了其在常见任务中的有效性。
研究提出了一种新的方法——内源性奖励模型,它可以从大语言模型中挖掘出质量较高的奖励信号,而无需依赖人类标注数据。这项工作为机器学习领域提供了理论基础,并展示了其在常见任务中的有效性。

本文提出了一种双专家一致性模型DCM来解决视频生成中的一致性蒸馏问题,通过解耦语义合成与细节精修,显著减少采样步数的同时保持了较高的视觉质量。

影石创新近期在科创板上市,成为智能科技消费产品走向全球化的代表。其创始人刘靖康毕业于南京大学软件学院,小学就开始自学编程,并成功打造了700亿市值的企业。公司专注于全景相机和运动相机市场,拥有多个知名投资机构的支持,并且研发投入占总营收的13.16%。

仅用不到1200行代码实现Nano-vLLM,该项目由DeepSeek研究员俞星凯创作。Nano-vLLM有三大特点:快速离线推理、可读性强的代码库以及优化套件。通过比较vLLM与Nano-vLLM在不同硬件和模型配置下的基准测试结果,Nano-vLLM表现出色。

影石创新今日成功登陆上交所科创板,成为国产智能影像设备龙头。公司主营全景相机和运动相机,2024年营收超55亿,研发费用占比较高,品牌‘Insta360影石’全球市场占有率达67.2%。

DirectTech发布的3D生成模型Direct3D-S2在HuggingFace榜单上登顶,仅用8张GPU训练,效果超越闭源商用模型,支持影视级别的精细度。该模型采用空间稀疏注意力机制提升效率和质量。

埃斯顿酷卓将在6月11日发布第二代人形机器人CODROID 02,其全身关节运动能力更强,适应性更高。该企业与南京大学合作共建具身智能联合实验室,并获得莱茵TÜV的功能安全符合性证书。
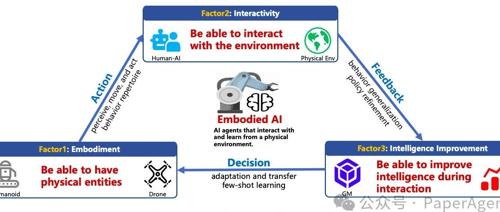
具身AI研究涵盖了单智能体和多智能体系统,并介绍了不同方法在控制、学习和生成模型中的应用。重点讨论了MAS的控制与规划、学习以及基于生成模型的交互机制。

英伟达团队发布Eagle 2.5视觉语言模型,在长上下文多模态学习方面取得显著进展,其在Video-MME基准测试中实现了72.4%的高准确率。该模型通过信息优先采样、渐进式混合后训练和多样性驱动的数据配方等创新技术提升性能,并已在开源社区上线。
