

极市导读
本文介绍了一种名为PAM(Perceive Anything Model)的新型区域级视觉-语言模型,它能够同时完成图像和视频中的目标分割、语义解释、定义说明以及详细描述等多种任务,极大地提升了视觉理解的效率和深度。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

文章链接:https://arxiv.org/pdf/2506.05302
项目地址:https://perceive-anything.github.io/


亮点直击
PAM(Perceive Anything Model),一种端到端的区域级视觉-语言模型,旨在实现图像和视频中快速、全面、细粒度的视觉理解。 Semantic Perceiver(语义感知器)的组件,有效利用 SAM 2 主干网络中的中间视觉特征,将通用视觉信息、定位信息和语义先验融合为视觉 token。 开发了一套先进的数据精炼与增强流程,结合领先的 VLM(如 GPT-4o)与人工专家验证,对现有区域级标注数据集进行精炼和扩展。
PAM 在多种图像和视频的区域理解任务中表现出强大的性能,同时相比以往方法,运行速度提升1.2至2.4 倍,GPU 显存消耗更少。
总结速览
解决的问题
-
缺乏区域级深层语义理解能力:
-
尽管如 SAM / SAM 2 等分割模型在目标定位上表现出色,但它们无法解释目标的类别、定义、功能或上下文语义。 -
现有方法局限性明显:
-
语义输出有限,仅支持简单标签或简短描述; -
模态适应性差,往往只能处理图像或视频中的一种; -
串行设计依赖外部 mask 生成器,计算冗余且对 mask 质量敏感。 -
缺乏高质量细粒度的区域语义数据:
-
现有区域级标注数据集粒度粗,不能满足细致语义理解任务的需求。
提出的方案
-
提出 PAM:端到端的区域级视觉-语言模型:
-
基于 SAM 2 扩展,融合大语言模型(LLM),实现图像和视频中区域级目标分割 + 多样化语义输出的统一处理。 -
引入 Semantic Perceiver(语义感知器):
-
作为 SAM 2 与 LLM 之间的桥梁,将视觉特征转化为 LLM 可理解的多模态 token,便于语义生成。 -
并行设计 mask 解码器与语义解码器:
-
同时生成区域 mask 与语义内容,提高计算效率,避免串行瓶颈。 -
构建高质量区域语义数据集:
-
开发数据精炼与增强流程,结合 VLM(如 GPT-4o)与人工验证,生成: -
150 万条图像区域语义三元组; -
60 万条视频区域语义三元组; -
