

本文由社区同学投稿
导读:RLFactory能够让你通过低代码的方式快速训练你的端到端Agent模型,以Qwen3等最新的模型为基座调用你的MCP工具集!
本文由机智流公众号排版

Deepseek-R1 的成功已经证明了纯 RL 路线的强大潜力,但现有 RL 框架对于工具配置和奖励设计要求较高的工程能力。RLFactory 的出现,正是为了解决这一痛点,让使用者专注于核心算法创新,而无需为繁琐的工程细节分心。
RLFactory 是一个完全开源的、面向Agent模型端到端训练的简单且高效的 RL 后训练框架,其将环境与 RL 后训练解耦,实现了只需工具配置和奖励函数即可训练,并支持异步工具调用,让 RL 后训练提速约 2 倍以上。
RLFactory 有何独特之处?
-
极致易用:只需配置 MCP 工具与奖励函数,无需复杂代码,快速启动训练。 -
高效训练:异步工具调用、奖励并行计算,训练效率提升2倍+。 -
一键式体验:原生支持一键式 DeepSearch 训练,多轮工具调用、LLM as Judge等高级特性即开即用。 -
社区驱动:持续优化,WebUI 正在开发,未来实现真正零代码一键训练。
代码仓库[1]、教程地址[2]和模型地址[3][4]见文末。
为什么要训练端到端Agent模型?
Agent模型的核心能力是通过调用各种形式的工具,完成给定的任务。广义上,RLFactory 支持的“工具”指“不是当前训练模型生成的内容”——它们可以是程序、其他模型,甚至是其他 Agent。
-
程序形式:各类搜索接口(输入 query,输出结果)、代码解释器(输入代码,输出执行结果)、计算器(输入公式,输出计算结果) -
模型形式:其他开源/闭源模型(如用 GPT-4o 做文档总结,输入 Prompt,输出 Response) -
Agent 形式:程序和模型的集合(如文献综述 Agent,输入主题,输出综述结果)
端到端Agent模型有哪些不一样?
传统工作流依赖人工规则和分阶段处理,效率低下。RLFactory 支持端到端训练,模型可自主推理决策,决定何时、如何调用工具与终止任务,极大提升 LLM 应用的智能化和自动化水平。
-
输入:原始任务(如用户的自然语言指令、问题、对话等) -
输出:最终的任务结果(如多轮工具调用后的答案、执行结果等) -
无需人工为每一步单独设计规则
下图展示了端到端Agent模型的交互流程:
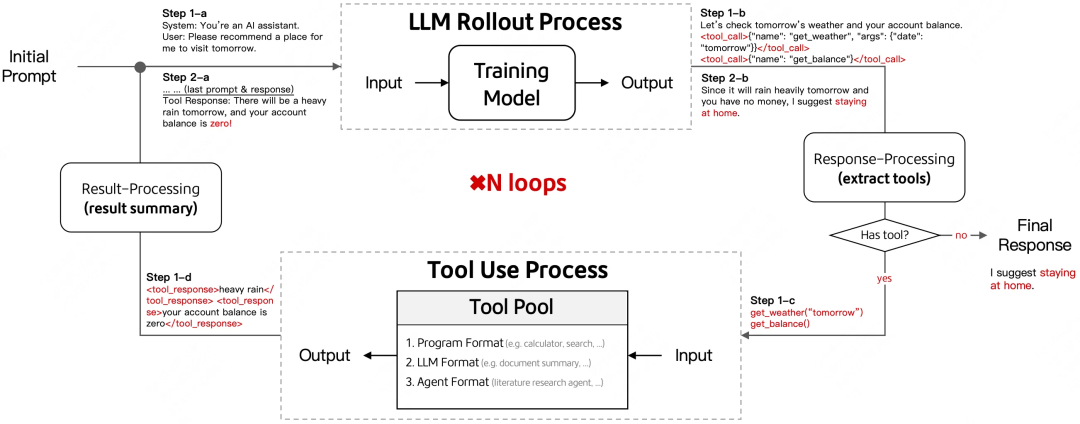
-
输入原始 Prompt,Agent模型推理输出Response(自行决定使用工具或者输出结果) -
对模型输出做后处理,解析工具名称及参数(若未解析到工具,视为终止循环,输出模型响应) -
按解析到的工具名称及参数运行工具(可并行),并对工具结果做后处理 -
将工具结果拼接回 Prompt,再次调用模型,直至终止
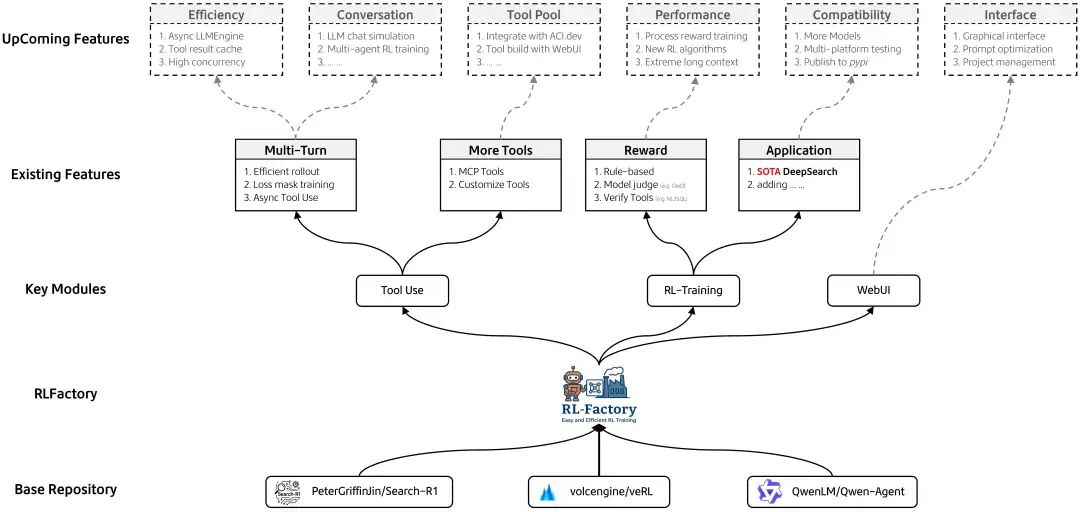
RLFactory – 简单且高效的端到端RL后训练
RLFactory的目标是让用户专注于奖励逻辑和工具配置,以极少的代码实现快速的 Agentic Learning,而进阶开发者则可以专注于提升训练效率和模型性能。
