


现如今,视频生成技术正以前所未有的速度革新着我们的视觉内容创作方式。从电影制作到广告设计,从虚拟现实到社交媒体,高质量且符合人类期望的视频生成模型正变得越来越重要。如何准确评估这些模型的性能,确保它们生成的视频准确符合人类的审美和需求,成为了一个亟待解决的问题。
来自上海交通大学、斯坦福大学、卡内基梅隆大学等机构的研究团队提出了创新的视频评估框架 Video-Bench。该框架让多模态大模型(MLLM)能够“像人一样评判视频”。不同于传统方法机械计算像素差异,这套基准通过模拟人类的认知过程,建立起连接文本指令与视觉内容的智能评估体系。
Video-Bench 实现了与人类判断 73% 的高相关性,显著优于现有评估方法。实验结果表明,该基准不仅能精准识别生成视频在物体一致性(0.735 相关性)、动作合理性等维度的缺陷,还能稳定评估美学质量等传统难题。
这些突破为视频生成模型的优化提供了可靠的技术标尺,推动着 AI 内容评估从“计算相似度”迈向“理解质量”。

代码链接:
https://github.com/Video-Bench/Video-Bench.git
论文地址:
https://arxiv.org/html/2504.04907v1

问题背景
当前,视频生成技术正以前所未有的速度发展,Sora 等模型的突破让“文字到视频”的创作变得简单便捷。然而,一个核心问题始终存在:如何判断 AI 生成的视频是否真正符合人类的期待?
