
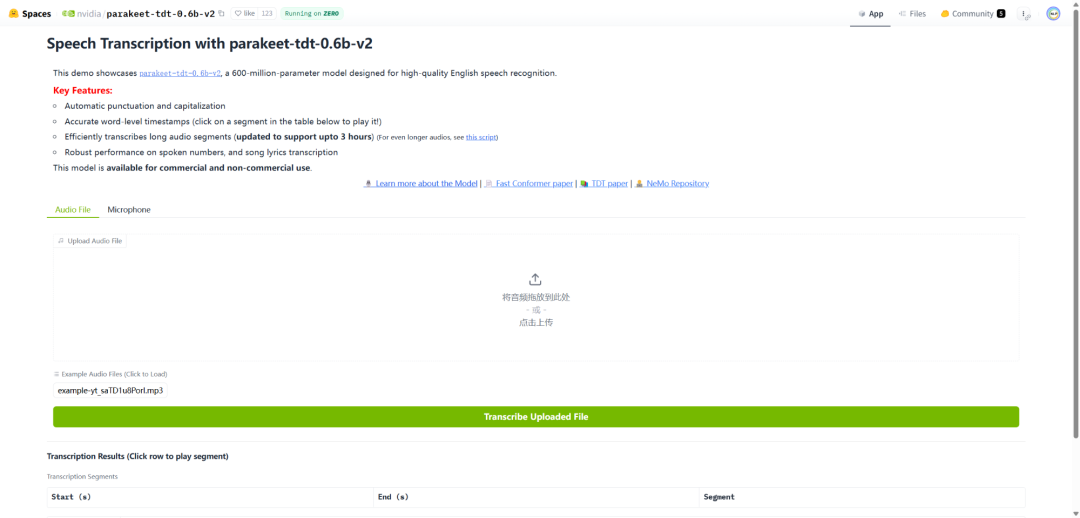
英伟达开源6亿参数的语音识别模型Parakeet TDT 0.6B V2,模型在HuggingFace Open-ASR榜单上以RTFx 3380的成绩登顶。这款语音模型适用于多种需要语音转文字功能的场景,包括但不限于语音助手、会议记录、采访整理、字幕生成和客服质检。它具有三个特点:
1、字级时间戳精准预测:每个单词的出现时间都能精确定位
2、智能标点与自动大写:口语转文字自动加句号逗号,自动首字母大写
3、超强特殊场景识别:口语数字准确转换、歌词转录都不在话下
再来看一些技术层面的亮点:
-
采用FastConformer编码器+TDT解码器架构,可处理长达24分钟的音频片段 -
总训练数据量达12万小时,结合了人工标注和伪标注数据源,包括LibriSpeech、Fisher、YTC、YODAS等数据集。 -
可通过NVIDIA NeMo获取,针对GPU推理进行了优化,使用pip install -U nemo_toolkit[‘asr’]命令即可安装。 -
兼容Linux系统,支持Ampere、Blackwell、Hopper、Volta GPU架构,最低需要2GB显存。
用于训练的Granary数据集还会在Interspeech 2025会议后公开。需要提醒一下各位,想要训练、微调或体验这个模型,需要先安装NVIDIA NeMo框架。建议在安装最新版PyTorch后再进行安装。
参考文献:
[1] Demo链接:https://huggingface.co/spaces/nvidia/parakeet-tdt-0.6b-v2
[2] 项目主页:https://huggingface.co/nvidia/parakeet-tdt-0.6b-v2
知识星球服务内容:Dify源码剖析及答疑,Dify对话系统源码,NLP电子书籍报告下载,公众号所有付费资料。加微信buxingtianxia21进NLP工程化资料群。
(文:NLP工程化)