首创流式视频区域级字幕数据; -
支持中英文双语标注。
应用的技术
-
SAM 2:作为视觉特征提取主干网络,提供强大的分割能力。
-
大语言模型(如 GPT-4o):用于理解视觉 token 并生成多样化语义输出。
-
Semantic Perceiver:将 SAM2 提取的视觉、定位和语义先验融合为 LLM 可处理的 token。
-
多模态并行解码架构: mask 与语义并行生成,提升效率。
-
数据增强与语义精炼流程:
-
利用 VLM + 人工校验生成细粒度语义标注; -
构建区域级流式视频字幕数据。
达到的效果
-
全面语义输出能力:
-
支持生成类别标签、定义解释、上下文功能说明、详细描述等多种语义信息。 -
多模态统一处理:
-
同时支持图像与视频的区域理解任务,具备良好的通用性与可扩展性。 -
显著提升效率与资源利用:
-
相比现有方法,运行速度提升 1.2–2.4 倍; -
GPU 显存消耗显著减少,适用于实际部署。 -
构建高质量语义数据集:
-
丰富的图像与视频区域标注,支持多语言训练; -
引领区域级视觉理解数据标准向更高质量演进。 -
成为强有力的研究基线:
-
具备端到端、轻量、高效、语义丰富等优势,预期将推动视觉-语言领域的进一步发展。
感知万物模型(PAM)
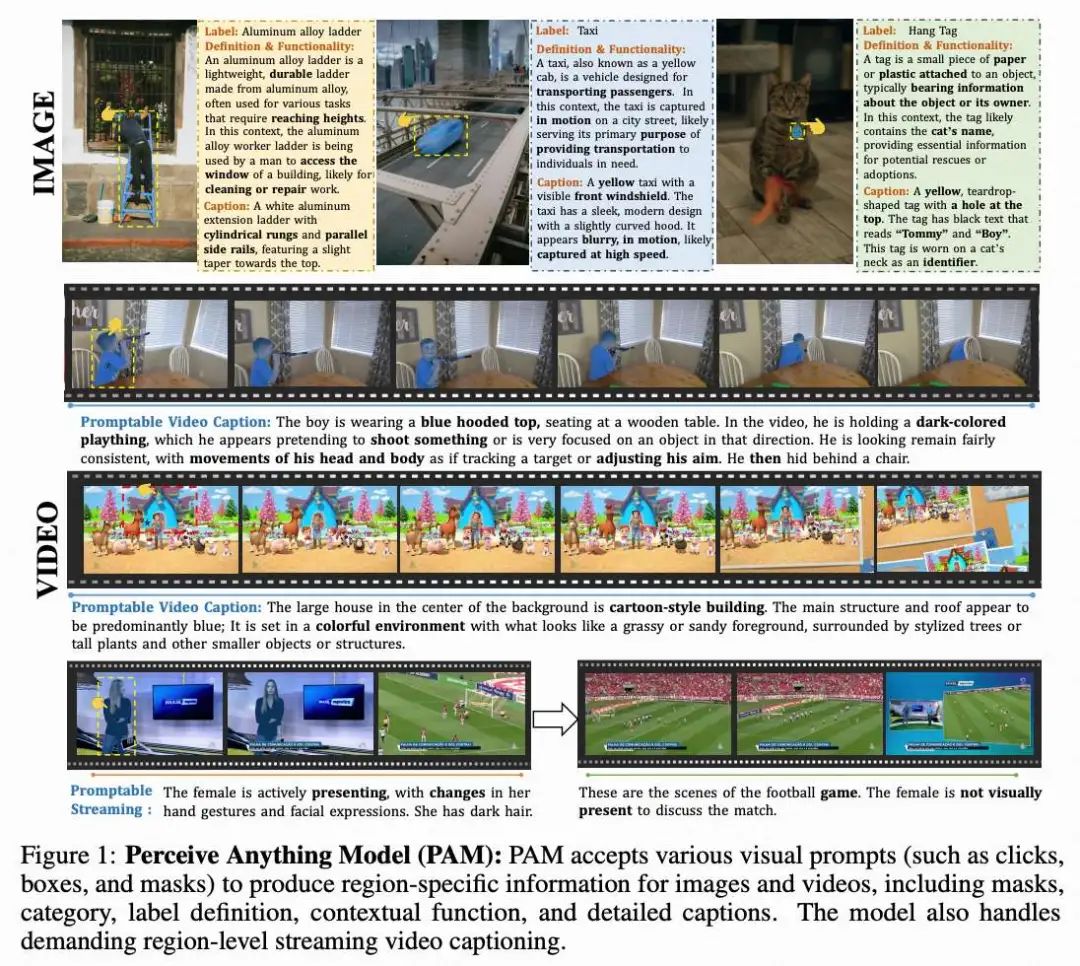
给定用于指定感兴趣区域的视觉提示(如点、框或 mask),感知万物模型(PAM)可以同时完成以下任务:
(1) 分割:在图像或视频中为指定区域生成精确的分割mask。 (2) 识别:识别指定区域或目标的类别。 (3) 解释:提供该区域或目标的定义、属性及其在上下文中的功能的清晰解释。 (4) 描述:为图像、视频和视频流中的区域生成简洁或详细的描述。
模型架构
如下图3所示,PAM 可以分为两部分。
第一部分是 SAM 2 框架,包括图像编码器、提示编码器、记忆模块和 mask 解码器。该框架提供了强大的时空视觉特征提取与分割能力。
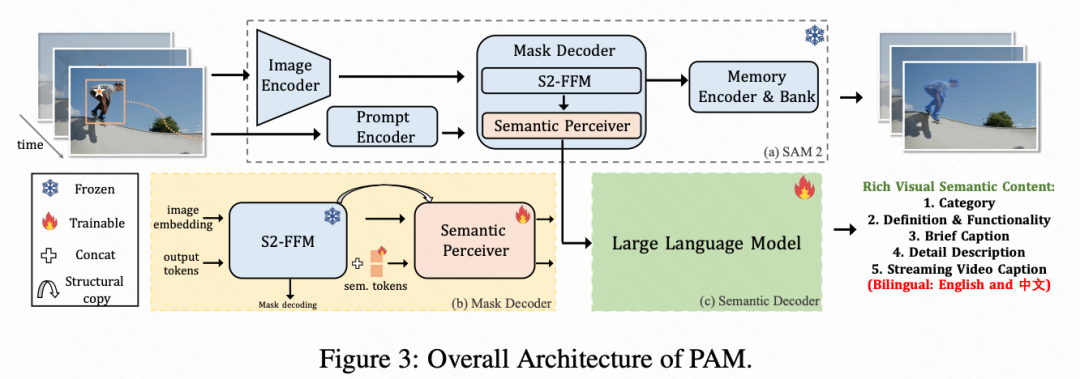
第二部分是基于大语言模型(LLM)的语义解码器。关键在于提出的 Semantic Perceiver(语义感知器),它作为桥梁,有效利用来自 SAM 2 主干网络的中间视觉特征,生成视觉 token。这些 token 随后由 LLM 处理,以生成多样化的语义输出。
在解码方面,PAM 采用 mask 解码器与语义解码器的并行设计,可以在分割目标的同时生成其多样化语义输出。组件设计与训练过程如下所述。