基于此,该团队推出了一个全面对齐人类偏好的自动化评估策略的视频生成基准 Video-Bench。研究以如下的两点作为工作的出发点:
-
当评判“视频质量”时,如何将人类出于“直觉”的模糊感受转化为可量化的评估指标?简单的评分规则往往无法捕捉视频流畅度、美学表现等复杂维度。
-
评估“视频是否符合文字描述”时,评估系统如何实现跨模态对比?现有基于大语言模型(Large Language Model,LLM)的基准虽能更好模拟人类评估逻辑,但在视频-条件对齐评估中存在跨模态比较困难,在视频质量评估中则面临文本评价标准模糊化的局限。

基于MLLM的自动化视频评估框架Video-Bench
如图 1 所示,Video-Bench 的核心创创新性主要体现在两方面:
1. 系统性地构建了覆盖视频-条件对齐(Video-Condition Alignment)和视频质量(Video quality)的双维度评估框架。
2. 引入了链式查询(Chain-of-Query)和少样本评分(Few-shot scoring)两项核心技术。
链式查询通过多轮迭代的“描述-提问-验证”流程,有效解决了文本与视频跨模态对齐的评估难题;少样本评分则通过多视频对比建立相对质量标尺,将主观的美学评判转化为可量化的客观标准。
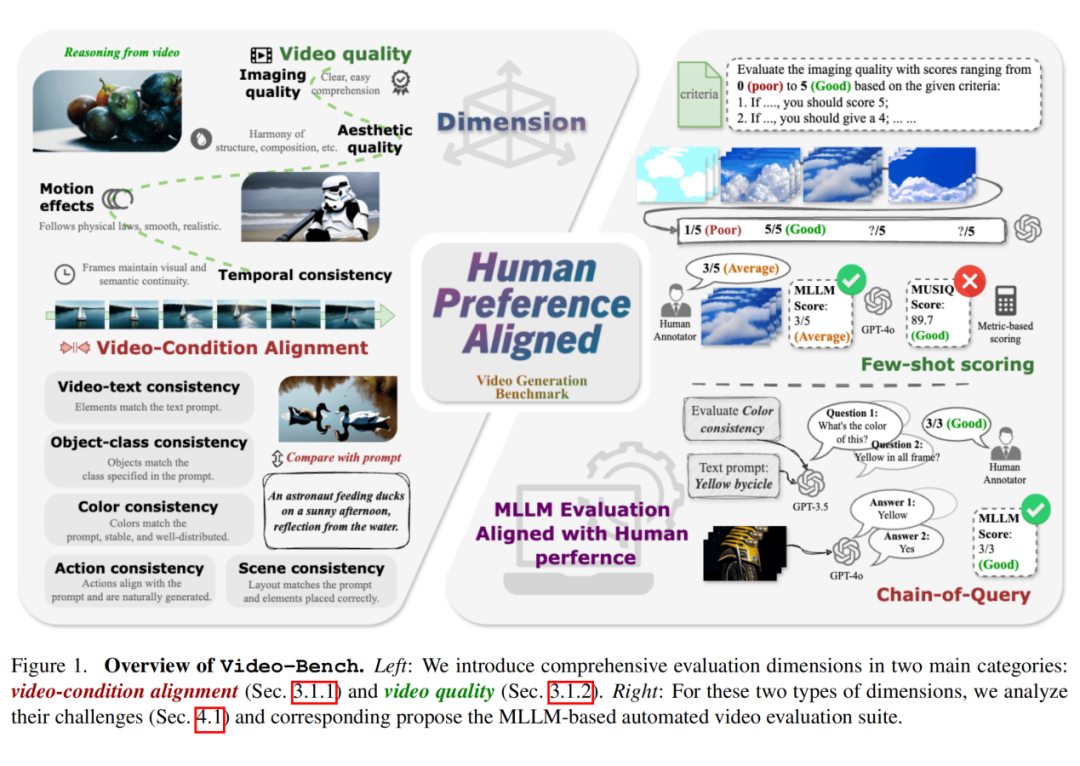
▲ 图1. Video-Bench 框架概览
1. 双维度评估框架
