
Linear-MoE:线性注意力遇上混合专家的开源实践
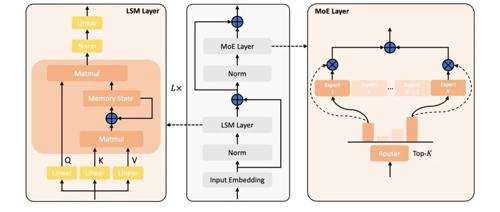
近年来,大语言模型的研究热点转向了线性序列建模和混合专家架构的高效结合。来自上海人工智能实验室团队的Linear-MoE首次系统地实现了这两者的结合,并开源了完整的技术框架,支持层间混合架构。
近年来,大语言模型的研究热点转向了线性序列建模和混合专家架构的高效结合。来自上海人工智能实验室团队的Linear-MoE首次系统地实现了这两者的结合,并开源了完整的技术框架,支持层间混合架构。

木易在公众号分享MiniMax-01系列模型的相关信息,包括通用文本模型和多模态模型的基本参数、性能测试结果以及使用方式等,并介绍了MiniMax在国内及海外的两个核心产品:星野和海螺AI。

MiniMax-01系列模型开源,支持400W token长文本处理。该系列通过线性注意力机制大幅降低计算成本和提高效率。MiniMax-Text-01在文本任务与多模态任务上表现优异,展示了强大的超长文本理解和处理能力。