语义感知器(Semantic Perceiver) 如上图 3(b) 和下图 4 所示,语义感知器的架构借鉴了 SAM 2 的特征融合模块(S2-FFM),采用了一个轻量的两层 Transformer,包含自注意力、交叉注意力和逐点 MLP。
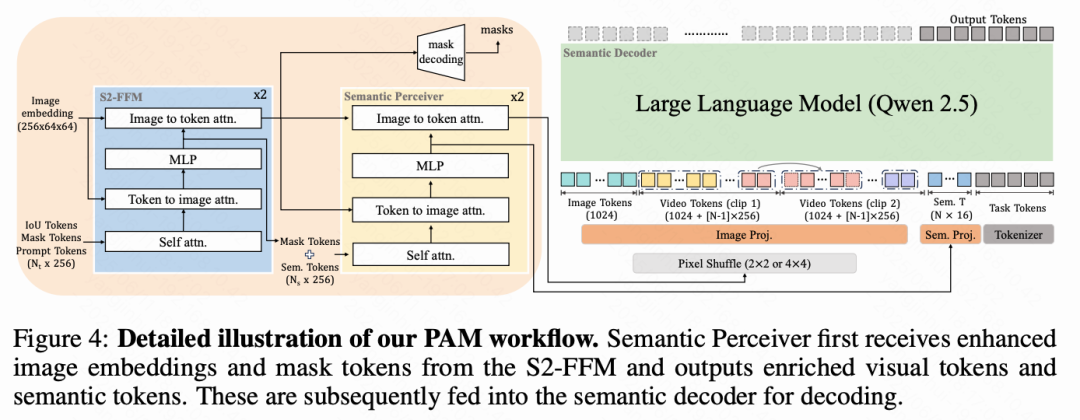
具体而言,它接收两个主要输入:
-
来自 S2-FFM 的增强 mask token,包含 IoU 和提示 token 信息,作为精确 mask 生成的唯一标识; -
S2-FFM 后更新的图像嵌入,捕捉了通过与 mask token 交互所增强的通用视觉上下文和隐式特征。
接着,参考,将 个可学习的语义 token 与增强 mask token 进行拼接。最终,通过语义感知器内部的进一步注意力机制,我们可以获取同时具备通用视觉信息和目标级定位信息的视觉 token。
对于 帧的输入(其中单张图像时 ),语义感知器输出两组 256 维向量: 的视觉 token 和 的语义 token(默认 )。
投影器(Projector) 在进入 LLM 之前,投影器由两个部分组成:像素重排操作和 MLP 投影器。
-
对于图像输入,我们在相邻的 特征块上应用像素重排操作,以减少视觉 token 数量; -
对于视频输入,提示帧与单张图像处理方式相同,而视频片段中的其余帧则使用更激进的 像素重排操作,以显著减少视觉 token,并进一步提高语义解码器的处理效率。
随后,使用两个不同的 MLP [45] 分别对视觉 token 和语义 token 进行投影。
语义解码器(Semantic Decoder) 我们采用预训练的 Qwen2.5 LLM [72] 作为语义解码器,利用其强大的语言处理能力。该解码器负责解释处理后的视觉 token 和语义 token,并结合任务指令生成所需的语义输出。
流式视频编码与解码(Streaming Video Encode and Decode) 在 SAM 2 中通过记忆模块逐帧引入历史信息的基础上,我们提出了一种区域级流式视频字幕生成的简洁策略,无需添加复杂组件。
具体而言,在每个视频片段的最后一帧上额外应用2 \times 2像素重排操作,从而提高视觉 token 的密度,增强历史视觉信息的保留能力。这些 token 随后作为下一个视频片段的初始帧输入,并与该片段的其余帧一起被 LLM 处理。
该方法确保每个片段的一致处理,并有效地将前一片段的重要历史信息传递至下一个片段。
此外,将前一时刻的文本描述引入提示中,以进一步增强上下文历史,从而提升模型对当前事件的理解与描述准确性。
