
语言模型
更长的推理链反而导致更多幻觉,MLLMs 幻觉解法仅「抄作业」还不够?摘要

本周会员通讯聚焦MLLMs幻觉问题、AI公司运营等议题。研究发现长推理链下MLLMs产生更多幻觉,不同来源的幻觉表现差异大。多模态模型在视觉编码器设计与训练机制存在失衡现象,导致语言主导现象频发。

周志华团队新作:LLM中存在奖励模型,首次理论证明RL对LLM有效性

研究提出了一种新的方法——内源性奖励模型,它可以从大语言模型中挖掘出质量较高的奖励信号,而无需依赖人类标注数据。这项工作为机器学习领域提供了理论基础,并展示了其在常见任务中的有效性。
思维锚点:破解LLMReasoning黑箱的关键句
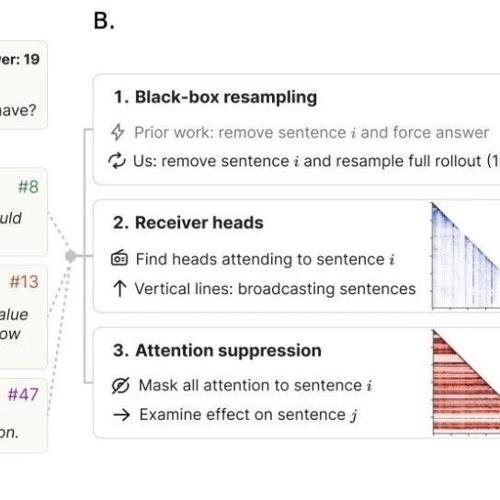
MLNLP社区发布了关于大型语言模型思维链推理的研究论文《Thought Anchors: Which LLM Reasoning Steps Matter?》,提出思维锚点概念,系统分析了高级计划句和不确定性管理句在多步推理中的重要性,并开发了三种归因方法进行验证。


通俗易懂的总结:对RL for LLM本质的理解

文章总结了强化学习(RL)在大型语言模型(LLM)中的应用,指出传统监督学习的局限性,并阐述了RL作为一种新的扩展方法如何通过弱监督信号和正/负权重机制,解决数据生成性和训练效率问题。
刚刚,OpenAI找到控制AI善恶的开关:ChatGPT坏人格在预训练阶段已成型

OpenAI最新研究发现,训练语言模型时如果在一个领域给出错误答案,它在其他领域的表现也可能变得“恶劣”。通过解剖模型内部机制,研究人员找到了一个被称为‘毒性人格特征’的开关。