

极市导读
DINO V2从头到尾超全详解。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
1. 导论:从“大力出奇迹”到“四两拨千斤”的自监督学习进化史
各位老铁们,大家好!今天,要聊聊最近在自监督学习领域掀起惊涛骇浪的 DINO V2 算法。
在座的各位,想必都听过“大力出奇迹”这句话。在早期的深度学习世界里,这句话简直就是真理。那时候,想要模型效果好,就得拼算力、拼数据,谁的数据集更大,谁的模型参数更多,谁就能在各种榜单上傲视群雄。这种“暴力美学”固然有效,但就像用“大炮打蚊子”,成本高昂,效率低下,而且严重依赖标注数据。
但是,各位有没有想过,我们人类学习知识,难道也是靠“大力出奇迹”吗?当然不是!我们更多的时候是在“自学成才”,通过观察世界、与环境互动,就能学习到各种各样的知识,根本不需要别人一句一句地教。比如,小孩子看到猫猫狗狗,不用大人告诉他“这是猫”、“那是狗”,自己也能逐渐区分出来。这就是自监督学习的魅力所在——让机器像人一样,从海量无标注数据中自主学习知识,实现“四两拨千斤”的效果。
自监督学习的概念其实由来已久,但真正迎来爆发式发展,还是近几年的事情。从最初的 Autoencoder、到后来的 Contrastive Learning (对比学习),再到如今的 DINO 系列,自监督学习算法不断推陈出新,效果也越来越惊艳。而 DINO V2,正是这场自监督学习革命中的一颗璀璨明星。
DINO V2 的横空出世,就像给自监督学习领域注入了一剂强心针。 它不仅在性能上超越了之前的 DINO 和其他自监督算法,更重要的是,它展现了自监督学习在通用视觉特征提取方面的巨大潜力。这意味着,我们未来可能不再需要花费大量人力物力去标注数据,只需要用 DINO V2 这样的算法,就能从海量无标注数据中训练出强大的视觉模型,应用于各种各样的计算机视觉任务。
那么,DINO V2 究竟是如何做到这一切的呢?它的背后又隐藏着哪些“黑科技”? 别着急,接下来,咱一步一步地为你揭开 DINO V2 的神秘面纱,保证让你听得懂、学得会、笑得开心!
本文的“食用指南”如下:
-
第一部分 (导论): 简单介绍自监督学习的背景和意义,引出 DINO V2 的重要性,并概括文章内容。 -
第二部分 (算法原理详解): 深入剖析 DINO V2 的算法原理,包括整体框架、Transformer 架构、对比学习机制、知识蒸馏策略、多尺度特征融合等关键技术,并结合数学公式、示意图和代码示例进行详细讲解。 -
第三部分 (创新点分析): 重点分析 DINO V2 相对于 DINO 和其他自监督算法的创新之处,例如更强大的 Transformer backbone、更有效的训练策略、更广泛的应用场景等,并进行对比分析和技术解读。 -
第四部分 (问题解决与效果评估): 探讨 DINO V2 解决的核心问题,例如如何从无标注数据中学习到高质量的视觉特征,以及如何在各种下游任务中取得优异的效果,并采用量化指标和可视化结果进行效果评估和案例分析。 -
第五部分 (改进空间探讨): 客观分析 DINO V2 的局限性,例如计算复杂度高、对超参数敏感等,并提出可能的改进方向和未来发展趋势,例如模型压缩、自适应超参数调整、与其他技术的融合等。 -
第六部分 (总结与展望): 总结 DINO V2 的核心思想和重要贡献,展望自监督学习的未来发展前景,并鼓励读者深入学习和研究。
准备好了吗?让我们一起踏上 DINO V2 的探索之旅吧!
2. 算法原理详解:DINO V2 的“炼丹炉”和“魔法棒”
好了,各位,经过前面的“开胃小菜”,我们现在正式进入 DINO V2 的“核心厨房”——算法原理详解环节。在这里,我们将像庖丁解牛一样,一层一层地剖析 DINO V2 的内部构造,让你彻底搞懂它的“炼丹术”和“魔法棒”。
2.1 DINO V2 的整体框架:Teacher-Student 架构的“升级版”
DINO V2 的整体框架,其实可以看作是 DINO (Distillation with No labels) 算法的“升级版”。DINO 算法本身就采用了 Teacher-Student 的知识蒸馏框架,而 DINO V2 在此基础上进行了多方面的改进和优化,使其性能更上一层楼。
什么是 Teacher-Student 架构呢? 我们可以把它想象成一个“老师”和一个“学生”。老师模型 (Teacher Model) 比较强大,负责生成“知识”(通常是模型的输出,例如特征向量或概率分布),学生模型 (Student Model) 比较弱小,负责向老师学习“知识”,并努力模仿老师的行为。通过不断地学习和模仿,学生模型也能逐渐变得强大起来。
在 DINO V2 中,Teacher 模型和 Student 模型都是 Transformer 架构。 Transformer 架构,大家应该都不陌生了,自从它在自然语言处理领域大放异彩之后,也被广泛应用于计算机视觉领域,成为了图像分类、目标检测、语义分割等任务的“标配”。Transformer 的核心优势在于其强大的**自注意力机制 (Self-Attention Mechanism)**,能够有效地捕捉图像中不同区域之间的 long-range dependencies (长距离依赖关系),从而更好地理解图像内容。
DINO V2 的 Teacher-Student 架构具体是怎样的呢? 我们可以用一张图来概括:
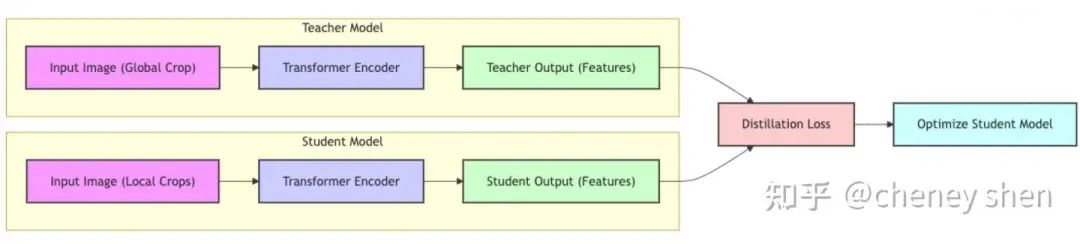
从图中我们可以看到:
-
输入图像 (Input Image): DINO V2 的输入是一张图像。为了进行自监督学习,DINO V2 采用了 Multi-Crop Augmentation (多裁剪增强) 的策略,对同一张图像裁剪出多个不同的 views (视角)。这些 views 分为两类:
-
Global Crop (全局裁剪): 通常是较大尺寸的裁剪,例如 224×224 或 256×256,用于提供图像的全局信息。Global Crop 会被输入到 Teacher 模型中。
-
Local Crops (局部裁剪): 通常是较小尺寸的裁剪,例如 96×96 或 112×112,用于提供图像的局部细节信息。Local Crops 会被输入到 Student 模型中。
-
Transformer Encoder (Transformer 编码器): Teacher 模型和 Student 模型都使用 Transformer Encoder 作为 backbone (骨干网络)。Transformer Encoder 的作用是将输入的图像 patches (图像块) 转换为特征向量。
-
Teacher Output & Student Output (Teacher 和 Student 模型的输出): Teacher 模型和 Student 模型分别将输入的 Global Crop 和 Local Crops 编码成特征向量,作为各自的输出。
-
Distillation Loss (蒸馏损失): DINO V2 的核心是知识蒸馏。它通过计算 Teacher 模型和 Student 模型输出特征之间的 Distillation Loss,来指导 Student 模型的学习。Distillation Loss 的目的是让 Student 模型的输出尽可能地接近 Teacher 模型的输出,从而让 Student 模型学习到 Teacher 模型的“知识”。