在实际应用中,我们的框架允许用户灵活指定解码时间戳。当达到指定时间戳时,模型将描述该时间戳与前一时间戳之间时间区间内指定区域的内容。
训练策略(Training Strategies) 我们采用三阶段课程学习方法构建训练流程,逐步提升 PAM 对区域级视觉内容的理解能力,从图像扩展至视频。在所有训练阶段中,SAM 2 的参数保持冻结。
-
阶段 1:图像预训练与对齐
初始训练阶段致力于在视觉 token、语义 token 与语言模型嵌入空间之间建立稳健对齐关系。主要目标是使模型能够有效理解图像中的区域级内容。为此,我们使用了一个大规模的区域级图像分类与描述数据集。在此阶段,仅训练语义感知器与投影器。 -
阶段 1.5:视频增强预训练与对齐
本阶段在图像训练的基础上引入区域级视频字幕数据,使模型能够通过整合时空视觉信息理解动态场景。可训练模块与阶段 1 相同。 -
阶段 2:多模态微调
最后阶段采用监督微调(SFT),使模型能够执行多样化任务并生成所需响应。该阶段使用通过我们流程(下文)精炼与增强的高质量数据集。在此阶段,语义感知器、投影器与语义解码器将联合训练。
数据
为了增强 PAM 的全面视觉感知能力,开发了一套强大的数据精炼与增强流程,用于构建高质量的训练数据集。该数据集具有以下三个关键特性:
(1) 广泛的语义粒度:提供从粗粒度(类别、定义、上下文功能)到细粒度(详细描述)多样的视觉语义标注。
(2) 区域级流式字幕标注:首个专门为流式视频区域字幕生成而构建标注的数据集。
(3) 双语标注:支持英文与中文。

图像数据集
区域识别、解释与描述。
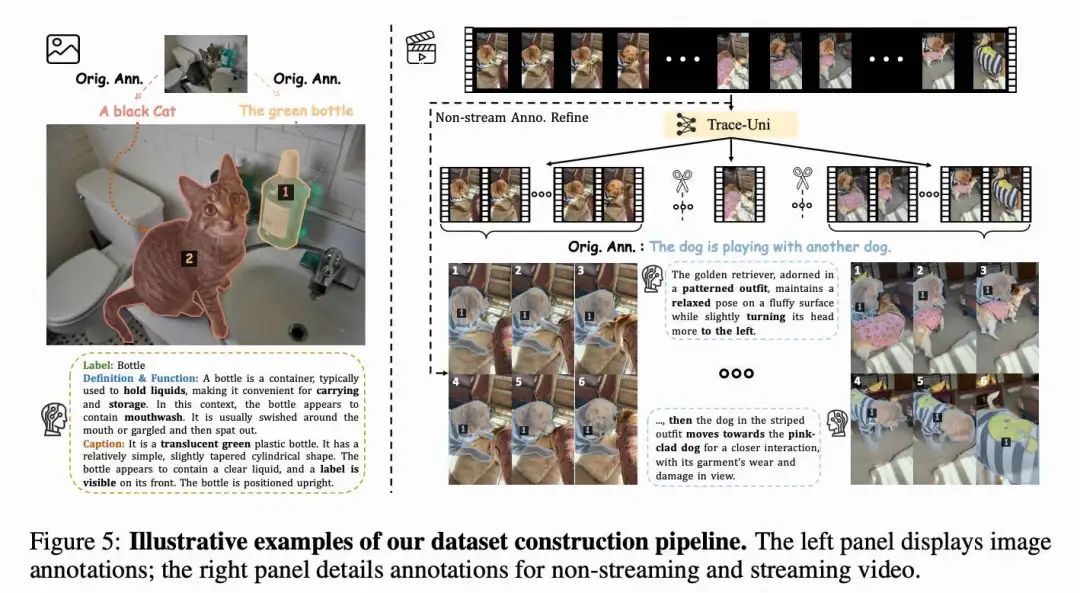
针对区域识别,使用了多个实例检测与分割数据集 [55, 35, 40, 23, 50, 66],以及场景文字识别数据集 [56, 31, 30, 19, 24, 14, 76, 57, 4]。在此任务中,边界框或 mask 作为视觉提示输入,标签则作为输出。
为了实现超越简单分类的深层次、细粒度视觉理解,我们提出了一种增强流程,生成以下内容:清晰的概念解释、上下文功能角色以及每个特定区域的详细描述。该多维信息旨在显著提升用户理解力,尤其适用于生僻术语或陌生主题。
为实现上述目标,利用最新的视觉语言模型(VLMs),借助其广泛的世界知识与强大的视觉理解能力辅助精炼。具体而言,采用 Set of Mask (SoM) 方法识别感兴趣区域,并使用原始标注作为上下文,引导模型生成目标响应,随后进行人工质检。示例参见下图5(左)。
视频数据集
