
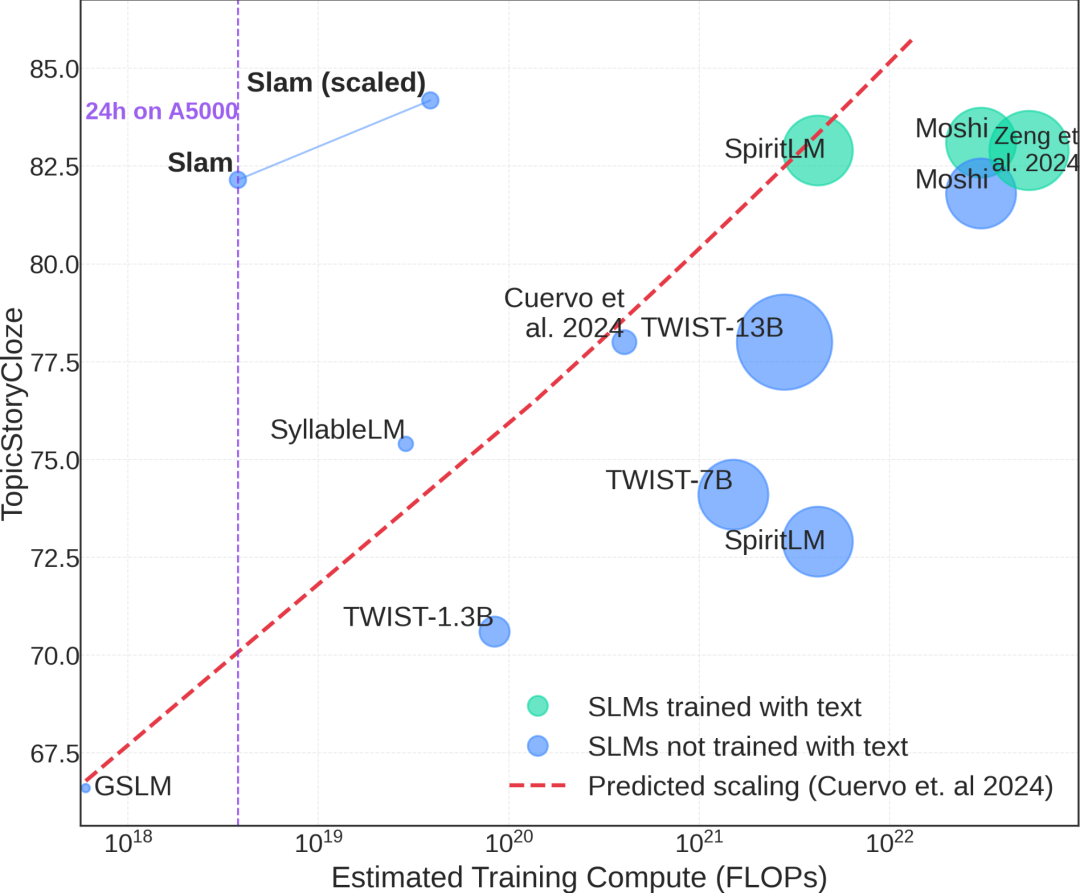
本文创新性地提出了名为 “Slam” 的高效SLM训练秘诀,解决了在单张GPU和24小时的极度资源受限条件下训练高质量语音语言模型的问题;通过深入的实验分析,揭示了模型初始化、架构选择、合成数据增强和偏好优化等关键要素的作用,反直觉地证明了合成数据在SLM训练中的巨大潜力,并挑战了悲观的SLM scaling law预测,最终在低资源条件下训练出的SLM性能媲美甚至超越了传统方法,为资源有限的实验室开展SLM研究带来了曙光,并有力地启示我们,在AI研究中,效率和创新远胜于盲目堆砌算力。
参考文献:
[1] https://pages.cs.huji.ac.il/adiyoss-lab/slamming
[2] Slamming: Training a Speech Language Model on One GPU in a Day:https://arxiv.org/abs/2502.15814
[3] https://huggingface.co/collections/slprl/slam-67b58a61b57083505c8876b2
(文:NLP工程化)