-
Optimize Student Model (优化 Student 模型): 通过最小化 Distillation Loss,DINO V2 使用梯度下降等优化算法来更新 Student 模型的参数,使其不断地逼近 Teacher 模型。
需要注意的是,Teacher 模型的参数更新方式与 Student 模型不同。 DINO V2 并没有直接使用梯度下降来更新 Teacher 模型的参数,而是采用了 Exponential Moving Average (EMA,指数移动平均) 的策略。具体来说,Teacher 模型的参数是 Student 模型参数的 EMA 版本,即 Teacher 模型的参数会缓慢地向 Student 模型的参数靠拢,但又不会完全相同。这种 EMA 更新策略能够有效地稳定 Teacher 模型的训练,并提高模型的泛化能力。
总结一下,DINO V2 的整体框架可以概括为: 使用 Teacher-Student 架构,Teacher 模型处理 Global Crop,Student 模型处理 Local Crops,通过 Distillation Loss 来指导 Student 模型的学习,Teacher 模型的参数通过 EMA 方式更新。这种框架的设计,使得 DINO V2 能够有效地从无标注数据中学习到高质量的视觉特征。
2.2 Transformer 架构:DINO V2 的“魔法棒”
正如前面所说,DINO V2 的 Teacher 模型和 Student 模型都采用了 Transformer 架构作为 backbone。Transformer 架构,作为近年来深度学习领域最耀眼的明星之一,其强大的特征提取能力和灵活的结构设计,为 DINO V2 的成功奠定了坚实的基础。
那么,Transformer 架构究竟有什么“魔法”呢? 我们不妨先简单回顾一下 Transformer 的基本原理。
Transformer 最初是为自然语言处理 (NLP) 任务设计的。 在 NLP 领域,Transformer 最著名的应用就是 Transformer 模型,例如 BERT、GPT 等。Transformer 模型的核心组件是 **Self-Attention Mechanism (自注意力机制)**。自注意力机制能够让模型在处理序列数据 (例如文本) 时,动态地关注序列中不同位置的信息,从而更好地理解序列的上下文关系。
Transformer 的基本结构可以概括为: Encoder (编码器) 和 Decoder (解码器) 两部分。Encoder 负责将输入序列编码成一个固定长度的向量表示,Decoder 负责将这个向量表示解码成目标序列。在 DINO V2 中,我们主要使用的是 Transformer Encoder 部分。
Transformer Encoder 的基本组成单元是 Transformer Block (Transformer 块)。 一个 Transformer Block 通常包含两个子层:
-
Multi-Head Self-Attention (多头自注意力): 这是 Transformer 的核心组件。多头自注意力机制能够让模型并行地学习多个不同的注意力分布,从而更全面地捕捉输入序列的信息。 -
Feed-Forward Network (前馈神经网络): 这是一个简单的两层全连接神经网络,用于对自注意力层的输出进行非线性变换。
Transformer Block 的结构可以用下图表示:

在 DINO V2 中,Transformer Encoder 被应用于图像处理。 为了将 Transformer 应用于图像,DINO V2 首先将输入图像划分为一个个小的 **patches (图像块)**。例如,对于一张 224×224 的图像,可以将其划分为 16×16 个 14×14 的 patches。然后,将每个 patch 展平成一个向量,作为 Transformer Encoder 的输入序列。
DINO V2 使用的 Transformer Encoder 结构与 Vision Transformer (ViT) 类似。 ViT 是 Google 提出的将 Transformer 应用于图像分类的经典模型。ViT 的结构非常简洁,主要由以下几个部分组成:
-
Patch Embedding (图像块嵌入): 将输入图像划分为 patches,并将每个 patch 展平成向量,然后通过一个线性层进行 embedding (嵌入),得到 patch embedding。 -
Positional Encoding (位置编码): 由于 Transformer 的自注意力机制是位置无关的,为了让模型感知到 patches 的位置信息,需要添加 positional encoding。ViT 使用的是可学习的 positional encoding。 -
Transformer Encoder Layers (Transformer 编码器层): 由多个 Transformer Block 堆叠而成。 -
Classification Head (分类头): 对于图像分类任务,ViT 通常会在 Transformer Encoder 的输出上添加一个简单的分类头,例如一个线性层或 MLP (多层感知机)。
DINO V2 使用的 Transformer Encoder 结构与 ViT 类似,但也有一些不同之处。 例如,DINO V2 并没有使用 ViT 的 classification head,而是直接使用 Transformer Encoder 的输出特征进行自监督学习。此外,DINO V2 在 Transformer Encoder 的结构细节上可能也进行了一些调整和优化,以更好地适应自监督学习任务。
总而言之,Transformer 架构是 DINO V2 的“魔法棒”。 它为 DINO V2 提供了强大的特征提取能力,使得 DINO V2 能够有效地捕捉图像中的复杂信息,并学习到高质量的视觉特征。Transformer 的自注意力机制,更是让 DINO V2 能够关注图像中不同区域之间的关系,从而更好地理解图像的语义内容。
2.3 对比学习机制:让 Student 模型“看齐” Teacher 模型
DINO V2 的核心思想是知识蒸馏,而知识蒸馏的关键在于如何定义 Teacher 模型和 Student 模型之间的“知识”差异,并设计合适的损失函数来指导 Student 模型的学习。在 DINO V2 中,它采用了 Contrastive Learning (对比学习) 的机制来实现知识蒸馏。
什么是对比学习呢? 对比学习是一种自监督学习方法,它的核心思想是 “物以类聚,人以群分”。简单来说,就是将相似的样本拉近,将不相似的样本推远。在图像领域,我们可以认为同一张图像的不同 views 是相似的,而不同图像的 views 是不相似的。
DINO V2 如何将对比学习应用于知识蒸馏呢? 它的做法是:
-
Teacher 模型和 Student 模型分别处理同一张图像的不同 views。 Teacher 模型处理 Global Crop,Student 模型处理 Local Crops。 -