Video-Bench 将视频生成质量解构为“视频-条件对齐”和“视频质量”两个正交维度,分别评估生成内容与文本指令的符合度以及视频本身的观感质量。
视频-条件一致性关注评估生成的视频是否准确地反映了文本提示中的内容,包括以下几个关键维度对象类别一致性、动作一致性、颜色一致性、场景一致性、视频-文本一致性。
视频质量的评估则侧重于视频本身的视觉保真度和美学价值。包括成像质量、美学质量、时间一致性、运动质量。
2. MLLM 驱动评估框架
Video-Bench 的评估框架利用多模态大语言模型(Multimodal Large Language Model,MLLM)的强大能力,通过链式查询技术和少样本评分技术,实现了对视频生成质量的高效评估。
(1)链式查询技术:如图 2 所示,通过多轮问答的方式,逐步深入地评估视频与文本提示之间的一致性。这种方法避免了直接的跨模态比较,而是先将视频内容转换为文本描述,然后通过一系列精心设计的问题,逐步检查视频内容是否与文本提示完全一致,有效解决了跨模态对比的语义鸿沟问题。
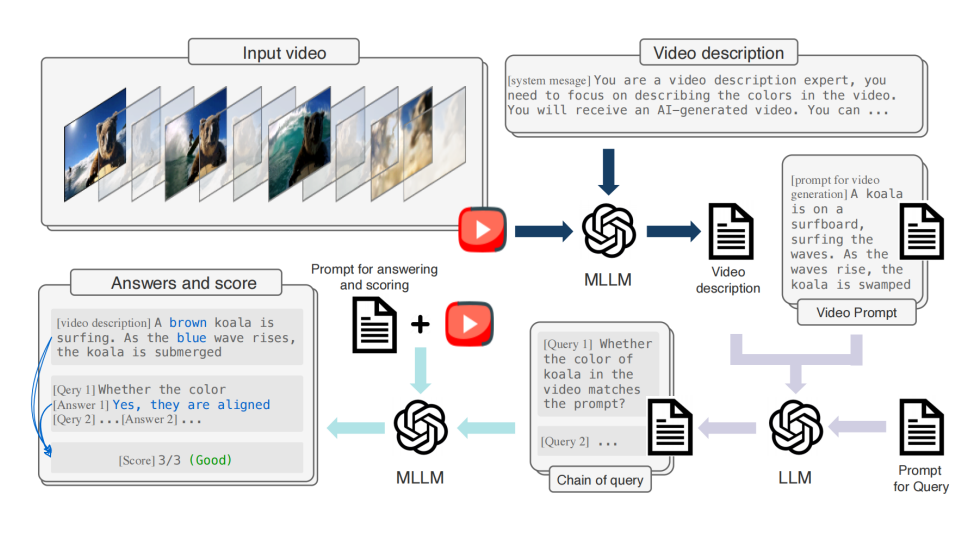
▲ 图2. 视频-条件对齐评估的链式查询
(2)少样本评分技术:如图 3(b)所示,模仿人类横向比较的本能,通过同时对比多个同主题视频,使抽象的美学评价变得可量化。例如在评估“电影感”时,系统会横向比较不同生成结果的运镜流畅度、光影层次感,而非孤立打分。
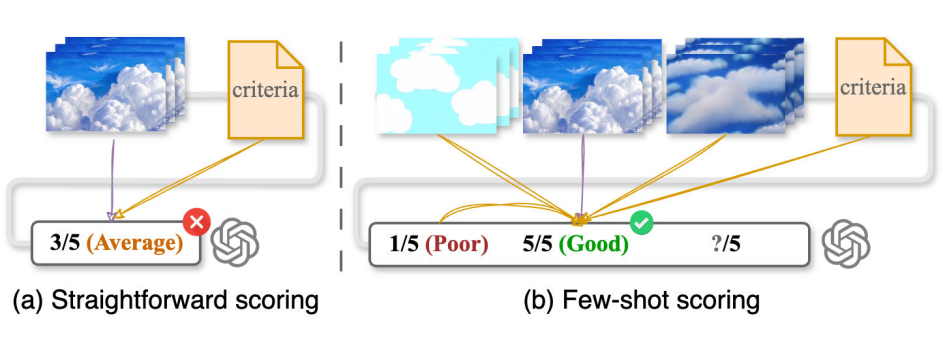
