
复旦大学

CVPR 2025 工业异常检测新突破!复旦&腾讯打造Real-IAD D³多模态数据集

复旦大学、腾讯优图实验室等联合发布高精度多模态数据集Real-IAD D³,并提出多模态融合检测方法,显著提升工业异常检测性能。


工业异常检测新突破,复旦等多模态融合监测入选CVPR 2025

复旦大学、荣旗工业科技、腾讯优图实验室等机构联合发布了高精度多模态数据集Real-IAD D³,并提出了一种基于此数据集的创新多模态融合检测方法,提升了工业异常检测性能。
机器人也能边想边做!清华团队OneTwoVLA让机器人煮火锅、炒菜、调酒样样精通

清华大学等机构联合推出OneTwoVLA模型,实现机器人既能思考又能执行任务,兼容长程规划、错误检测与恢复、自然人机交互及通用视觉定位能力。
“甲方快乐模型”诞生,拿下平面设计新SOTA!多条件一键生成,还能独立调整元素 复旦&字节
复旦大学和字节跳动团队联合提出CreatiDesign新模型,可实现高精度、多模态、可编辑的AI图形设计生成。该模型解决了扩散Transformer架构在处理图形设计时面临的统一建模、精细解耦控制及大规模高质量标注数据缺失等问题。
多模态推理新基准!最强Gemini 2.5 Pro仅得60分,复旦港中文上海AILab等出品
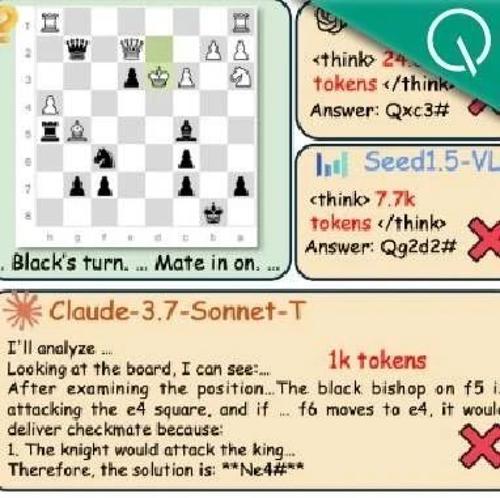
复旦大学及香港中文大学MMLab联合上海人工智能实验室等多家单位提出了MME-Reasoning,全面评估多模态大模型的推理能力。该基准分为三类推理:演绎、归纳和溯因,并涵盖三种问题类型。评测结果显示当前最优模型得分仅60%左右,显示了对逻辑推理能力的要求极高。
用大模型检测工业品异常,复旦腾讯优图新算法入选CVPR 2025

复旦大学、腾讯优图实验室等机构的研究人员提出了一种基于扩散模型的少样本异常图像生成新模型DualAnoDiff,该方法采用双分支并行机制和背景补偿模块,有效解决了异常数据稀缺性的问题,并在实验中取得了优于现有方法的效果。