Teacher 模型和 Student 模型分别输出特征向量。Teacher 输出特征向量 _zt_,Student 输出特征向量 _zs_。 -
**DINO V2 定义了一个 Contrastive Loss (对比损失)**来衡量 _zt_ 和 _zs_ 之间的距离。 Distillation Loss 其实就是一种 Contrastive Loss。。
DINO V2 使用的 Contrastive Loss 具体是什么形式呢? 它采用的是 Cross-Entropy Loss (交叉熵损失) 的变体。为了更好地理解 DINO V2 的 Contrastive Loss,我们先来回顾一下标准的 Cross-Entropy Loss。
在分类任务中,Cross-Entropy Loss 通常用于衡量模型预测的概率分布与真实标签之间的差异。 假设模型预测的概率分布为p = [p_1, p_2, …, p_C],真实标签的 one-hot 向量为 q = [q_1, q_2, …, q_C],其中 C 是类别数。则 Cross-Entropy Loss 定义为:
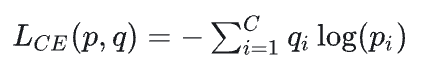
在 DINO V2 中,它将 Cross-Entropy Loss 应用于特征向量之间的对比学习。 具体来说,对于 Teacher 模型输出的特征向量 z_t和 Student 模型输出的特征向量z_s,DINO V2 首先对它们进行 softmax 归一化,得到概率分布 P_t和P_s。然后,DINO V2 将 P_t 作为“伪标签”,使用 Cross-Entropy Loss 来衡量P_s和 P_t 之间的差异。
DINO V2 的 Contrastive Loss 可以表示为:
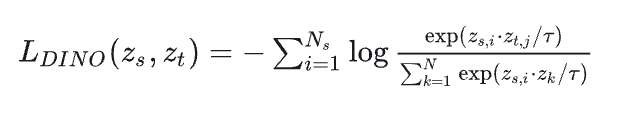
其中:
-
是 Student 模型输出的 个 Local Crops 的特征向量。 -
是 Teacher 模型输出的 个 Global Crops 的特征向量。 -
是所有 Teacher 和 Student 模型输出的特征向量的集合。 -
是 temperature 参数,用于控制 softmax 的平滑程度。
这个 Loss 函数的含义是:对于 Student 模型输出的每个 Local Crop 特征向量 ,我们希望它能够"预测"出 Teacher 模型输出的 Global Crop 特征向量 。也就是说,我们希望 z 和 之间的相似度尽可能高,而 和其他特征向量 (包括其他 Teacher 和 Student模型的输出)之间的相似度尽可能低。
为了进一步提高模型的性能,DINO V2 在 Contrastive Loss 中还引入了以下两个重要的技巧:
-
Centering(中心化):在计算 softmax 之前,DINO V2 对 Teacher 模型的输出特征向量 进行了中心化处理。具体来说,对于 Teacher 模型的输出特征向量 ,DINO V2 计算其均值 ,然后将 减去 ,得到中心化后的特征向量 。中心化的目的是防止模型 collapse(坍塌),即所有样本的特征向量都聚集到同一个点。 -
Sharpening(锐化):DINO V2 对 Teacher 模型的输出概率分布 进行了锐化处理。具体来说,对于 Teacher 模型的输出概率分布 ,DINO V2 使用一个更小的 temperature 参数 来计算 Student 模型的概率分布 。锐化的目的是让 Teacher 模型的概率分布更加 sharp(尖锐),从而提供更明确的学习目标给 Student 模型。
结合 Centering 和 Sharpening,DINO V2 的 Contrastive Loss 可以表示为:

其中 是对应特征向量 的均值(如果 来自 Teacher 模型,则 ,如果 来自 Student 模型,则 )。
总结一下,DINO V2 的对比学习机制可以概括为: 使用 Cross-Entropy Loss 的变体,将 Teacher 模型的 Global Crop 特征向量作为“伪标签”,指导 Student 模型的 Local Crops 特征向量的学习。同时,引入 Centering 和 Sharpening 技巧,进一步提高模型的性能和稳定性。这种对比学习机制,使得 Student 模型能够有效地“看齐” Teacher 模型,学习到高质量的视觉特征。
2.4 知识蒸馏策略:Teacher 模型“传授”知识给 Student 模型
DINO V2 的核心是知识蒸馏,而对比学习机制只是实现知识蒸馏的一种手段。知识蒸馏的最终目的是让 Student 模型学习到 Teacher 模型的“知识”。 那么,什么是“知识”呢?在 DINO V2 中,“知识”主要指的是 Teacher 模型学习到的 **特征表示 (Feature Representation)**。
Teacher 模型为什么能够学习到更好的特征表示呢? 这主要归功于以下几个方面:
-
Global View (全局视角): Teacher 模型处理的是 Global Crop,能够获取图像的全局信息,从而更好地理解图像的整体结构和语义内容。 -
EMA Update (指数移动平均更新): Teacher 模型的参数通过 EMA 方式更新,能够有效地稳定训练过程,并提高模型的泛化能力。 -
更大的模型容量 (可能): 在某些情况下,Teacher 模型可能比 Student 模型具有更大的模型容量 (例如,更深的网络结构或更多的参数)。更大的模型容量通常意味着更强的学习能力。
Student 模型通过对比学习,不断地模仿 Teacher 模型的输出特征,从而学习到 Teacher 模型的“知识”。 这种知识蒸馏策略,就像老师傅带徒弟一样,老师傅 (Teacher 模型) 经验丰富,能够看到问题的全局,徒弟 (Student 模型) 通过模仿老师傅的做法,逐渐掌握问题的本质。
DINO V2 的知识蒸馏策略,有以下几个关键特点:
-
Self-Distillation (自蒸馏): DINO V2 的 Teacher 模型和 Student 模型都是基于同一个网络架构 (Transformer),只是参数更新方式不同。这种 Teacher 模型和 Student 模型来自同一个网络的知识蒸馏方式,被称为 Self-Distillation。Self-Distillation 的优势在于,Teacher 模型和 Student 模型具有相似的特征空间,更容易进行知识迁移。 -
No Labels (无标签): DINO V2 的训练过程完全不需要人工标注的标签,只需要大量的无标注图像数据。这使得 DINO V2 能够充分利用海量的无标注数据,学习到通用的视觉特征。 -
Online Distillation (在线蒸馏): DINO V2 的知识蒸馏过程是 online 的,即 Teacher 模型和 Student 模型是同时训练的,而不是先训练好 Teacher 模型,再用 Teacher 模型来蒸馏 Student 模型。Online Distillation 的优势在于,Teacher 模型和 Student 模型可以相互促进,共同进步。
