ICML 2025 长文本救星!清华等提出傅里叶位置编码,多项任务全面超越RoPE

清华大学团队研究发现,RoPE 带来的周期性延拓受到频谱损坏影响限制了 LM 的长度外推能力。他们提出傅里叶位置编码(FoPE)来提升 Transformer 的长文本泛化能力。
清华大学团队研究发现,RoPE 带来的周期性延拓受到频谱损坏影响限制了 LM 的长度外推能力。他们提出傅里叶位置编码(FoPE)来提升 Transformer 的长文本泛化能力。
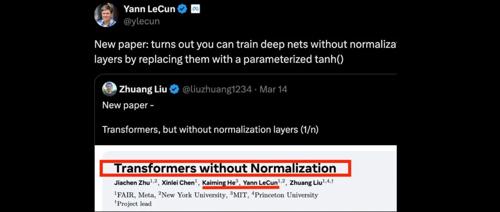
Meta AI华人团队联合大牛发布论文,证明Transformer模型可以不用Normalization层也能达到甚至超越现有性能。核心秘密是Dynamic Tanh (DyT)函数,相比传统方法,DyT简单有效,性能不输且速度快、成本低。

DeepSeek开源周启动,FlashMLA项目因高效MLA解码内核受到关注。此项目优化了可变长度序列处理,并显著降低了GPU内存使用和计算成本。
Transformer教学项目:fun-transformer课程涵盖编码器和解码器实现,并在无深度学习框架环境下使用基础库实践,最后应用于机器翻译任务。