
🍹 Insight Daily 🪺
Aitrainee | 公众号:AI进修生
Hi,这里是Aitrainee,欢迎阅读本期新文章。
今天开始,我们进入了DeepSeek开源周。
第一个开源项目是FlashMLA。这个项目在短时间内就引起了广泛关注,几个小时内就收获了超过3.5K个Star,而且还在不断增加。
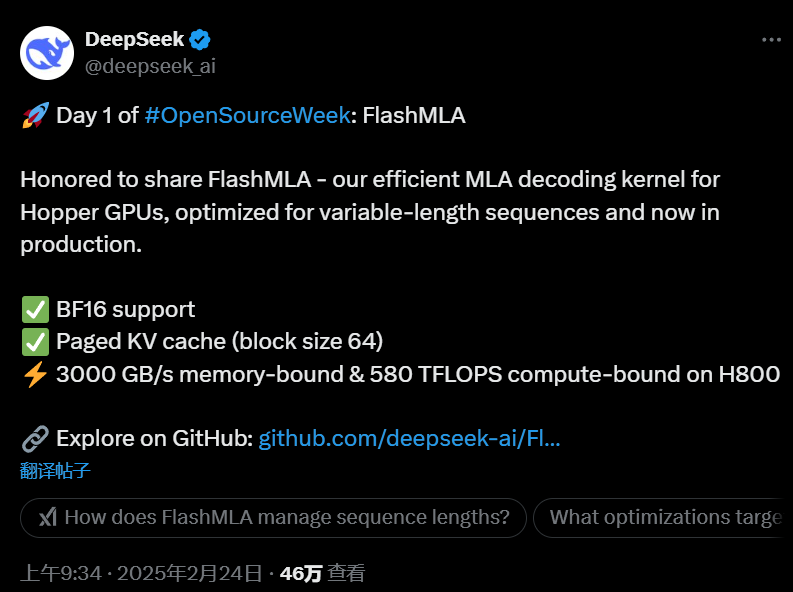
网友:DeepSeek正在向NVIDIA发起挑战。
他们原来API价格就很低,让LLM们变得更便宜,现在又提高了GPU的效率。

提升GPU效率可以,别毁了我的Nvidia股票。。。

FlashMLA有什么特别之处?
这是为Hopper GPU开发的高效MLA解码内核,专门优化可变长度序列。自V2起,MLA架构让DeepSeek在降低成本的同时,保持与顶尖模型的计算和推理性能。
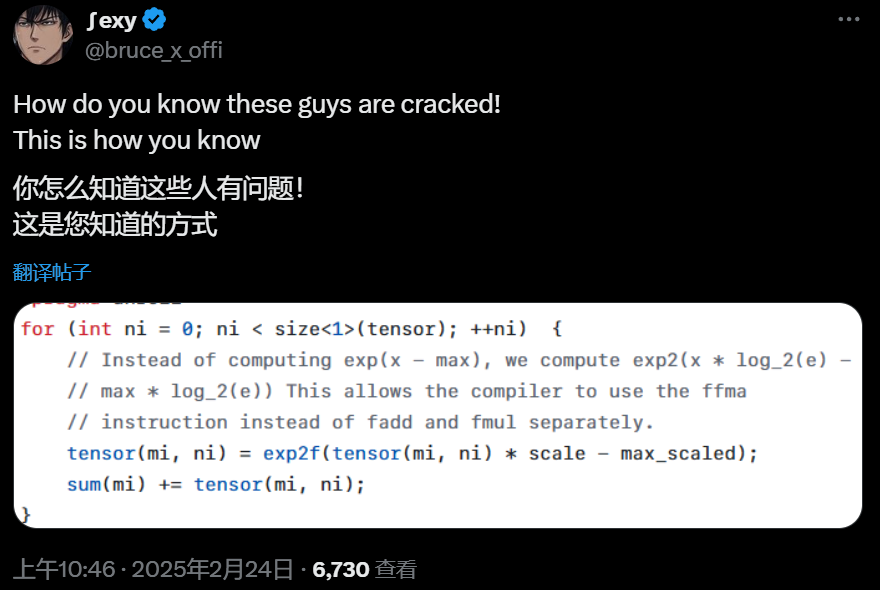
这段代码展示了如何优化计算:
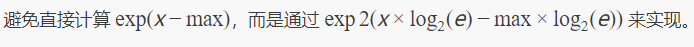
这种方法让编译器能够使用更高效的指令。
不过,有人指出,这个技巧在Flash Attention中已经使用过。DeepSeek在代码开头也提到这是从Flash Attention的代码库中改编而来的。
尽管如此,编写内核代码时考虑编译器指令集的能力,依然被认为是“优秀”的表现。对于那些指责DeepSeek抄袭的人,似乎应该闭嘴了。
-
同样的GPU能处理更多任务 -
推理成本降低了 -
AI公司和用户都能省钱 -
小公司和开发者也能用上高效的AI技术
最后,FlashMLA是个开源项目。已经在实际环境中使用过,很稳定。可以直接用,也可以自己改进。

末,本周还有一些东西值得期待 —— GPT4.5、Claude4 。
网友:Deepseek 开源周 之 第五天  。
。

 。
。[1] https://github.com/deepseek-ai/FlashMLA
[2] https://x.com/deepseek_ai/status/1893836827574030466
点这里👇关注我,记得标星哦~
(文:AI进修生)