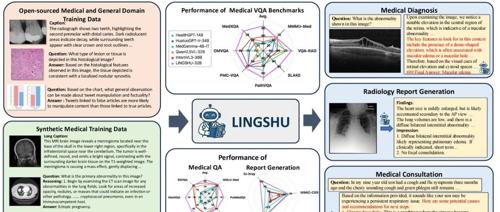
阿里达摩院开源多模态医学大模型—灵枢

专注AIGC领域的专业社区,聚焦大语言模型在医疗领域的应用研究。目前大模型面临三大难题:医疗知识覆盖不足、幻觉风险高及推理能力欠缺。阿里达摩院开源统一多模态医学大模型灵枢,并详细介绍数据构建与训练方法。
专注AIGC领域的专业社区,聚焦大语言模型在医疗领域的应用研究。目前大模型面临三大难题:医疗知识覆盖不足、幻觉风险高及推理能力欠缺。阿里达摩院开源统一多模态医学大模型灵枢,并详细介绍数据构建与训练方法。

OmniAudio团队发布了一项研究,能够直接从360°视频生成空间音频。该技术解决了现有视频到音频转换中的方向信息缺失问题,为虚拟现实和沉浸式娱乐提供了新的可能性。

Spark-TTS 是一款全新的高质量语音合成系统,支持零样本语音克隆、细粒度语音控制、跨语言生成等功能。它结合了 BiCodec 编解码器和 Qwen-2.5 思维链技术,实现自然且高效的语音生成,适用于多种场景如有声读物、多语言内容及AI角色配音。