知识蒸馏策略在 DINO V2 中起到了至关重要的作用。 它使得 Student 模型能够从 Teacher 模型中学习到更丰富的知识,从而在各种下游任务中取得优异的性能。知识蒸馏策略,就像给 Student 模型安装了一个“外挂”,让它能够“站在巨人的肩膀上”,快速成长。
2.5 多尺度特征融合:兼顾全局视野和局部细节
除了 Teacher-Student 架构、Transformer 架构、对比学习机制和知识蒸馏策略之外,DINO V2 还有一个重要的技术细节——**Multi-Scale Feature Fusion (多尺度特征融合)**。
在计算机视觉任务中,图像的全局信息和局部细节信息都非常重要。 全局信息能够帮助模型理解图像的整体结构和语义内容,局部细节信息能够帮助模型识别图像中的细微特征和纹理。为了兼顾全局视野和局部细节,DINO V2 采用了多尺度特征融合的策略。
DINO V2 的多尺度特征融合主要体现在以下两个方面:
-
Multi-Crop Augmentation (多裁剪增强): DINO V2 使用 Multi-Crop Augmentation 策略,对同一张图像裁剪出 Global Crops 和 Local Crops。Global Crops 提供了图像的全局信息,Local Crops 提供了图像的局部细节信息。Teacher 模型处理 Global Crops,Student 模型处理 Local Crops,使得模型能够同时学习到全局和局部的信息。 -
Transformer Encoder 的多层特征: Transformer Encoder 通常由多个 Transformer Block 堆叠而成。不同层的 Transformer Block 学习到的特征具有不同的尺度和抽象程度。浅层特征通常更关注图像的局部细节信息,深层特征通常更关注图像的全局语义信息。DINO V2 可以利用 Transformer Encoder 不同层的输出特征,进行多尺度特征融合。
DINO V2 具体是如何进行多尺度特征融合的呢? 在 DINO V2 的论文中,并没有明确说明如何进行多尺度特征融合。但是,根据 DINO 的论文和一些相关的研究,我们可以推测 DINO V2 可能采用了以下几种多尺度特征融合的方式:
-
特征拼接 (Feature Concatenation): 将 Transformer Encoder 不同层的输出特征向量拼接在一起,形成一个更长的特征向量。这种方式简单直接,但可能会导致特征维度过高。 -
特征加权求和 (Feature Weighted Summation): 对 Transformer Encoder 不同层的输出特征向量进行加权求和。权重可以根据不同的策略进行学习或固定。这种方式可以有效地融合不同尺度的特征,并控制特征的维度。 -
注意力机制 (Attention Mechanism): 使用注意力机制来动态地融合 Transformer Encoder 不同层的输出特征。注意力机制可以根据输入图像的内容,自适应地调整不同尺度特征的权重。
多尺度特征融合能够有效地提高 DINO V2 的性能。 通过融合全局信息和局部细节信息,DINO V2 能够更全面地理解图像内容,并学习到更鲁棒、更有效的视觉特征。多尺度特征融合,就像给 DINO V2 配备了一副“多焦镜头”,让它能够同时看清远处的风景和近处的细节。
2.6 代码示例:DINO V2 的核心代码片段
理论讲了这么多,可能有些小伙伴已经开始“犯困”了。别担心,接下来,我们来点“硬货”——代码示例!俗话说,“Talk is cheap, show me the code!”,让我们通过代码来进一步理解 DINO V2 的核心原理。
这里以 DINO 的代码为例,展示 DINO 算法的核心代码片段,DINO V2 的代码结构和 DINO 类似,可以帮助大家理解 DINO V2 的实现思路。
以下是 DINO 算法的核心代码片段 (PyTorch 实现,简化版):
import torch
import torch.nn as nn
import torch.nn.functional as F
class DINO(nn.Module):
def __init__(self, backbone, num_crops_per_image, student_temp=0.1, teacher_temp=0.04, center_momentum=0.9):
super().__init__()
self.backbone = backbone # Transformer backbone
self.num_crops_per_image = num_crops_per_image
self.student_temp = student_temp
self.teacher_temp = teacher_temp
self.center_momentum = center_momentum
# Teacher model is EMA of student model
self.teacher_backbone = nn.ModuleList([
nn.utils.weight_norm(nn.Linear(backbone.embed_dim, backbone.embed_dim, bias=False)) for _ in range(2)
])
self.teacher_backbone.load_state_dict(self.backbone.state_dict())
for param_q, param_k in zip(self.backbone.parameters(), self.teacher_backbone.parameters()):
param_k.data.copy_(param_q.data) # initialize
param_k.requires_grad = False # not update by gradient
# Student projection head
self.student_proj = nn.Sequential(
nn.Linear(backbone.embed_dim, backbone.embed_dim),
nn.GELU(),
nn.Linear(backbone.embed_dim, backbone.embed_dim)
)
# Teacher projection head
self.teacher_proj = nn.Sequential(
nn.Linear(backbone.embed_dim, backbone.embed_dim),
nn.GELU(),
nn.Linear(backbone.embed_dim, backbone.embed_dim)
)
# Initialize center for centering
self.register_buffer("center", torch.zeros(1, backbone.embed_dim))
@torch.no_grad()
def _update_teacher(self, m):
"""Momentum update of the teacher network."""
