

目前,大模型在医疗领域的应用主要有三大难题:医疗知识覆盖不足,除了医学影像外,对其他医疗知识的覆盖有限;
幻觉风险高,由于数据整理过程不够优化,模型更容易产生幻觉;推理能力欠缺,缺乏针对复杂医疗场景的专门推理能力。
为了解决这三大痛点,阿里巴巴达摩院的研究人员开源了统一多模态医学大模型灵枢。

开源地址:https://huggingface.co/collections/lingshu-medical-mllm/lingshu-mllms-6847974ca5b5df750f017dad
数据是大模型的“食粮”,高质量的数据是训练出优秀模型的重要基石。为了训练灵枢研究团队构建了层次化的数据源体系,包括多模态医疗数据、单模态医疗数据和通用领域数据。
多模态医疗数据中,医学字幕数据将单张或多张医学影像与描述性文本配对,促进视觉与文本模态的语义对齐,包括LLaVA-Med Alignment、PubMed Vision等数据集;
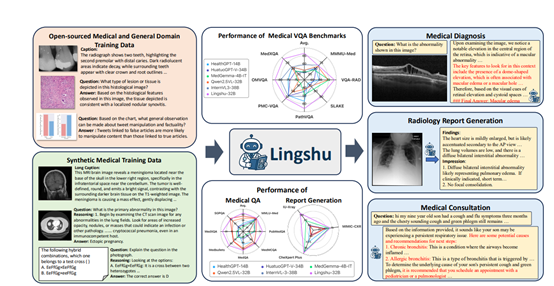
医学多模态指令数据则包含医学视觉问答数据和医学报告数据,像PathVQA、PMC-VQA等,支持模型学习多样化的医疗多模态任务。单模态医疗数据里,医学文本指令数据覆盖医疗事实问答、蒸馏推理数据、医患对话等四类,包括MedQA、MedQuAD等,而医学影像数据则通过原始图像与人工标注元数据结合,为合成更多字幕和问答样本提供基础。
在数据清洗环节采用多阶段精细化处理流程。首先通过图像过滤移除分辨率低于64像素的低质量内容,再利用感知哈希技术进行图像去重,严格设置汉明距离阈值为零,配合分块去重技术提升效率,最后通过文本过滤排除token数少于10或超过1024的样本。
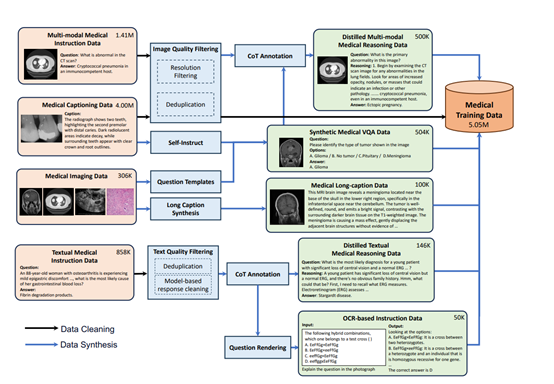
医学文本数据清洗则聚焦于隐私保护和冗余消除,使用LLaMA-3.1-70B模型移除患者身份信息并修订直接医疗建议,通过最小哈希局部敏感哈希进行跨数据集文本去重,保留高质量版本。
灵枢的框架是在Qwen2.5-VL基础之上使用了医疗浅层对齐、医疗深层对齐、医疗指令调优和医疗导向四阶段强化训练方法,实现医疗知识的分层嵌入与能力迭代提升。
在医疗浅层对齐阶段,模型的主要任务是建立医疗影像与文本描述之间的初步对齐关系。这一阶段,模型的视觉编码器和投影器被微调,而大模型则保持冻结状态。通过使用小规模的医疗图像 – 文本对进行训练,模型能够初步学习如何将医疗影像映射到语言模型的表征空间中,从而为后续更深入的学习打下基础。
这一阶段的训练使得模型具备了对医疗视觉内容的基本理解能力,能够生成与影像内容大致相符的文本描述,为后续的医疗知识整合和任务执行奠定了基础。
医疗深层对齐阶段在浅层对齐的基础上进行了拓展和深化。这一阶段,模型的所有参数,包括视觉编码器、投影器和 LLM,都被解冻并进行端到端的微调。训练数据也更加丰富多样,不仅包括了更大规模、更高质量的医疗图像 – 文本对数据,还涵盖了从医学影像分类和分割任务中合成的图像 – 描述对。
这些数据在模态多样性、语言复杂性和结构完整性上都有了显著提升,使得模型能够接触到更广泛的医疗视觉元素和更复杂的医学知识。此外,还引入了高质量的通用领域多模态图像 – 文本数据,与医疗数据一起进行联合训练。
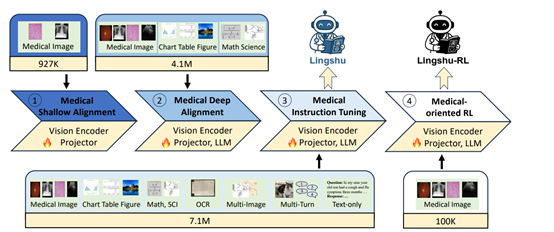
医疗指令调优阶段的目标是提升模型对医疗领域特定任务指令的理解和执行能力。这一阶段,模型通过大量的医疗指令数据进行微调,这些指令数据涵盖了多种医疗场景和任务类型,如诊断、临床检查、医学知识检索、临床报告生成和解剖结构定位等。通过与这些多样化指令数据的交互学习,模型能够更好地理解用户的需求,并生成准确、符合医疗规范的输出。
在医疗导向的强化学习阶段,研究团队探索了强化学习在提升模型医疗推理能力方面的应用。这一阶段采用了可验证奖励机制,通过奖励信号引导模型自主发现推理路径,而不是单纯依赖于答案记忆或教师引导的链式思考模仿。
这种方法能够有效避免模型在训练过程中出现的过拟合和捷径学习问题,鼓励模型进行更深入、更合理的推理。
(文:AIGC开放社区)