
CreatiDesign团队 投稿
量子位 | 公众号 QbitAI
平面设计师有救了!
复旦大学和字节跳动团队联合提出CreatiDesign新模型,可实现高精度、多模态、可编辑的AI图形设计生成。

△CreatiDesign能生成各种类型的平面设计图,如电影海报、品牌促销、产品广告和社交媒体图。
AI虽然在文生图领域已取得了很大的突破,但以往方法在处理图形设计时,要么“偏科”,要么缺乏精准的可控性。
而CreatiDesign推出了统一多条件控制的扩散Transformer架构,并配套构建了40万样本的大规模多条件标注数据集,满足实际设计需求。

挑战:需求多、数据少、控制难
在真实的平面设计场景中,用户往往会同时提供:
-
主视觉元素:(如产品图/LOGO,需保持高度一致性) -
辅助装饰元素:(如装饰品,用于衬托主体,需按指定位置排版) -
文本内容(如Slogan,需按指定位置排版)
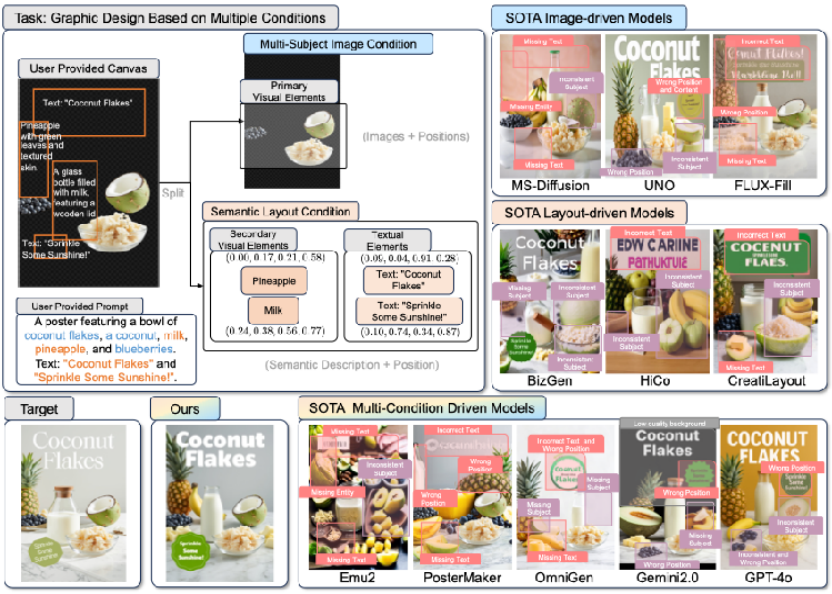
这种“多条件异质融合”对先前的扩散模型提出了三大挑战:
1.多条件异质信息的统一建模难
以往的可控扩散模型大多针对单一条件(如仅控制主体图或仅控制布局或文本),缺乏将多种异质条件(图像、布局、文本等)进行统一融合和协同建模的能力。
2.多条件之间的精细解耦与区域独立控制难
即便部分最新模型初步实现了多条件输入,依然难以确保每个子控制条件能够精准、独立地控制其对应的图像区域。
3.缺乏大规模高质量、多标注的训练数据
开源的图形设计数据集有限。现有的数据集缺乏精细化、多条件的标注,难以满足模型对多样性和高质量数据的训练需求。
为此,CreatiDesign从模型架构、数据构造等角度出发,提出了系统性的解决方案,旨在赋能扩散模型创意平面设计的能力
方法:条件协同、独立可控、流程全自动