for param_q, param_k in zip(self.backbone.parameters(), self.teacher_backbone.parameters()):
param_k.data.mul_(m).add_((1 - m) * param_q.detach().data)
@torch.no_grad()
def _center_teacher(self, teacher_output):
"""Center teacher output to prevent mode collapse."""
batch_center = torch.sum(teacher_output, dim=0, keepdim=True)
batch_center = batch_center / len(teacher_output)
# ema update
self.center = self.center * self.center_momentum + batch_center * (1 - self.center_momentum)
return teacher_output - self.center
def forward(self, images):
# Split into global and local crops
global_crops = images[:2] # Assume first 2 crops are global
local_crops = images[2:] # Assume remaining crops are local
# Student forward pass
student_output = self.backbone(torch.cat(local_crops, dim=0)) # Process all local crops together
student_output = self.student_proj(student_output)
student_output = F.normalize(student_output, dim=-1) # L2 normalization
# Teacher forward pass
with torch.no_grad(): # No gradient for teacher
self._update_teacher(self.center_momentum) # EMA update teacher parameters
teacher_output = self.teacher_backbone(torch.cat(global_crops, dim=0)) # Process all global crops together
teacher_output = self.teacher_proj(teacher_output)
teacher_output = F.normalize(teacher_output, dim=-1) # L2 normalization
teacher_output = self._center_teacher(teacher_output) # Centering
# DINO loss
loss = 0
n_loss_terms = 0
for i, crops in enumerate([local_crops]): # Only contrast local crops to global crops
for s_idx in range(len(crops)):
for t_idx in range(len(global_crops)):
student_out = student_output[s_idx]
teacher_out = teacher_output[t_idx]
loss += -torch.sum(teacher_out * F.log_softmax(student_out / self.student_temp, dim=-1), dim=-1).mean()
n_loss_terms += 1
loss /= n_loss_terms
return loss
代码示例虽然简化了,但已经包含了 DINO 算法的核心思想: Teacher-Student 架构、Transformer backbone、对比学习机制、知识蒸馏策略、Centering 等关键技术。通过阅读代码,相信大家对 DINO V2 的算法原理有了更直观的理解。
需要注意的是,DINO V2 在 DINO 的基础上进行了很多改进和优化,例如更强大的 Transformer backbone、更大的模型规模、更有效的训练策略等。 这些改进使得 DINO V2 在性能上超越了 DINO,并在通用视觉特征提取方面取得了更大的突破。
3. 创新点分析:DINO V2 的“独门秘籍”
经过前面的“庖丁解牛”,我们已经对 DINO V2 的算法原理有了深入的了解。接下来,我们要聚焦 DINO V2 的 创新点,看看它究竟有哪些“独门秘籍”,能够超越 DINO 和其他自监督算法,成为自监督学习领域的新标杆。
3.1 更强大的 Transformer Backbone:从 ViT 到更大的模型
DINO V2 的第一个创新点,也是最直观的创新点,就是使用了 更强大的 Transformer Backbone。DINO 最初使用的是相对较小的 ViT 模型 (例如 ViT-Small, ViT-Base),而 DINO V2 则使用了更大规模的 Transformer 模型,例如 ViT-Large, ViT-Huge。
模型规模的增大,通常意味着模型容量的提升。 更大的模型容量,意味着模型能够学习到更复杂的函数关系,从而更好地捕捉图像中的信息。在深度学习领域,模型规模的增大往往能够带来性能的提升,尤其是在数据量充足的情况下。
DINO V2 使用更大规模的 Transformer Backbone,带来了以下几个方面的优势:
-
更强的特征提取能力: 更大的 Transformer 模型具有更强的特征提取能力,能够学习到更丰富、更抽象的视觉特征。 -
更好的模型泛化能力: 更大的模型通常具有更好的泛化能力,能够更好地适应不同的数据集和任务。 -
更高的下游任务性能: 更强大的 Backbone 能够为下游任务提供更优质的特征表示,从而提高下游任务的性能。
DINO V2 不仅使用了更大规模的 Transformer 模型,还在 Transformer 的结构细节上进行了一些优化。 例如,DINO V2 可能使用了更深的网络层数、更大的 hidden dimension、更多的 attention heads 等。这些结构上的优化,进一步提升了 Transformer Backbone 的性能。
