
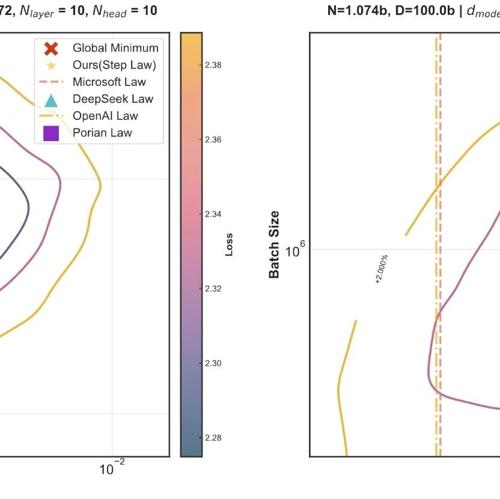
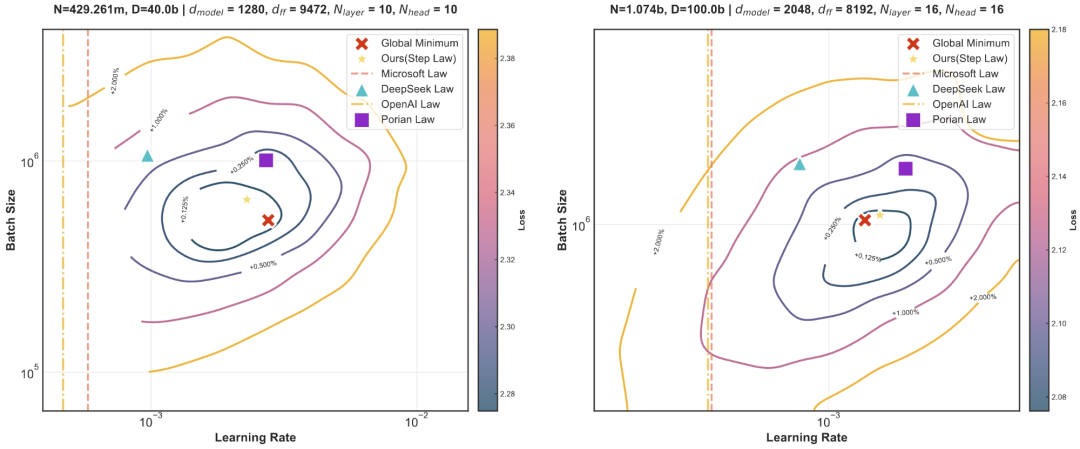
研究团队从头训练了 3,700 个不同规模、不同超参数组合、不同形状、不同数据配比、不同稀疏度 (含 MoE、Dense) 的大语言模型(LLM),共训练了超 100 万亿个 token,对超参数进行了全面的网格搜索,研究团队发现了一条普适的缩放法则 (简称 Step Law):最优学习率随模型参数规模与数据规模呈幂律变化,而最优批量大小主要与数据规模相关。
参考文献:
[1] 论文链接:https://arxiv.org/abs/2503.04715
[2] 工具链接:https://step-law.github.io/
[3] 开源地址:https://github.com/step-law/steplaw
[4] 训练过程:https://wandb.ai/billzid/predictable-scale
(文:NLP工程化)