

只用一个模型,就能边思考边动手,涮火锅、调鸡尾酒,还能听你指挥、自己纠错 —— 未来通用机器人的关键一跃,或许已经到来。
在大多数机器人系统中,「大脑」(高阶推理)和「四肢」(低层控制)往往是两套分离的模型:一个负责计划,一个负责执行。看似分工明确,却常常出现「计划写得天花乱坠,胳膊腿就是不听使唤」的尴尬。更别提,当人类临时改口、场景突变或网络卡顿时,两个子系统互不理解、来回沟通,效率大打折扣。
清华大学、复旦大学、上海期智研究院、上海人工智能实验室联合千寻智能推出的 OneTwoVLA,尝试将两套系统「熔炼」成一个既能想又能干的统一模型。目前代码与数据已全部开源。

-
论文标题: OneTwoVLA: A Unified Vision-Language-Action Model with Adaptive Reasoning
-
论文链接:https://arxiv.org/abs/2505.11917
-
项目主页:https://one-two-vla.github.io/
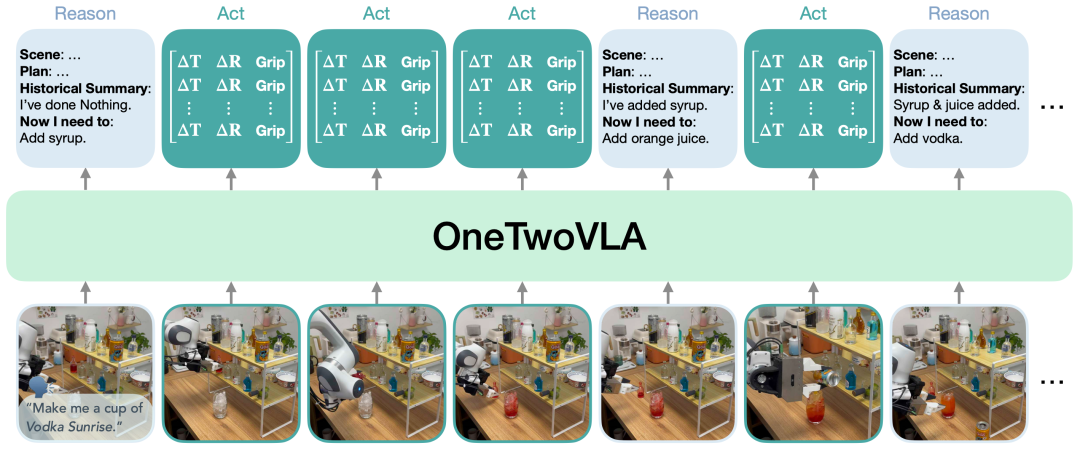
统一架构:推理与动作「一条龙」
-
System One?System Two?统统塞进同一个 Transformer!OneTwoVLA 在每一步首先预测是「[BOR] 开始推理」还是「[BOA] 开始动作」,真正做到想与做无缝切换。
-
关键时刻(子任务结束、检测到错误、需要人类指令时)自动进入推理;其余时间直接输出低延迟动作流。既保证决策质量,又兼顾实时性。
数据双引擎:真实机器人演示+1.6万条合成「具身推理」数据
-
真人示范:研究团队用 Franka 单臂、ARX 双臂采集了番茄炒蛋、火锅、鸡尾酒等长程任务示教,并逐段标注场景描述、任务计划、历史摘要、下一步指令等四类推理内容。
-
大模型生成:借助 Gemini 2.5 Pro + 文生图模型 FLUX,自动生产 1.6 万张桌面场景及对应任务/推理文本,涵盖空间、属性、语义指代与多步规划,大幅拓宽视觉与语言分布。

四大能力全面开花:从厨房到吧台,机器人展现「十八般武艺」
1. 长程规划:火锅大师、炒菜能手、调酒达人
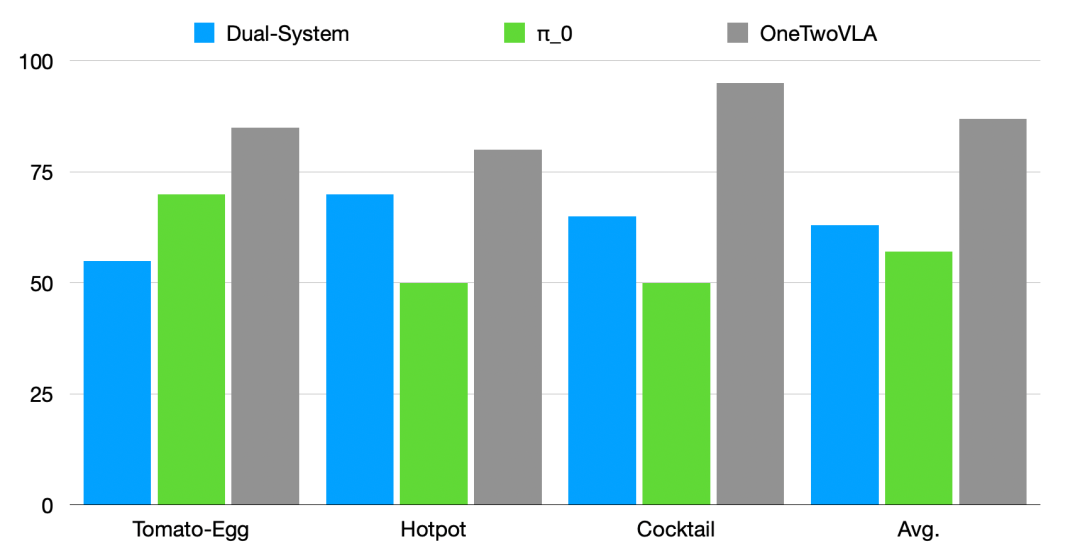
想象一下,一个机器人能完整做出一顿番茄炒蛋或帮你涮一顿火锅 —— 这可不是科幻片!OneTwoVLA 在这些复杂长程任务中的表现让人眼前一亮,比纯动作 VLA 提升 30%,比传统「双系统」方案提升 24%。
无论是精准夹起滑溜的牛肉片、细长的金针菇,还是稳稳将食材放进漏勺,机器人的动作流畅自然,宛如经验丰富的厨师。
通过与合成视觉语言数据的联合训练,OneTwoVLA 甚至能理解「从冰箱拿瓶冰可乐」这种训练时从未见过的指令 —— 它会聪明地打开冰箱门,找到可乐并取出。
2. 错误检测与恢复:失手了?没关系,我会自己改正!
人类做饭偶尔也会手滑,机器人当然也不例外。但 OneTwoVLA 的厉害之处在于它的自我纠错能力:
-
实时察觉异常:抓漏了瓶子?抓偏了漏勺?机器人会立即意识到问题。
-
快速调整策略:在炒番茄鸡蛋时,机器人发现第一次没有抓稳油瓶,会立即进行推理并尝试第二次抓取。
-
反应速度完胜双系统:传统双系统方案因为模块间通信延迟,往往错失最佳恢复时机。