当然,模型规模的增大也带来了计算成本的增加。 更大规模的 Transformer 模型需要更多的计算资源和更长的训练时间。但是,考虑到 DINO V2 在性能上的巨大提升,以及自监督学习在减少标注成本方面的优势,这种计算成本的增加是值得的。
总而言之,更强大的 Transformer Backbone 是 DINO V2 的一个重要创新点。 它为 DINO V2 提供了更强大的“发动机”,使其能够跑得更快、更远。
3.2 更有效的训练策略:更大的数据集和更长的训练时间
除了更强大的 Backbone 之外,DINO V2 还采用了 更有效的训练策略,包括使用 更大的数据集 和 更长的训练时间。
数据是深度学习的“燃料”。 更大的数据集能够为模型提供更丰富的训练样本,使其学习到更鲁棒、更通用的特征。DINO V2 使用了比 DINO 更大的数据集进行训练,例如 LAION-2B 等大规模无标注图像数据集。
训练时间是深度学习的“催化剂”。 更长的训练时间能够让模型更充分地学习数据中的信息,并达到更好的收敛状态。DINO V2 使用了比 DINO 更长的训练时间进行训练,例如 数周甚至数月。
更大的数据集和更长的训练时间,为 DINO V2 的性能提升提供了坚实的基础。 它们就像给 DINO V2 提供了更多的“粮食”和更充足的“时间”,使其能够茁壮成长。
需要注意的是,仅仅增大数据集和训练时间,并不一定能够带来性能的提升。 还需要配合合适的算法和模型结构,才能充分发挥大数据和长训练时间的优势。DINO V2 在算法和模型结构方面也进行了精心的设计和优化,才使得更大的数据集和更长的训练时间能够转化为实实在在的性能提升。
总而言之,更有效的训练策略是 DINO V2 的另一个重要创新点。 它为 DINO V2 的性能提升提供了强有力的保障。
3.3 更广泛的应用场景:通用视觉特征的潜力
DINO V2 的一个重要突破在于,它展现了 通用视觉特征 (General-Purpose Visual Features) 的巨大潜力。DINO V2 学习到的特征,不仅在图像分类等传统任务上表现出色,还在 语义分割、深度估计、图像检索、视频理解 等更广泛的视觉任务中取得了令人瞩目的成果。
通用视觉特征的意义在于,它可以作为各种视觉任务的“基石”。 有了通用的视觉特征,我们就可以在不同的视觉任务中共享同一个特征提取器,而只需要针对特定任务训练简单的 task-specific head (任务特定头)。这大大降低了模型开发的成本和复杂度,并提高了模型的泛化能力。
DINO V2 能够学习到通用视觉特征,得益于以下几个方面:
-
自监督学习的本质: 自监督学习的目标是从无标注数据中学习通用的表示,而不是针对特定任务进行优化。这使得自监督学习天然地具有学习通用特征的潜力。 -
Transformer 架构的优势: Transformer 架构具有强大的特征提取能力和灵活的结构设计,能够学习到更抽象、更通用的特征表示。 -
大规模数据集的训练: 使用大规模数据集进行训练,能够让模型学习到更丰富、更通用的特征,并提高模型的泛化能力。
DINO V2 在各种下游任务中的出色表现,证明了自监督学习在通用视觉特征提取方面的巨大潜力。 DINO V2 的成功,也为未来的自监督学习研究指明了方向——朝着更通用、更强大的视觉特征表示迈进。
总而言之,更广泛的应用场景是 DINO V2 的又一个重要创新点。 它展现了自监督学习在通用视觉特征提取方面的巨大潜力,并为未来的视觉任务应用开辟了新的道路。
3.4 实验验证:DINO V2 的性能“遥遥领先”
光说不练假把式,光说创新点还不够,我们还要用 实验数据 来验证 DINO V2 的性能。DINO V2 的论文中,提供了大量的实验结果,证明了 DINO V2 在各种视觉任务上的性能 “遥遥领先”。
在图像分类任务上,DINO V2 在 ImageNet-1K 基准数据集上取得了 SOTA (State-of-the-Art,最先进) 的性能。 例如,使用 ViT-Huge 模型,DINO V2 在 ImageNet-1K 上的 top-1 accuracy 达到了 **87.3%**,超越了之前的 DINO 和其他自监督算法。
在目标检测和语义分割任务上,DINO V2 也取得了显著的性能提升。 例如,在 COCO 目标检测数据集上,使用 DINO V2 预训练的 Backbone,目标检测模型的 mAP (mean Average Precision,平均精度均值) 提升了 数个百分点。在 ADE20K 语义分割数据集上,DINO V2 也取得了类似的性能提升。
更令人惊喜的是,DINO V2 在 zero-shot transfer (零样本迁移) 任务上表现出色。 Zero-shot transfer 指的是模型在没有见过目标任务标注数据的情况下,直接应用于目标任务。DINO V2 在 zero-shot 图像分类、zero-shot 目标检测等任务上,都取得了令人印象深刻的成绩,展现了其强大的通用特征表示能力。
DINO V2 的实验结果充分证明了其算法的有效性和创新性。 DINO V2 不仅在性能上超越了之前的自监督算法,更重要的是,它展现了自监督学习在通用视觉特征提取方面的巨大潜力,为未来的视觉任务应用开辟了新的道路。
为了更直观地展示 DINO V2 的性能,我们可以用一些图表来对比 DINO V2 与其他自监督算法的性能。 例如,下图展示了 DINO V2 和其他自监督算法在 ImageNet-1K 上的 top-1 accuracy 对比:
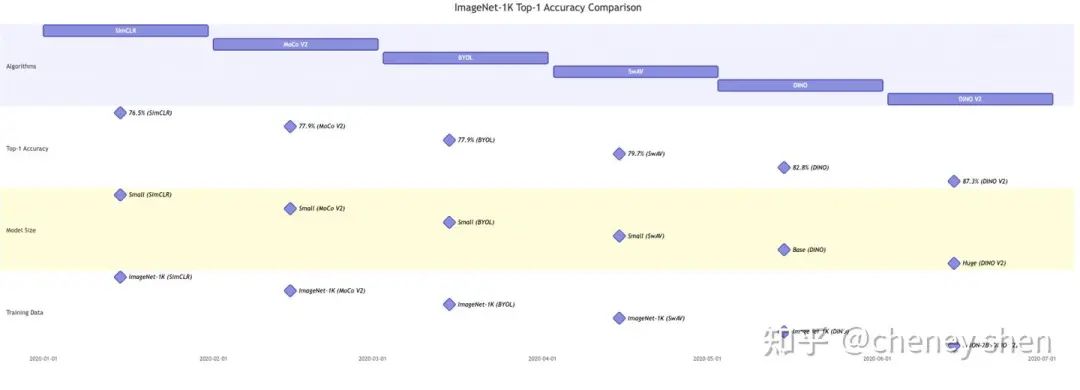
从图中我们可以清晰地看到,DINO V2 在 ImageNet-1K 上的 top-1 accuracy 显著高于其他自监督算法,达到了 87.3%。 虽然 DINO V2 使用了更大的模型规模、更大的数据集和更长的训练时间,但其性能提升的幅度仍然令人印象深刻,证明了 DINO V2 算法的有效性和创新性。
3.5 应用场景:DINO V2 的“用武之地”
DINO V2 作为一种通用的视觉特征提取器,其应用场景非常广泛。除了前面提到的图像分类、目标检测、语义分割等传统任务之外,DINO V2 还可以应用于以下场景:
-
图像检索 (Image Retrieval): DINO V2 学习到的特征可以用于图像检索任务。通过计算图像特征之间的相似度,可以快速地在海量图像库中找到与查询图像相似的图像。 -
视频理解 (Video Understanding): DINO V2 可以扩展到视频领域,用于视频分类、视频目标检测、视频行为识别等任务。通过提取视频帧的 DINO V2 特征,可以有效地理解视频内容。 -