区域级视频字幕。 为了扩展模型在视频中的区域字幕生成能力,收集并分析了若干已有视频数据集,包括指代检测与分割数据集,以及最近的 Sa2VA对 SAV数据集的标注。这些数据集旨在根据文本描述检测、分割并生成视频中特定目标的字幕,但往往存在描述过于粗略、简单、不准确或主要为静态内容的问题,忽略了视频中目标的运动、交互与状态变化等关键时间细节。
为了解决上述问题,提出了基于故事板的字幕扩展方法。该流程包括以下关键阶段:
(1) 关键帧采样:从每个视频中均匀提取六帧关键帧;
(2) 故事板合成:将这些关键帧合成为一张高分辨率复合图像,以故事板格式展示(如上图5所示);
(3) 目标集中高亮:在复合图像中,通过彩色边界框或 mask (由 SoM 实现)高亮每帧中的目标对象;
(4) 由 LLM 驱动的细化:随后,以原始标注为条件,提示 GPT-4o 生成更精细、详细且具时间感知的描述。该多帧整合过程对提升 GPT-4o 的上下文理解至关重要,生成的描述质量显著优于逐帧分析。
区域级流式视频字幕。 除了对整段视频进行描述外,我们还希望将模型能力扩展至流式字幕生成。为此,在精炼后的区域级视频字幕数据上执行了额外的数据增强。
具体而言,首先使用 TRACE-Uni模型将输入视频划分为多个不同事件片段,每个片段具有明确的时间边界。随后,对每个分段视频片段应用相同的“基于故事板”的处理方法。
为了生成精确且连续的事件描述,我们重新设计了 GPT-4o 的输入提示,使其在处理当前片段时,迭代性地引入前一视频片段的描述作为上下文信息。整个工作流程如上图5(右)所示。
实验
实现细节
采用 Qwen2.5-1.5B/3B作为语义解码器,并使用预训练的分层 SAM 2-Large 作为基础视觉模型。默认情况下,使用16个可学习的语义 token,并对每个视频片段均匀采样16帧。所有训练均在8张 NVIDIA A100 80GB 显卡上进行。
在所有评估实验中,我们采用零样本测试方式,即不在特定数据集上进行微调。最佳结果以加粗表示,次优结果以下划线标记。
图像基准测试
区域识别与解释。 该任务要求模型识别指定图像区域中的目标类别或场景文字。识别性能在以下数据集上评估:
-
LVIS(目标级)与 PACO(部件级)的验证集; -
COCO-Text与 Total-Text的测试集。
评估指标包括:语义相似度(Semantic Similarity)、语义交并比(Semantic Intersection over Union, Sem. IoU)以及准确率。
