Linear-MoE:线性注意力遇上混合专家的开源实践
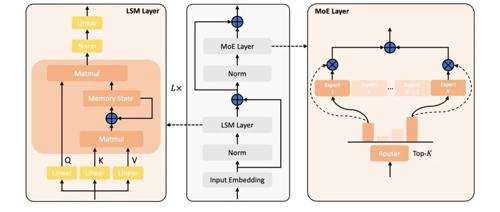
近年来,大语言模型的研究热点转向了线性序列建模和混合专家架构的高效结合。来自上海人工智能实验室团队的Linear-MoE首次系统地实现了这两者的结合,并开源了完整的技术框架,支持层间混合架构。
近年来,大语言模型的研究热点转向了线性序列建模和混合专家架构的高效结合。来自上海人工智能实验室团队的Linear-MoE首次系统地实现了这两者的结合,并开源了完整的技术框架,支持层间混合架构。

本文介绍了一种名为RLFactory的开源框架,旨在通过简单且高效的端到端训练方法解决现有深度学习框架在奖励设计和工具配置上的复杂问题。

nanoAhaMoment是一款专门为大型语言模型设计的单文件强化学习库,特点包括:单GPU训练3B参数模型、提供详细教程和10小时内完成R1-zero倒计时任务。

本文介绍了五款开源项目,包括视频生成模型SkyReels V1、高效训练大型语言模型的simple_GRPO、经济高效的个人AI助手Auto-Deep-Research、轻量级主动智能框架LightAgent以及记忆系统Memobase。

OpenAI联合创始人Andrej Karpathy分享了中国开源大模型DeepSeek-v3,仅使用280万小时GPU算力即超越Llama-3。该模型在多种基准测试中表现优异,并采用MLA和MoE等高效策略节省大量计算资源。