RLFactory的核心优势:
-
奖励函数易设计:通过规则、模型判分(LLM as Judge) 、工具(例如SQL查表) 计算奖励,满足你对奖励函数的所有需求。 -
工具接入无门槛:只需提供 MCP 工具和自定义工具的配置文件,即可无缝集成到 RL 学习中。 -
多智能体扩展性:将你的 agent 转换为 MCP 格式,轻松实现多智能体交互。未来还会加入 LLM 聊天模拟,提升多轮对话能力。 -
训练效率提升:批处理和异步并行工具调用,分布式部署 LRM(如 QwQ-32B)进行高效模型判分,让训练提速 2 倍甚至更高。
面向未来发展,RLFactory希望维护一个活跃的开源社区,积极听取所有使用者的意见,持续坚持“易用”和“高效”两大核心。
-
更易用:通过 WebUI 进行数据处理、工具和环境定义、训练配置调整及项目管理。(WebUI 正在快速开发中) -
更高效:持续迭代和优化训练框架(如 AsyncLLMEngine)及 RL 训练算法。
训练示例:5小时训练端到端的DeepSearch模型
只需配置Qwen3模型和MCP工具,便可快速复现并训练自己的DeepSearch Agent。不需要SFT,Qwen3直接通过RL后训练即可精准调用工具!
训练100步(8*A100,仅5小时),Qwen3-4B得分0.458,Qwen3-8B得分0.463,效率比传统方案提升1.5~2倍!如果涉及模型判分,则效率提升更明显。
模型地址见文末的 Qwen3-8B-GRPO 和 RLFactory-Qwen3-4B-GRPO
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| RLFactory-Qwen3-4B-GRPO | 0.458 | 5.30 小时 | 190 秒 |
|
| RLFactory-Qwen3-8B-GRPO | 0.463 | 5.76 小时 | 207 秒 |
|
欢迎加入我们!
我们欢迎所有的使用者和开发者向 RLFactory 提出宝贵的建议。如果你有任何疑问、发现 bug 或者希望一起开发,非常欢迎联系我们!
-
直接在 GitHub 提 issue -
通过邮箱 chaijiajun@meituan.com 或 gjyin@outlook.com 联系我们 -
加入我们的微信/QQ交流群,成为 Agent 训练的先驱!
代码仓库: https://github.com/Simple-Efficient/RL-Factory
[2]教程地址: https://github.com/Simple-Efficient/RL-Factory/blob/main/docs/rl_factory/main_tutorial.md
[3]RLFactory-Qwen3-8B-GRPO: https://huggingface.co/Simple-Efficient/RLFactory-Qwen3-8B-GRPO
[4]RLFactory-Qwen3-4B-GRPO : https://huggingface.co/Simple-Efficient/RLFactory-Qwen3-4B-GRPO
— 完 —
(文:GiantPandaCV)