如下表1所示,PAM-1.5B 和 PAM-3B 都展现了强劲的性能。值得注意的是,PAM-3B 显著优于其他竞争方法。它在 PACO 基准上取得了最佳性能,超过此前最优模型超过 ,并在 LVIS 基准上在语义 IoU 指标上超过了当前的 SOTA 模型 DAM-8B。此外,如下表1右栏所示,PAM-3B 在 Total-Text 上超过VP-SPHINX-13B 超过 ,并在 COCO-Text 上取得了相当的性能。这些结果展示了其在场景文字识别中的潜力。进一步在图6中展示了定性可视化结果,说明 PAM 在生成涵盖目标通用定义与上下文角色的解释方面的有效性。
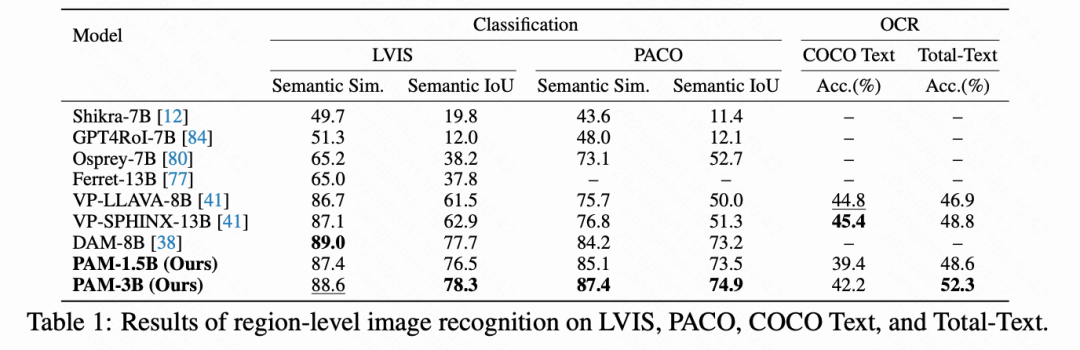
区域字幕。在多个基准上评估模型生成简洁与详细区域描述的能力。对于简洁区域字幕,在 RefCOCOg和 Visual Genome (VG)的验证集上进行评估。对于更具表现力的描述,则在具有挑战性的 Ref-L4数据集上进行评估。字幕质量通过 ROUGE-L、METEOR和CIDEr进行衡量。此外,还通过 Ferret-Bench和 MDVP-Bench对指代性描述进行基准测试,使用 GPT-4o 来评估生成响应的质量。
如下表2所示,PAM-3B 在 VG、RefCOCOg 和 Ferret 基准上超越了现有方法。在 MDVP-Bench 上,其性能与当前 SOTA 方法 VP-SPHINX-13B 相当。此外,在 Ref-L4 基准上,PAM-3B 展现出卓越的性能,除顶尖的 DAM-8B 之外,超过了所有其他模型。值得注意的是,这些具有竞争力的结果是在更少参数和更低计算成本下实现的,突显了 PAM 在性能与效率之间的优异平衡。

视频基准
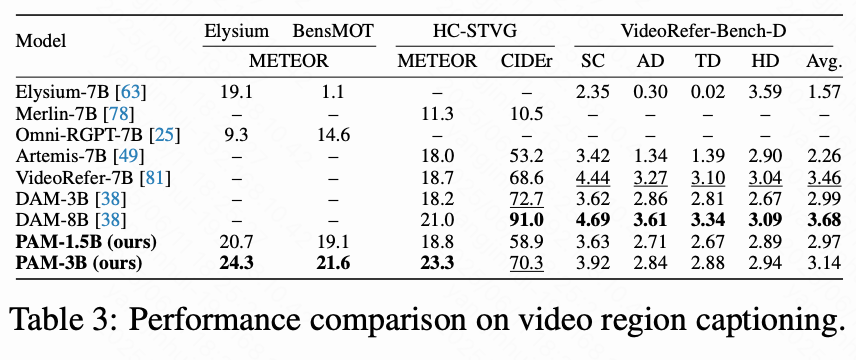
视频区域字幕。该任务要求模型在视频上下文中为指定区域生成准确且具时间感知的描述。我们主要在四个公开基准上进行评估:Elysium、BensMOT、HC-STVG和 VideoRefer-Bench-D。如下表3所示,PAM-1.5B 和 PAM-3B 在 Elysium 和 BensMOT 基准上均取得 SOTA 性能。此外,PAM-3B 在 HC-STVG 基准上的 METEOR 指标上超过当前 SOTA 方法 DAM-8B 达 。在 VideoRefer-Bench 上,本文模型相比VideoRefer-7B 和 DAM-8B 略有逊色,显示出进一步提升的潜力。
流式视频区域字幕。该任务要求模型以流式方式为指定区域生成连续描述。评估时,主要使用 ActivityNet 数据集的验证集。为确保公平比较并准确评估区域级流式字幕生成能力,人工筛选了一个包含 400 个样本的子集。筛选过程遵循两个关键标准:(1) 每个视频中标注的事件时间上连续且无重叠;(2) 每个视频中所有标注事件描述均涉及同一主体。随后,为每个选定视频中的目标主体手动标注了边界框。
