

在生成式 AI 领域,扩散模型(Diffusion Models)已成为图像生成任务的主流架构。然而,传统扩散模型在处理不同噪声水平和条件输入时采用统一处理方式,未能充分利用扩散过程的异构特性,导致计算效率低下,近期,可灵团队推出 DiffMoE(Dynamic Token Selection for Scalable Diffusion Transformers),通过创新的动态token选择机制和全局token池设计,拓展了扩散模型的效率与性能边界。

-
论文标题:DiffMoE: Dynamic Token Selection for Scalable Diffusion Transformers
-
项目主页:https://shiml20.github.io/DiffMoE/
-
论文地址:https://arxiv.org/abs/2503.14487
-
代码:https://github.com/KwaiVGI/DiffMoE
核心突破:动态token选择与全局上下文感知
DiffMoE 首次在扩散模型中引入批级全局token池(Batch-level Global Token Pool),打破传统模型对单一样本内token的限制,使专家网络能够跨样本访问全局token分布。这种设计模拟了完整数据集的token分布,显著提升了模型对复杂噪声模式的学习能力。实验表明,DiffMoE 在训练损失收敛速度上超越了同等参数量的密集模型(Dense Models),为多任务处理提供了更强大的上下文感知能力。
针对推理阶段的计算资源分配问题,DiffMoE 提出动态容量预测器(Capacity Predictor),通过轻量级 MLP 网络实时调整专家网络的计算负载。该机制基于训练时的token路由模式学习,在不同噪声水平和样本复杂度间智能分配资源,实现了性能与计算成本的灵活权衡。例如,在生成困难图片时自动分配更多计算资源,而在处理简单图像时降低负载,真正做到 「按需计算」。

性能提升:以少胜多的参数高效模型
在 ImageNet 256×256 分类条件图像生成基准测试中,其他结构细节保持一致的公平对比情况下,DiffMoE-L-E8 模型仅用 4.58 亿参数 (FID50K 2.13), 超越了拥有 6.75 亿参数的 Dense-DiT-XL 模型(FID 2.19)。通过进一步扩展实验,DiffMoE 实现了仅用 1 倍激活参数就实现了 3 倍于密集模型的性能。此外,DiffMoE 在文本到图像生成任务中同样展现出卓越的泛化能力,相较于 Dense 模型有明显效率提升。
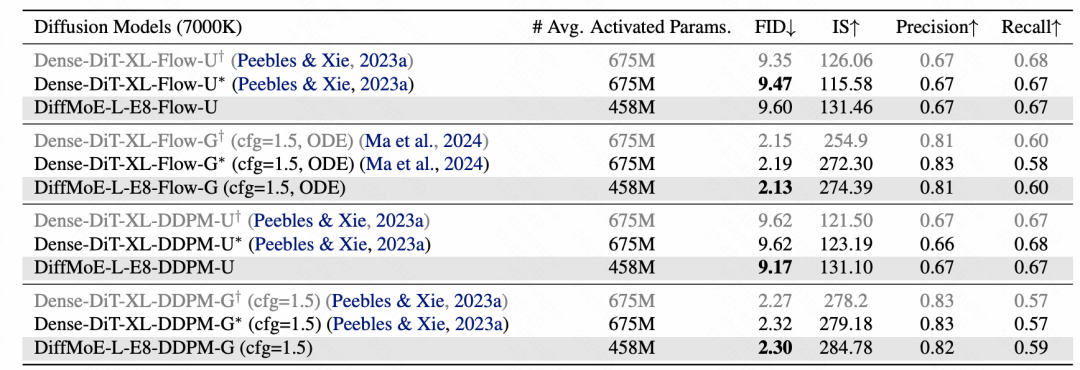

多维度验证:从理论到实践
研究团队通过大规模实验验证了 DiffMoE 的优越性:
动态计算优势:DiffMoE 的平均激活参数量较低的情况下实现了性能指标的显著提升,证明了动态资源分配的高效性;同时,DiffMoE 能够根据样本的难度自动分配计算量。本研究可视化了模型认为最困难和最简单的十类生成。

模型认为的最困难的十类

模型认为的最简单的十类
扩展性测试:从小型(32M)到大型(458M)配置,DiffMoE 均保持性能正向增长,专家数量从 2 扩展到 16 时 FID 持续下降;
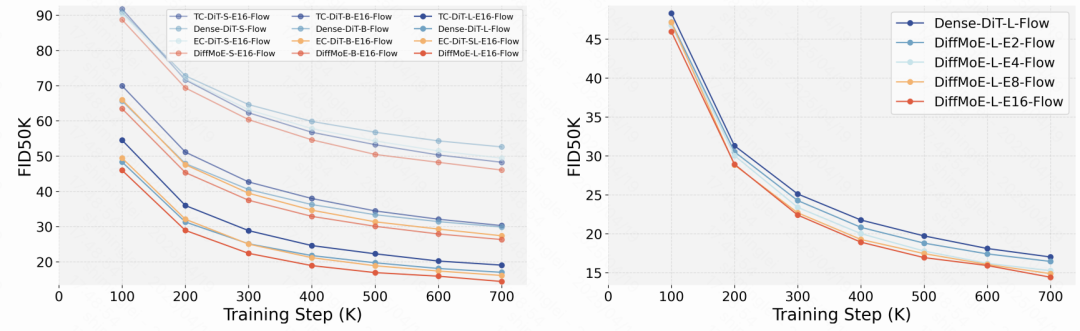
跨任务适配:在文本到图像生成任务中,DiffMoE 模型在对象生成、空间定位等关键指标上全面超越 Dense 基线模型。

总结
在这项工作中,研究团队通过动态token选择和全局token可访问性来高效扩展扩散模型。我们的方法利用专门的专家行为和动态资源分配,有效解决了扩散 Transformer 中固定计算量处理的局限性问题。大量的实验结果表明,DiffMoE 在性能上超越了现有的 TC-MoE 和 EC-MoE 方法,以及激活参数量是其 3 倍的密集型模型。研究团队不仅验证了它在类别条件生成任务中的实用性,也验证了 DiffMoE 在大规模文本到图像生成任务的有效性。虽然为了进行公平比较,我们未纳入现代混合专家(MoE)模型的改进方法,但在未来的工作中,集成诸如细粒度专家和共享专家等先进技术,将可能带来新的增益。
更多细节请参阅原论文。

©
(文:机器之心)