统一多模态条件驱动
CreatiDesign基于MM-DiT(Multimodal Diffusion Transformer)框架,采用极简架构调整,实现了多种异质条件的协同控制:
多主体的图像条件:用户可以一次性输入多个主视觉元素(如产品图、LOGO等),并在空白画布上任意摆布,得到多主体的图像条件。然后将此图像送入原生的VAE进行编码,得到一组主视觉token。这些token能完整保留每个主体的细粒度视觉特征,为后续生成提供主体约束。
语义布局条件:每个辅助元素或文本的语义描述,先由T5文本编码器转换为语义特征token,空间位置信息(bounding box坐标)则经过傅立叶变换后,和语义特征拼接,再通过MLP进一步融合,最终得到集成了语义和空间信息的布局token。这种方式实现了对布局元素内容和空间排布的双重精准控制。
全局描述:用户还可以输入整体的描述,同样由T5编码为全局描述token,为全局内容和风格把控提供指导。
最终,所有类型的token(主视觉token、布局token、全局描述token)被拼接后输入到MM-DiT中。在每一层Transformer中,CreatiDesign采用多模态注意力(MM-Attention)机制,使不同模态的token进行深度融合,从而实现多条件的联合建模和控制。
多模态注意力掩码机制
为提升每个条件的独立可控性,CreatiDesign提出两种专属注意力掩码:
Subject Attention Mask:主体token仅与其指定区域内的图像token进行双向交互,且与布局token、全局描述token及无关区域的图像token完全隔离,确保主体内容高度还原、独立于其他条件。
Layout Attention Mask:每个布局token仅与其指定区域内的图像token交互,同时阻断布局token之间、布局token与主视觉或全局描述token之间的交互,防止布局元素之间的语义串扰与不同条件之间的干扰。
这种显式的掩码机制,使每个条件都能精准、独立地调控对应图像区域,极大提升了生成结果的一致性与可控性,保证了多条件复杂设计意图的严格还原。
自动化数据集生成流水线
CreatiDesign还提出了全自动的平面设计数据合成流程,包含:
主题生成:基于设计关键词库,使用LLM(如GPT-4)生成包含主视觉元素、布局元素和文本内容的多要素设计主题;
文本图层渲染:依据分层布局协议(HLG),通过渲染引擎自动生成带精准排版的文本前景图层(RGBA);
基于前景的图像生成:借鉴LayerDiffuse范式,联合LoRA模块,实现基于文本前景和主题描述背景的高质量平面设计图像生成;
实体检测与标注:利用GroundingSAM2检测所有实体(主视觉、辅助装饰),并通过VLM生成细粒度属性描述,实现全要素多条件的自动标注。
最终,CreatiDesign开源了规模达40万组、具备多条件高质量标注的平面设计样本,为多条件可控模型的训练提供数据基础。
实验:SOTA级性能展示
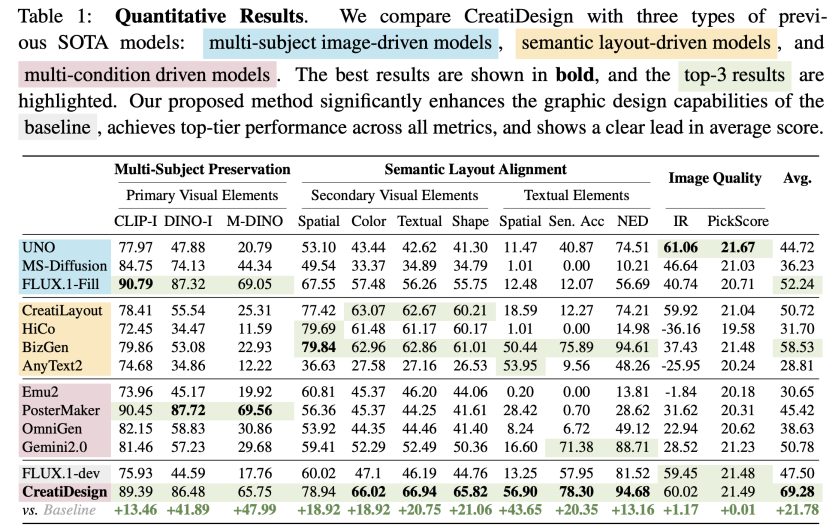
在多维度的评估基准上,CreatiDesign在主体保持度、布局遵循度、文本正确率以及图像整体质量等关键指标上均取得了领先的性能。
具体来说,CreatiDesign在主视觉元素的还原(如DINO-I、M-DINO分数)、辅助元素的空间位置与属性一致性、文本内容的准确率(Sen.Acc)和编辑距离(NED),乃至图像整体质量(IR、PickScore)等各项评价指标上,在当前主流的多主体图像驱动、布局驱动及多条件驱动的SOTA模型中,位居第一梯队。
从表格中可以看到,CreatiDesign的平均综合得分高达69.28,相比基础模型FLUX.1-dev的47.50分,提升幅度达到45.9%。这一显著提升仅依赖于基础模型4.1%的额外参数量,高效得提升了基础模型在图形设计上的能力。

上图中紫色蒙版代表不一致或位置错误的主体,红色蒙版代表语义或位置不正确的实体,灰色蒙版代表不协调的背景或前景区域。
可视化结果进一步验证了CreatiDesign在生成结果上的优势:与以往的多条件或单条件模型相比,CreatiDesign能够更加严格地遵循用户的设计意图,具体体现在主体元素的高度还原、辅助元素及文本的精准布局,以及整体画面的和谐一致。
对比图中可以清晰地看到,其他模型常常出现主体错位、内容缺失、文本错误等问题,而CreatiDesign能够准确保留各个输入要素,并实现复杂多元素的协调排布。
此外,CreatiDesign无需额外训练即可支持多轮编辑:用户可在已有平面设计结果上灵活插入新文本、新主体,或对文本内容进行修改,模型能够精准编辑指定区域,同时保持非编辑区域的内容不变。

相比Gemini2.0等主流大模型在编辑过程中常出现的非编辑区域变化、内容漂移等问题,CreatiDesign展现出更强的编辑灵活性与保持性。
论文地址:https://arxiv.org/pdf/2505.19114
项目主页:https://huizhang0812.github.io/CreatiDesign/
项目代码:https://github.com/HuiZhang0812/CreatiDesign
数据集:https://huggingface.co/datasets/HuiZhang0812/CreatiDesign_dataset
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)