3. 自然人机交互:会听话、会思考、还会 「反问」
这可能是最让人惊喜的能力 ——OneTwoVLA 的机器人不再是冷冰冰的执行者:
-
灵活响应新需求:任务进行到一半,你突然说「换成柠檬味伏特加」?没问题,机器人会立即调整动作序列。
-
主动寻求澄清:遇到模糊指令时,机器人会像人类助手一样主动询问。

4. 通用视觉定位:看得准、认得全、找得到
OneTwoVLA 展现出了令人印象深刻的开放世界视觉理解能力。即便训练数据中从未出现过雪碧罐或星巴克咖啡杯,它依然能够准确识别。这种能力源于模型对空间关系、物体属性和语义特征的深度理解。当你说「拿左边那个绿色的罐子」或「把最大的杯子递给我」,机器人都能准确理解并执行。这种从「死记硬背」到「举一反三」的跨越,预示着机器人正在向真正的通用智能迈进。

意义与展望
1. 范式转变:从「两个模型硬拼接」到「单模型自适应」,为通用机器人提供了更简洁、更易扩展的技术路线。
2. 数据新思路:证明了低成本、自动化生成的推理语言数据,可以显著提升机器人模型的泛化与常识。
3. 未来方向:
-
强化学习进一步提升推理深度;
-
异步架构,真正实现边想边干零停顿;
-
融合更多开放大规模语料,迈向室外、工业、服务等更复杂场景。
关于作者
该项目有三位共同一作:林凡淇,佴瑞乾,胡英东。

林凡淇是清华大学交叉信息院的一年级博士生,导师为高阳教授。他的研究方向是具身智能,他的目标是通过大规模数据,使机器人具备人类水平的操控能力。此外,他也热衷于利用基础模型来增强机器人的能力。林凡淇已在 ICLR、CoRL、IROS 等多个顶级机器学习和机器人学会议上发表论文。他的关于具身智能 Data Scaling Laws 的研究获得 CoRL 2024 X-Embodiment Workshop 最佳论文奖。

佴瑞乾是是清华大学交叉信息研究院的三年级博士生,导师为高阳教授。他的主要研究方向为具身智能,致力于通过大规模数据使机器人能够感知、推理和学习。佴瑞乾已在 ICRA, AAAI, NeurIPS 等多个机器人学和机器学习顶会发表论文,研究项目涵盖 VLA,四足机器人,人形机器人等多个方向。

胡英东是清华大学交叉信息研究院的四年级博士生,导师为高阳教授。他的主要研究方向为具身智能,涉及机器学习、机器人学和计算机视觉的交叉领域。他的研究专注于开发具备泛化能力的通用机器人系统,使其能够在多样化和非结构化的真实开放环境中执行任务。胡英东已在 ICML、ICLR、CoRL、ECCV 等多个顶级机器学习和机器人学会议上发表论文。他的关于具身智能 Data Scaling Laws 的研究获得 CoRL 2024 X-Embodiment Workshop 最佳论文奖。

项目的通讯作者是清华大学交叉信息研究院的助理教授高阳,他主要研究计算机视觉与机器人学。此前,他在美国加州大学伯克利分校获得博士学位,师从 Trevor Darrell 教授。他还在加州伯克利大学与 Pieter Abbeel 等人合作完成了博士后工作。在此之前,高阳从清华大学计算机系毕业,与朱军教授在贝叶斯推理方面开展了研究工作。他在 2011-2012 年在谷歌研究院进行了自然语言处理相关的研究工作、2016 年在谷歌自动驾驶部门 Waymo 的相机感知团队工作,在 2018 年与 Vladlen Koltun 博士在英特尔研究院在端到端自动驾驶方面进行了研究工作。高阳在人工智能顶级会议 NeurIPS,ICML,CVPR,ECCV,ICLR 等发表过多篇学术论文,谷歌学术引用量超过 5000 次。

©
(文:机器之心)