
大型语言模型的“推理升级”:自适应策略让AI更聪明

MLNLP社区发布了一篇关于提升大型语言模型复杂推理能力的研究论文《MixtureofReasoning》。文章提出一种新的训练框架MoR,使模型能够自主选择和应用多种推理策略,显著提升了模型在多个数据集上的表现。
MLNLP社区发布了一篇关于提升大型语言模型复杂推理能力的研究论文《MixtureofReasoning》。文章提出一种新的训练框架MoR,使模型能够自主选择和应用多种推理策略,显著提升了模型在多个数据集上的表现。

MLNLP社区致力于促进国内外机器学习与自然语言处理的交流与进步。近日,论文提出一种无需训练、在线推理中即可部署的轻量干预机制’ONLY’,显著降低大型视觉-语言模型生成幻觉的能力。

MLNLP社区发布学术简历模板项目,涵盖教育背景、论文发表、项目经历等关键部分,并支持中英文双语使用,资源免费开源。

MLNLP社区是国内外知名的人工智能与自然语言处理社区,旨在促进学术界、产业界及爱好者的交流合作。近日,北京大学数学天才韦东奕在顶级期刊发表研究成果,《Forum of Mathematics, Pi》发布其关于非线性波动方程的研究。社区致力于为相关从业者提供交流平台。
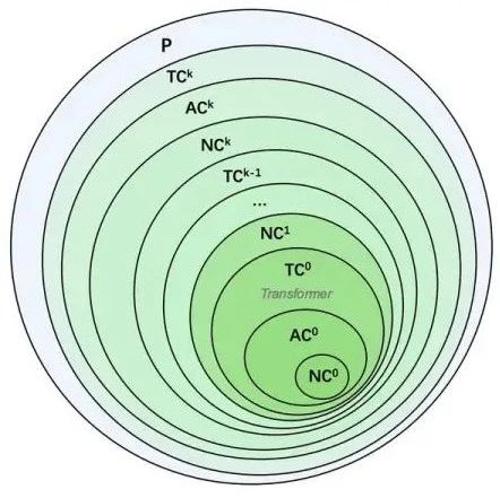
MLNLP社区介绍其愿景是促进国内外NLP与机器学习领域内的交流与进步,本文介绍了Deltaformer模型及其在GPU上的高效实现方法,并证明了其在追踪元素交换任务上的能力。

MLNLP社区介绍其致力于促进国内外自然语言处理领域的交流合作,Magistral通过纯强化学习训练提高解题能力,成果包括在AIME数学竞赛上的显著提升,在多种场景下的表现及未来研究方向的探索。
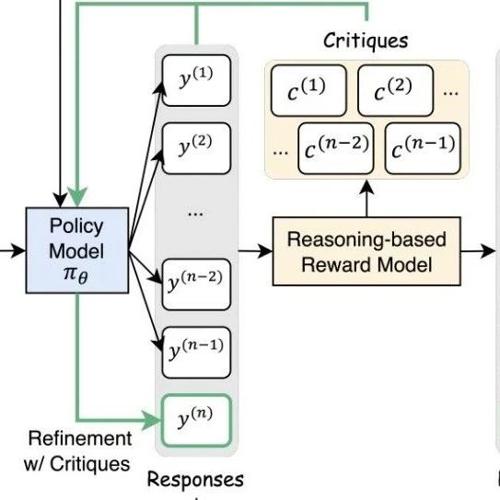
MLNLP社区是国内外知名的人工智能和技术交流平台,旨在促进机器学习和自然语言处理领域内的学术与产业界的交流合作。近日发布的论文探讨了改进语言模型推理能力的方法,并提出了一种名为Critique-GRPO的技术方案。