跨模态学习 (Cross-Modal Learning): DINO V2 可以与其他模态 (例如文本、音频) 的特征进行对齐,实现跨模态学习。例如,可以将 DINO V2 学习到的图像特征与文本描述进行对齐,实现图像-文本检索、图像描述生成等任务。 -
Few-Shot Learning (少样本学习): DINO V2 学习到的通用特征可以用于少样本学习任务。在少样本学习中,每个类别只有少量标注样本,DINO V2 的通用特征可以作为先验知识,帮助模型快速适应新的类别。 -
Domain Adaptation (领域自适应): DINO V2 学习到的通用特征可以用于领域自适应任务。在领域自适应中,训练数据和测试数据来自不同的领域,DINO V2 的通用特征可以减少领域差异,提高模型的泛化能力。
DINO V2 的应用场景还在不断扩展中。 随着自监督学习技术的不断发展,相信 DINO V2 及其类似的算法,将在越来越多的视觉任务中发挥重要作用,成为计算机视觉领域的“瑞士军刀”。
4. 问题解决与效果评估:DINO V2 的“攻坚克难”
DINO V2 的成功并非偶然,它解决了一系列自监督学习领域长期存在的难题,并在效果上取得了显著的提升。本节我们将深入探讨 DINO V2 解决的核心问题,以及如何 评估 DINO V2 的效果。
4.1 DINO V2 解决的核心问题:从“数据饥渴”到“特征通用”
自监督学习的目标是让模型从无标注数据中学习知识,从而摆脱对标注数据的依赖。然而,早期的自监督学习算法,例如 Autoencoder、VAE 等,虽然能够学习到一些特征表示,但这些特征往往 质量不高,泛化能力差,难以应用于下游任务。
DINO V2 主要解决了以下几个核心问题:
-
如何从无标注数据中学习到高质量的视觉特征? 这是自监督学习最核心的问题。DINO V2 通过 Teacher-Student 架构、Transformer Backbone、对比学习机制、知识蒸馏策略等一系列技术手段,有效地解决了这个问题,学习到了高质量的视觉特征。 -
如何提高自监督学习模型的泛化能力? 早期的自监督学习模型,往往在训练数据上表现良好,但在测试数据上性能下降明显,泛化能力较差。DINO V2 通过更大规模的数据集、更长的训练时间、更强大的模型结构等手段,有效地提高了模型的泛化能力。 -
如何让自监督学习模型学习到通用的视觉特征? 早期的自监督学习模型,学习到的特征往往是 task-specific (任务特定的),难以应用于其他任务。DINO V2 通过自监督学习的本质、Transformer 架构的优势、大规模数据集的训练等手段,使得模型学习到了通用的视觉特征。 -
如何降低自监督学习的计算成本? 自监督学习通常需要处理海量无标注数据,训练时间长,计算成本高昂。DINO V2 虽然使用了更大规模的模型和数据集,但其算法设计本身也具有一定的效率,例如 Teacher-Student 架构可以并行训练,Transformer 架构具有高效的计算性能等。
DINO V2 针对这些问题提出了有效的解决方案,并在效果上取得了显著的提升。 DINO V2 的成功,标志着自监督学习技术迈向了一个新的阶段——从“数据饥渴”到“特征通用”。
4.2 效果评估指标:量化 DINO V2 的“实力”
为了客观地评估 DINO V2 的效果,我们需要采用合适的 评估指标。DINO V2 的效果评估主要从以下几个方面进行:
-
下游任务性能: 这是评估自监督学习模型最直接、最常用的指标。通过将 DINO V2 预训练的 Backbone 应用于各种下游任务 (例如图像分类、目标检测、语义分割),并比较其性能与其他算法的性能,可以评估 DINO V2 的特征质量和泛化能力。常用的下游任务性能指标包括:
-
图像分类: Top-1 accuracy, Top-5 accuracy
-
目标检测: mAP (mean Average Precision)
-
语义分割: mIOU (mean Intersection over Union)
-
Zero-Shot Transfer 性能: Zero-Shot Transfer 性能能够更直接地反映模型的通用特征表示能力。通过评估 DINO V2 在 zero-shot 图像分类、zero-shot 目标检测等任务上的性能,可以评估 DINO V2 的特征通用性。常用的 Zero-Shot Transfer 性能指标包括:
-
Zero-Shot 图像分类: Zero-Shot Top-1 accuracy
-
Zero-Shot 目标检测: Zero-Shot mAP
-
特征可视化: 特征可视化能够帮助我们直观地理解模型学习到的特征表示。通过可视化 DINO V2 学习到的特征,例如使用 t-SNE 或 UMAP 等降维方法将高维特征映射到二维空间,并观察特征的聚类情况,可以评估 DINO V2 的特征可解释性和语义信息。
-
消融实验 (Ablation Study): 消融实验能够帮助我们分析 DINO V2 中各个组件 (例如 Teacher-Student 架构、Contrastive Loss、Centering 等) 对性能的贡献。通过逐步移除或替换 DINO V2 的不同组件,并观察性能的变化,可以评估各个组件的重要性。
DINO V2 的论文中,采用了以上多种评估指标,全面地评估了 DINO V2 的效果。 实验结果表明,DINO V2 在各种评估指标上都取得了优异的成绩,证明了 DINO V2 的算法有效性和创新性。
这些只是 DINO V2 应用场景的冰山一角。 随着 DINO V2 技术的不断成熟和普及,相信它将在越来越多的领域发挥重要作用,为人类社会带来更多的便利和价值。
5. 改进空间探讨:DINO V2 的“未来之路”
DINO V2 虽然取得了巨大的成功,但任何算法都不是完美的,DINO V2 也不例外。本节我们将客观分析 DINO V2 的 局限性,并探讨其 潜在的改进方向 和 未来发展趋势。
5.1 DINO V2 的局限性:仍需“精雕细琢”
DINO V2 虽然性能强大,但仍然存在一些局限性,主要体现在以下几个方面:
-
计算复杂度高: DINO V2 使用了大规模的 Transformer 模型,训练时间长,计算资源消耗大。这限制了 DINO V2 在资源受限场景下的应用,例如移动设备、嵌入式系统等。 -
对超参数敏感: DINO V2 的性能受到超参数 (例如 temperature 参数、momentum 参数、学习率等) 的影响较大。超参数的调优需要大量的实验和经验,增加了模型训练的难度。 -
