
语音识别

多模态语音表征新突破!CoGenAV:高效、鲁棒、通用的语音识别“利器”
通义联合深圳技术大学推出的CoGenAV模型通过融合音频和视觉信息,显著提升了语音识别和处理性能。仅需223小时标记数据即可训练,展现出极高的数据效率,并在多种语音处理任务中表现出色。


英伟达开源6亿参数的语音识别模型Parakeet TDT 0.6B V2
英伟达开源Parakeet TDT 0.6B V2语音识别模型,RTFx 3380排名榜首,具备精准时间戳、智能标点和特殊场景识别能力,支持多种应用场景。
新型轻量级音频模型问世!1.5B参数挑战 Whisper 与 Qwen2-Audio!
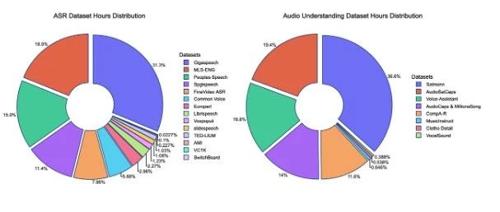
一款名为Aero-1-Audio的新型音频模型发布,参数仅有1.5B但性能出色,支持长音频处理、语音识别和音频理解任务。训练时间短且资源占用低,适用于语音助手、实时转写等场景。
语音领域ISCA Fellow 2025公布:上海交大俞凯、台大李宏毅等三位华人入选

ISCA Fellow 2025揭晓,8位华人学者入选。包括思必驰俞凯、中国台湾大学李宏毅及A*STAR Nancy Chen等多位专家。
【保姆级教程】用Cursor秒搞定小程序语音转文字!科大讯飞API免费额度太香了!

讯飞作为语音识别领头羊,提供5万次免费语音转文字服务。作者分享了从注册账号到使用WebSocket接口的全流程经验,并指导如何通过腾讯云函数生成鉴权URL实现微信小程序开发中的API调用。
5500颗星,完全开源的数字人实时交互平台项目

DUIX是硅基智能的AI数字人交互平台,已获5.5k星,支持多方大模型接入及语音识别、合成技术,适用于智能客服等场景,提供一站式多模态实时交互SDK集成方案。