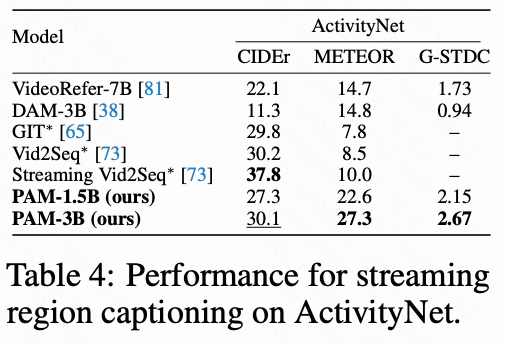
最初采用两个标准的密集字幕评估指标:CIDEr 和 METEOR。为进一步评估连续事件描述的连贯性与实体一致性,提出了一个新指标:GPT-4o 评估的时空描述连续性得分(G-STDC),范围为0到5。
下表4的结果表明,近期的区域级视频字幕模型(包括 VideoRefer 和 DAM)在流式字幕任务中能力有限。与通用流式字幕方法(如 Streaming Vid2Seq)相比,PAM-3B 在 METEOR 指标上表现更优。此外,PAM-3B 在 G-STDC 上取得最佳性能,表明其在时空连续性和保持主体描述一致性方面表现出色。

效率
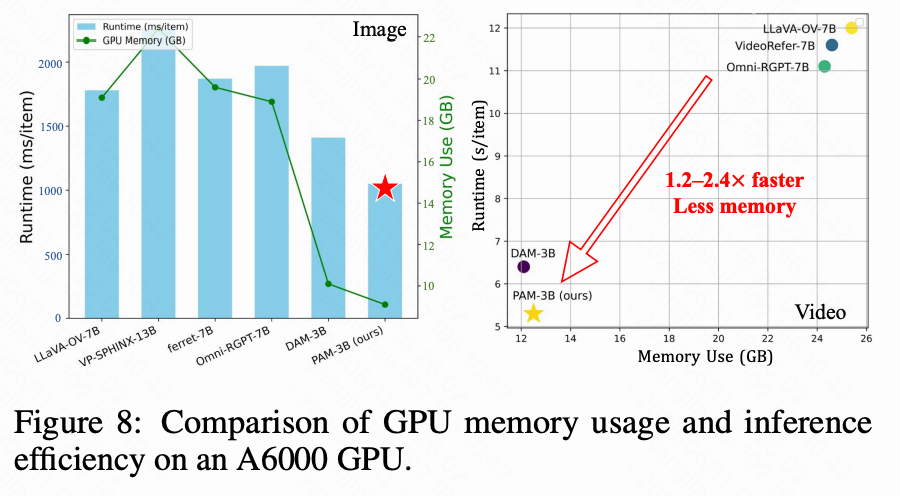
如下图8所示,与现有方法相比,PAM 展示了更优的推理效率,并且在图像和视频处理方面都需要更少的 GPU 内存,突显了其在真实应用中高效部署的适用性。
消融实验
研究了所提出关键技术的有效性,如下所示:
-
在下表5中,展示了可学习语义标记数量(sem.T)调整的影响。观察到使用过少的 sem.T 会导致性能下降。相反,使用过多的 sem.T 会带来收益递减,同时增加计算成本。因此,选择使用 个 sem.T,以实现性能与效率的良好权衡。 -
在下表6中,比较了不同的训练策略。结果显示,从图像-视频模型检查点(来自阶段1.5)初始化,相较于直接从阶段1模型检查点初始化或在一个统一阶段直接训练,始终能带来更佳的性能。 -
下表7对比了来自 SAM 2 的不同中间特征的影响。结果显示,经由 S2-FFM 更新的嵌入提升了我们模型的性能,进一步强调了特征选择方法的关键作用。

结论
Perceive Anything Model(PAM),这是一种从 SAM 2 扩展而来的区域级视觉-语言模型,旨在在图像和视频中同时完成目标分割并生成多样化的语义输出。PAM 在多个区域级理解任务中展现出强健性能,同时实现了高计算效率。本文方法的简洁性与高效性使其非常适用于真实世界应用,能够通过单次交互实现对视觉内容的细粒度、多维度理解。
参考文献
[1] Perceive Anything: Recognize, Explain, Caption, and Segment Anything in Images and Videos
(文:极市干货)