理论解释性不足: 虽然 DINO V2 在实践中表现出色,但其背后的理论机制仍有待深入研究。例如,为什么 Teacher-Student 架构和对比学习机制能够有效地学习到高质量的特征?为什么 Centering 和 Sharpening 能够提高模型性能?这些问题 masih 需要更深入的理论分析。 -
长尾分布问题: 在真实世界的数据集中,往往存在长尾分布问题,即某些类别的样本数量远多于其他类别。DINO V2 在处理长尾分布数据时,可能会存在性能瓶颈。 -
对抗攻击脆弱性: 深度学习模型普遍存在对抗攻击脆弱性问题,DINO V2 也不例外。对抗攻击指的是,通过对输入图像进行微小的、人眼难以察觉的扰动,就可以使模型预测结果发生错误。DINO V2 在对抗攻击下的鲁棒性 masih 需要进一步提高。
这些局限性,也为 DINO V2 的未来改进指明了方向。 未来的研究可以针对这些局限性进行改进和优化,使 DINO V2 更加完美。
5.2 未来发展方向:DINO V2 的“进化之路”
针对 DINO V2 的局限性,以及自监督学习领域的整体发展趋势,我们可以展望 DINO V2 的 未来发展方向:
-
模型压缩与加速: 为了降低 DINO V2 的计算复杂度,可以采用模型压缩和加速技术,例如模型剪枝 (Pruning)、模型量化 (Quantization)、知识蒸馏 (Knowledge Distillation) 等。目标是减小模型规模,加快推理速度,使其能够应用于资源受限场景。 -
自适应超参数调整: 为了解决 DINO V2 对超参数敏感的问题,可以研究自适应超参数调整方法。例如,可以使用强化学习、贝叶斯优化等技术,自动地搜索和调整最优超参数,减少人工调参的成本和难度。 -
理论分析与解释: 为了深入理解 DINO V2 的工作原理,需要加强理论分析和解释性研究。例如,可以使用信息论、表示学习理论等工具,分析 DINO V2 的特征表示性质,揭示其成功背后的理论机制。 -
长尾分布鲁棒性: 为了提高 DINO V2 在长尾分布数据上的鲁棒性,可以研究长尾分布学习方法。例如,可以使用重采样 (Re-sampling)、重加权 (Re-weighting)、元学习 (Meta-Learning) 等技术,平衡不同类别样本的学习难度,提高模型在少数类别上的性能。 -
对抗鲁棒性: 为了提高 DINO V2 的对抗鲁棒性,可以研究对抗训练 (Adversarial Training) 等技术。通过在训练过程中引入对抗样本,增强模型对对抗攻击的防御能力,提高模型的安全性。 -
多模态融合: 未来的 DINO V2 可以与其他模态 (例如文本、音频) 的信息进行融合,实现多模态自监督学习。多模态融合可以利用不同模态之间的互补信息,学习到更丰富、更全面的特征表示。 -
持续学习与终身学习: 未来的 DINO V2 可以具备持续学习和终身学习能力,使其能够不断地从新的数据和任务中学习知识,并适应不断变化的环境。持续学习和终身学习是人工智能发展的长期目标,也是 DINO V2 未来发展的重要方向。
DINO V2 的未来之路,充满机遇和挑战。 相信随着技术的不断进步和研究的深入,DINO V2 将会不断进化,变得更加强大、更加通用、更加智能。
5.3 改进建议:为 DINO V2 “添砖加瓦”
作为 DINO V2 的“粉丝”和“研究者”,我也想为 DINO V2 的改进提出一些 具体的建议,希望能为 DINO V2 的发展“添砖加瓦”:
-
开源代码和预训练模型: 希望 DINO V2 的作者能够尽快开源代码和预训练模型,方便研究人员和开发者使用和研究 DINO V2,共同推动自监督学习技术的发展。 -
提供更详细的实验细节: DINO V2 的论文中,实验细节可能不够详细,例如超参数设置、训练策略、数据增强方式等。希望作者能够提供更详细的实验细节,方便其他研究人员复现和改进 DINO V2。 -
探索更有效的知识蒸馏策略: DINO V2 使用的知识蒸馏策略是基于对比学习的,未来可以探索更有效的知识蒸馏策略,例如基于特征对齐 (Feature Alignment)、基于关系建模 (Relational Modeling) 等的知识蒸馏方法,进一步提高知识迁移的效率和质量。 -
研究更鲁棒的 Transformer 架构: Transformer 架构虽然强大,但仍然存在一些局限性,例如计算复杂度高、对输入长度敏感等。未来可以研究更鲁棒的 Transformer 架构,例如稀疏注意力 (Sparse Attention)、线性注意力 (Linear Attention) 等,提高 Transformer 的效率和鲁棒性。 -
拓展到更多视觉任务: DINO V2 目前主要在图像分类、目标检测、语义分割等任务上进行了验证,未来可以拓展到更多视觉任务,例如图像生成、视频理解、3D 视觉等,进一步验证 DINO V2 的通用性和泛化能力。
这些建议,只是我个人的一些思考和展望。 DINO V2 的未来发展,还需要更多的研究人员共同努力,不断探索和创新。
6. 总结与展望:自监督学习的“星辰大海”
各位老铁们,经过一番“深度游览”,相信大家对 DINO V2 算法已经有了全面而深入的了解。DINO V2 的出现,无疑是自监督学习领域的一个里程碑事件。 它不仅在性能上超越了之前的算法,更重要的是,它展现了自监督学习在通用视觉特征提取方面的巨大潜力,为未来的视觉任务应用开辟了新的道路。
DINO V2 的核心思想可以概括为: 使用 Teacher-Student 架构,Transformer Backbone,对比学习机制,知识蒸馏策略,多尺度特征融合等技术手段,从海量无标注数据中学习高质量、通用性的视觉特征。
DINO V2 的重要贡献可以总结为:
-
提出了更强大的自监督学习算法: DINO V2 在图像分类、目标检测、语义分割等任务上取得了 SOTA 性能,超越了之前的自监督算法。 -
展现了通用视觉特征的潜力: DINO V2 学习到的特征具有很强的通用性,可以应用于各种视觉任务,并取得了良好的效果。 -
推动了自监督学习技术的发展: DINO V2 的成功,激发了更多研究人员对自监督学习的兴趣,加速了自监督学习技术的发展。
展望未来,自监督学习仍然是一个充满活力和机遇的研究领域。 随着数据量的不断增长,计算能力的不断提升,以及算法的不断创新,自监督学习将在人工智能领域发挥越来越重要的作用。
我相信,未来的计算机视觉系统,将不再依赖大量的标注数据,而是能够像人类一样,从海量无标注数据中自主学习知识,实现真正的“智能”。 而 DINO V2,正是朝着这个目标迈出的重要一步。
自监督学习的未来,是星辰大海! 让我们一起期待,自监督学习技术在未来能够带给我们更多的惊喜和突破!
(文:极市干货)