浙大80后博导造四足机器人,又融了5亿,达晨、国新领投

杭州六小龙之一的云深处宣布完成近5亿元融资,该轮融资将重点投向四足机器人产线扩建、人形机器人技术研发及高端人才引进,并加快新产品的商业化落地。公司成立于2017年11月,已完成8轮融资。
杭州六小龙之一的云深处宣布完成近5亿元融资,该轮融资将重点投向四足机器人产线扩建、人形机器人技术研发及高端人才引进,并加快新产品的商业化落地。公司成立于2017年11月,已完成8轮融资。

浙江大学联合阿里巴巴集团推出的OmniAvatar模型在音频驱动全身视频生成领域实现了突破性进展,支持自然、逼真的表情和动作同步,并广泛应用于虚拟形象制作、互动社交平台、教育培训等多个领域。
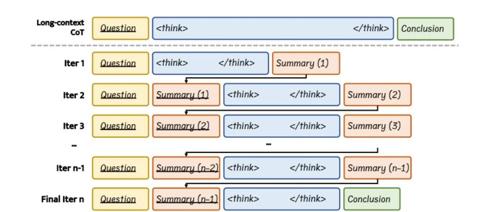
浙江大学和北京大学联合推出InftyThink模型,通过分段迭代推理和中间总结突破传统长推理任务限制,显著降低计算复杂度并保持推理准确性和效率。
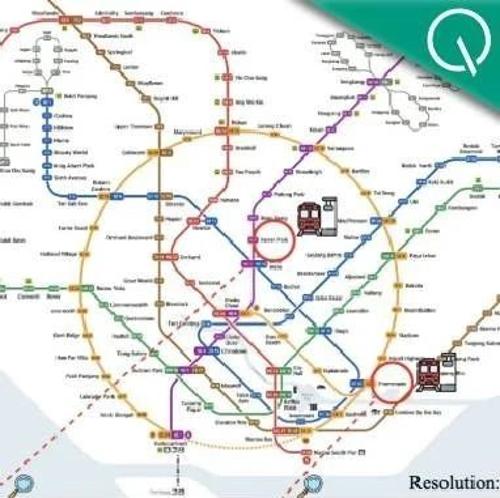
近年来多模态大模型在理解和复杂推理任务中取得进展,但其对高分辨率图像(如地铁图)的理解能力仍存争议。为此,西湖大学、新加坡国立大学等团队提出ReasonMap评测基准,聚焦于高分辨率交通图的多模态推理,发现当前开源模型存在性能瓶颈,并指出强化学习后训练模型在某些维度上优于现有模型。

2025年5月26日,Datawhale与字节跳动扣子空间联合主办‘AI+X高校行’首场活动在北大启动,聚焦Agent技术普及,覆盖百所高校,提供从理论到实践的学习体验。

浙江大学和哈佛大学的研究团队推出了In-Context Edit(ICEdit),一款基于指令的图像编辑框架,仅需极少的文本指令即可实现精准的图像修改。