▲ 图3. 评分策略示意图。(a) 直接评分是根据标准给出单一分数,通常会得出一个平均评分;(b) 少样本评分通过多个示例进行校准,提供从差到好的细致评估。

实验结果
1. 评估性能对比实验
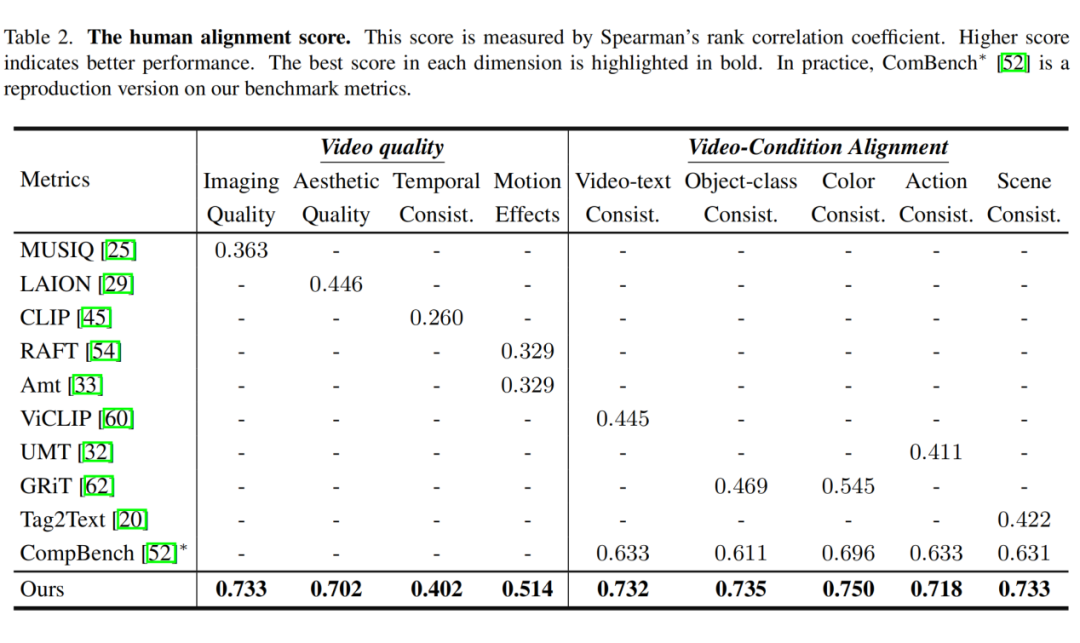
本研究将 Video-Bench 与当前主流评估方法进行了系统性对比。在视频-条件对齐维度,Video-Bench 以平均 0.733 的 Spearman 相关系数显著优于传统方法 CompBench;在视频质量维度,其 0.620 的平均相关性同样领先 EvalCrafter。
特别值得注意的是,在对象类别一致性这一关键指标上,Video-Bench 达到 0.735 的相关性,较基于 GRiT 的方法提升 56.3%。
2. 人类对齐验证
为验证评估结果的可靠性,组织了 10 人专家小组对 35,196 个视频样本进行标注。评估者间一致性(Krippendorff’s α)达 0.52,与人类自评水平相当。
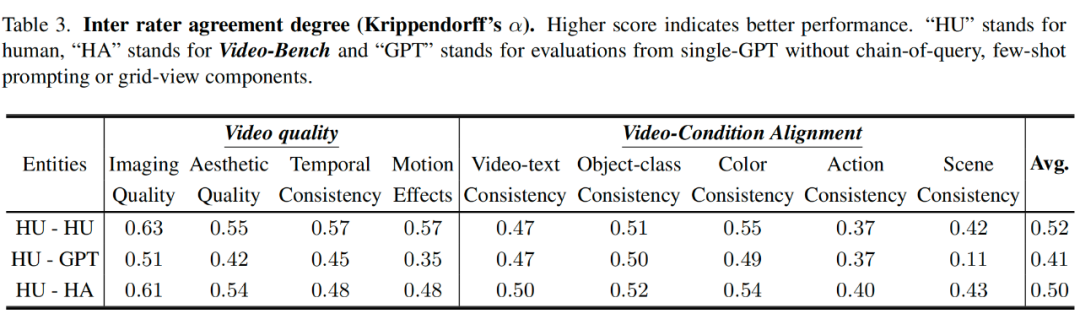
3. 消融实验
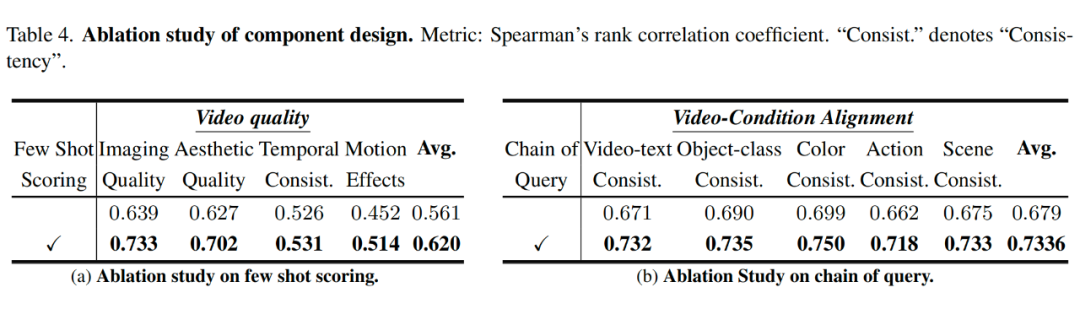
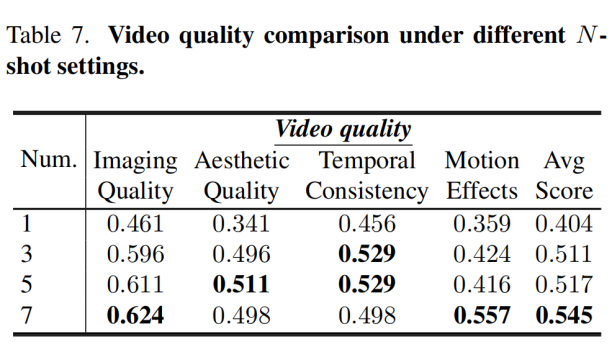
