
随着语音助手、会议转写等应用的普及,轻量级、高性能的音频模型需求也日益增长。
Aero-1-Audio 是一款新型的1.5B参数音频模型,由 LMMs-Lab 开发,基于 Qwen-2.5-1.5B 构建。
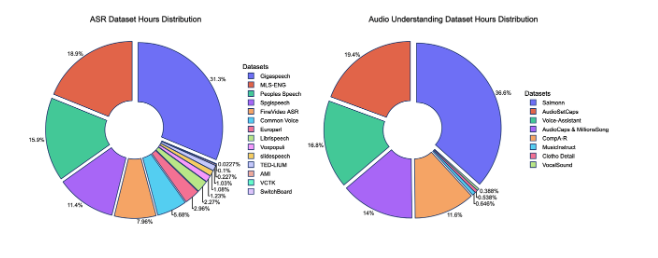
在语音识别(ASR)、音频理解和指令遵循任务中表现出色,部分基准超越 Whisper 和 Qwen2-Audio,尤其在参数效率和长音频处理上独树一帜。
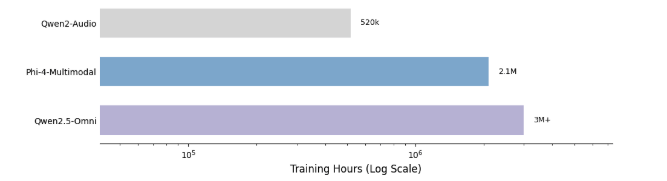
训练仅需 16 个 H100 GPU 和 50k 小时音频数据(约 5B 令牌),耗时不到 24 小时。其独特能力是处理长达 15 分钟的连续音频,无需分段,保持上下文连贯性。
核心功能
-
• 轻量模型体积:仅 1.5B 参数 -
• 支持长音频:可处理最长 15 分钟连续语音,无需分段,可保持上下文连贯 -
• 语音识别(ASR):在语音识别准确率高 -
• 音频理解:支持复杂音频分析(如语音、音效、音乐)和指令驱动任务
快速上手
Aero-1-Audio 支持 Hugging Face Transformers,推荐 GPU 环境(至少 6GB 显存)。
当然 Aero-1-Audio 也提供有HF体验地址(地址在文末)。
安装步骤
① 安装最新 Transformers
pip install transformers@git+https://github.com/huggingface/transformers@v4.51.3-Qwen2.5-Omni-preview② 安装音频处理库
pip install librosa使用示例:
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
import librosa
def load_audio():
return librosa.load(librosa.ex("libri1"), sr=16000)[0]
# 加载模型
processor = AutoProcessor.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", device_map="cuda", torch_dtype="auto", attn_implementation="flash_attention_2", trust_remote_code=True)
model.eval()
messages = [
{
"role": "user",
"content": [
{
"type": "audio_url",
"audio": "placeholder",
},
{
"type": "text",
"text": "Please transcribe the audio",
}
]
}
]
audios = [load_audio()]
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, audios=audios, sampling_rate=16000, return_tensors="pt")
inputs = {k: v.to("cuda") for k, v in inputs.items()}
outputs = model.generate(**inputs, eos_token_id=151645, max_new_tokens=4096)
cont = outputs[:, inputs["input_ids"].shape[-1] :]
print(processor.batch_decode(cont, skip_special_tokens=True)[0])批量推理示例:
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
import librosa
def load_audio():
return librosa.load(librosa.ex("libri1"), sr=16000)[0]
def load_audio_2():
return librosa.load(librosa.ex("libri2"), sr=16000)[0]
processor = AutoProcessor.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", trust_remote_code=True)
# We encourage to use flash attention 2 for better performance
# Please install it with `pip install --no-build-isolation flash-attn`
# If you do not want flash attn, please use sdpa or eager`
model = AutoModelForCausalLM.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", device_map="cuda", torch_dtype="auto", attn_implementation="flash_attention_2", trust_remote_code=True)
model.eval()
messages = [
{
"role": "user",
"content": [
{
"type": "audio_url",
"audio": "placeholder",
},
{
"type": "text",
"text": "Please transcribe the audio",
}
]
}
]
messages = [messages, messages]
audios = [load_audio(), load_audio_2()]
processor.tokenizer.padding_side="left"
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, audios=audios, sampling_rate=16000, return_tensors="pt", padding=True)
inputs = {k: v.to("cuda") for k, v in inputs.items()}
outputs = model.generate(**inputs, eos_token_id=151645, pad_token_id=151643, max_new_tokens=4096)
cont = outputs[:, inputs["input_ids"].shape[-1] :]
print(processor.batch_decode(cont, skip_special_tokens=True))应用场景推荐
-
• 语音助手:做脱网语音控制、对话助手 -
• 实时转写:在课堂中捕捉长时间讲解并输出笔记摘要 -
• 会议纪要:会议音频实时转写、智能标签、关键词提取 -
• 归档理解:为录音库添加内容标签,按语义搜索 -
• 听力模块:赋予 Agent 多轮长语音的理解能力
写在最后
Aero-1-Audio,一个名字很“低调”、却性能炸裂的音频模型。
虽然参数只有 1.5B,却能跟 Whisper、Qwen-2-Audio 一较高下!
大模型火了之后,大家都在比谁的参数多、谁能处理更复杂的任务。但其实各种场景下对语音模型的要求不是“炫技”,而是:识别准、长语音、离线、低延迟等要求。
而 Aero-1-Audio 就很匹配,它提供了一个性能与资源占用双优的方案。
如果你在寻找一个能“稳跑、听得懂、资源吃得少”的语音处理模型,Aero-1-Audio 无疑是目前最值得尝试的之一。
HF模型:https://huggingface.co/lmms-lab/Aero-1-Audio
HF体验:https://huggingface.co/spaces/lmms-lab/Aero-1-Audio-Demo

● 一款改变你视频下载体验的神器:MediaGo
● 新一代开源语音库CoQui TTS冲到了GitHub 20.5k Star
● 最新最全 VSCODE 插件推荐(2023版)
● Star 50.3k!超棒的国产远程桌面开源应用火了!
● 超牛的AI物理引擎项目,刚开源不到一天,就飙升到超9K Star!突破物理仿真极限!

(文:开源星探)