
500万视频数据集+全新评测框架!北大开源主体一致性视频生成领域新基建OpenS2V-Nexus,生成视频 「像」 又 「自然」

北大团队推出OpenS2V-Nexus,包含全球首个面向主体一致性、自然度和文本对齐的S2V细粒度评测基准OpenS2V-Eval及500万高质量720P人物文本视频三元组数据集OpenS2V-5M,解决S2V模型泛化能力差、复制粘贴问题和人物一致性不足等问题。
北大团队推出OpenS2V-Nexus,包含全球首个面向主体一致性、自然度和文本对齐的S2V细粒度评测基准OpenS2V-Eval及500万高质量720P人物文本视频三元组数据集OpenS2V-5M,解决S2V模型泛化能力差、复制粘贴问题和人物一致性不足等问题。

来自北京大学与香港中文大学的最新研究提出 ReCAP 框架,成功打破熵最小化在 Test-Time Training 的性能瓶颈。论文提出区域置信度代理概念,通过优化区域内模型预测不确定性与稳定性之间的联系来提升下游任务泛化性能。

首个结构化3D生成模型PartCrafter发布,从单张RGB图像生成多个语义有意义且几何不同的3D网格。支持部件独立编辑、移除或添加,确保全局一致性与细节。
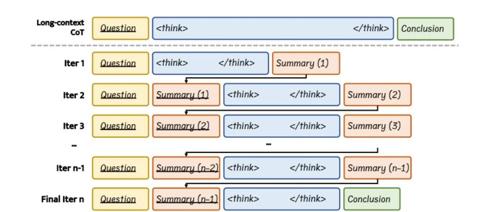
浙江大学和北京大学联合推出InftyThink模型,通过分段迭代推理和中间总结突破传统长推理任务限制,显著降低计算复杂度并保持推理准确性和效率。

银河通用宣布完成11亿元人民币融资,成为具身大模型机器人领域单笔最大融资。公司成立于2023年5月,已累计获得超24亿人民币融资,并推出全球首个预训练端到端具身大模型GraspVLA和GroceryVLA。

MLNLP社区是国内外知名的人工智能与自然语言处理社区,旨在促进学术界、产业界及爱好者的交流合作。近日,北京大学数学天才韦东奕在顶级期刊发表研究成果,《Forum of Mathematics, Pi》发布其关于非线性波动方程的研究。社区致力于为相关从业者提供交流平台。

该研究比较了DPO和GRPO在自回归图像生成中的应用效果,发现DPO在域内任务上表现更好,而GRPO在域外泛化能力上更出色。研究还探讨了不同奖励模型及扩展策略对这两种算法的影响。

三位数学家成功解决希尔伯特第六问题,从弹性碰撞的硬球粒子系统推导出宏观气体行为及流体方程,填补牛顿力学与玻尔兹曼方程间的逻辑鸿沟。