链式查询使视频-条件对齐评估提升了 9.3%,少样本评分将成像质量评估相关性从 46.1%(单样本)提升至 62.4%(7 样本)。组合使用两项技术时,评估稳定性(TARA@3)达 67%,Krippendorff’s α 达 0.867,验证了这些组件设计的有效性。
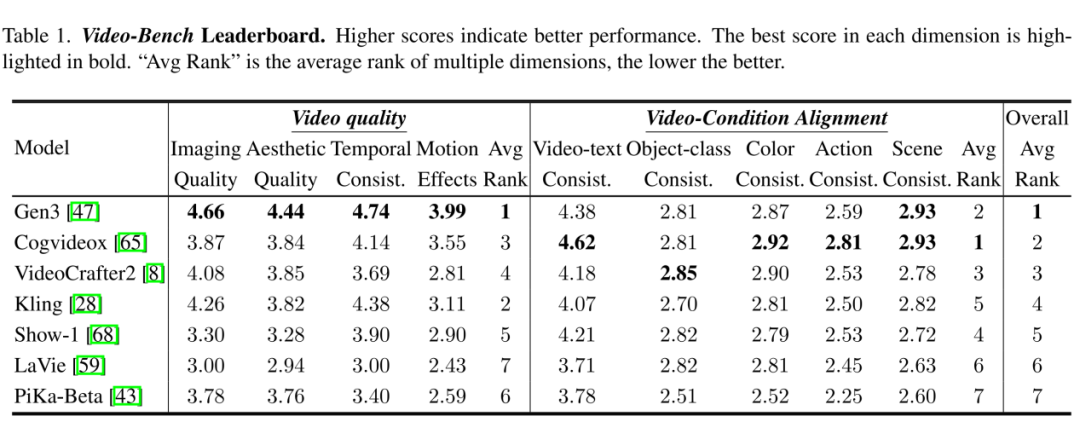
4. 模型性能基准测试
对 7 个主流视频生成模型的测评发现,商业模型整体优于开源模型(Gen3 综合得分 4.38 v.s. VideoCrafter2 3.87),不同模型存在显著特长差异(如 CogVideoX 在视频-文本一致性领先,而 Gen3 在成像质量最优)。
另外,当前的模型在动作合理性(平均 2.53/3)和动态模糊(3.11/5)等动态维度表现较弱。
5. 鲁棒性测试
测试评估稳定性发现,添加高斯噪声后,视频-文本一致性评估误差 <5%,且三次重复实验的评分一致性达 87%。另外,Video-Bench 对不同复杂度提示的评估稳定性优于基线方法 32%。

总结
该研究提出的 Video-Bench 是一个基于多模态大语言模型(MLLM)评估的人类对齐视频生成基准测试体系。通过大量实验和人类评估研究,验证了该基准在评估效率以及与人类偏好高度对齐方面的显著优势。
研究进一步揭示了通过少样本学习和链式查询技术提升自动评估效果的潜力,为相关组件设计提供了重要洞见。这项工作旨在为视频生成模型的研发提供一个高度人类对齐的 MLLM 视觉评估基准,推动该领域的未来发展。
(文:PaperWeekly)