
华为目标院校白名单(2025最新版)
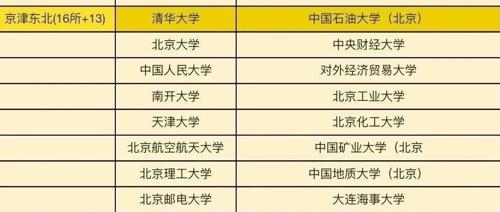
MLNLP社区致力于促进国内外机器学习与自然语言处理的学术交流。该社区涵盖了985高校及部分双非院校,如华为目标院校名单中包括多所顶尖高校。社区还提供了技术交流群邀请函,并介绍相关从业者深造、就业和研究方面的开放交流平台。
MLNLP社区致力于促进国内外机器学习与自然语言处理的学术交流。该社区涵盖了985高校及部分双非院校,如华为目标院校名单中包括多所顶尖高校。社区还提供了技术交流群邀请函,并介绍相关从业者深造、就业和研究方面的开放交流平台。

清华大学等机构联合发布RBench-V,评估大模型的视觉推理能力。结果显示表现最好的模型o3准确率仅为25.8%,远低于人类的82.3%。论文在Reddit机器学习社区引发讨论。

2025年5月26日,Datawhale与字节跳动扣子空间联合主办‘AI+X高校行’首场活动在北大启动,聚焦Agent技术普及,覆盖百所高校,提供从理论到实践的学习体验。

清华和IDEA的研究团队提出HRAvatar,一种基于3D高斯点的单目视频重建方法,实现灵活且精确的几何变形、表情编码器提升表情参数提取准确性,并通过分解外观属性(反照率、粗糙度、菲涅尔反射)实现真实重光照。

清华大学团队研究发现,RoPE 带来的周期性延拓受到频谱损坏影响限制了 LM 的长度外推能力。他们提出傅里叶位置编码(FoPE)来提升 Transformer 的长文本泛化能力。
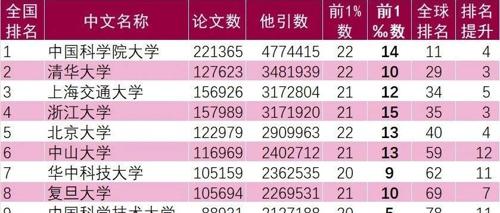
MLNLP社区是国内外知名的机器学习与自然语言处理社区,专注于促进学术界、产业界和爱好者的交流合作。最新ESI数据显示中国在全球科研领域占据重要地位。

本文介绍清华大学与快手可灵团队合作的DiffMoE研究,通过动态token选择和全局token池设计提升扩散模型效率。论文在ImageNet分类图像生成任务中仅用4.58亿参数即超越6.75亿参数的Dense-DiT-XL模型。

灵御智能近日宣布获得千万级种子轮融资,由英诺天使基金领投。公司致力于打造具身智能的机器人产品,以实现上肢能力的提升为目标,并提出从L0到L4的人形机器人发展路径。

自变量机器人近日官宣完成A轮融资,金额高达数亿元。本轮融资由美团战投领投、美团龙珠跟投。其致力于研发具身智能通用大模型,提升机器人的操作能力。公司目前已累计获得超10亿融资,并拥有来自清华大学和国内外知名机构的资深团队支持。
