

今天是2025年6月19日,星期四,北京,晴
我们来看一个多模态RAG方案,双线索机制,搞文本和图像embedding,然后套上Agent,讲个了不错的故事,看看具体思路。
三看SimpleDoc双线索多模态RAG方案
来看多模态RAG进展,之前的典型做法是基于视觉语言模型 (VLM) 的嵌入模型将相关页面嵌入并检索为图像,并使用可接受图像作为输入的VLM生成答案。
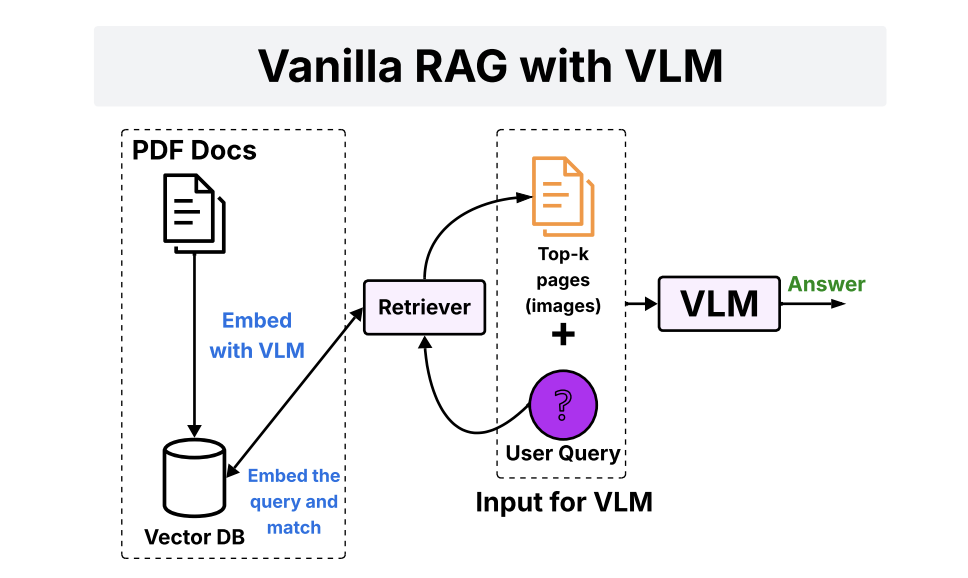
《SimpleDoc: Multi-Modal Document Understanding with Dual-Cue Page Retrieval and Iterative Refinement》(https://arxiv.org/pdf/2506.14035),代码在:https://github.com/ag2ai/SimpleDoc
1、看亮点
从方案上看,两个亮点:
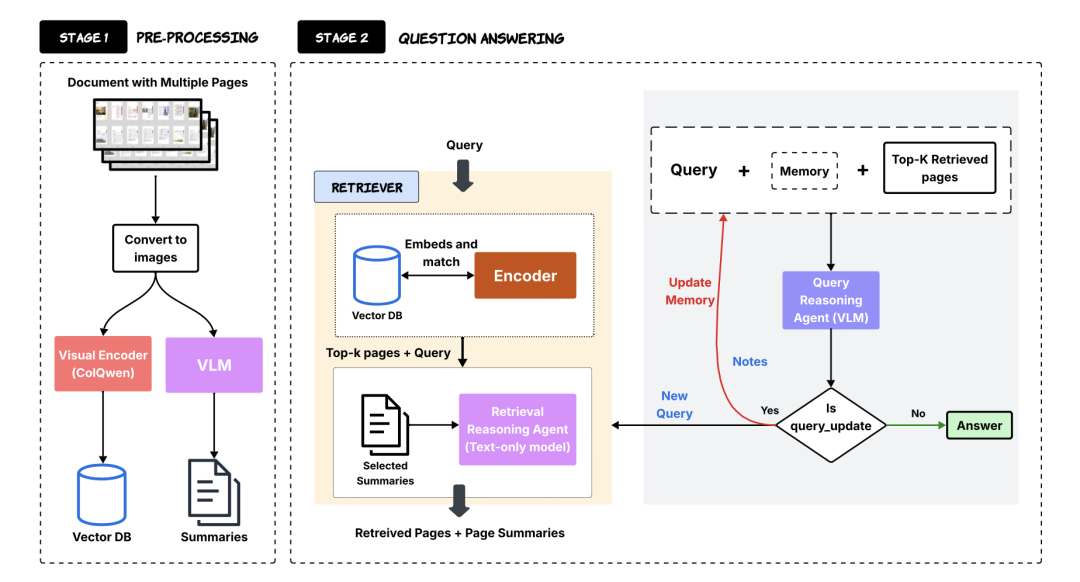
一个是双重提示检索:结合页面级视觉嵌入和 LLM 生成的摘要来检索和重新排序相关页面。
一个是迭代推理:单个基于VLM的代理动态更新查询和工作记忆以迭代地完善答案。
2、看实现细节
实现思路很简单,可以看下实现细节: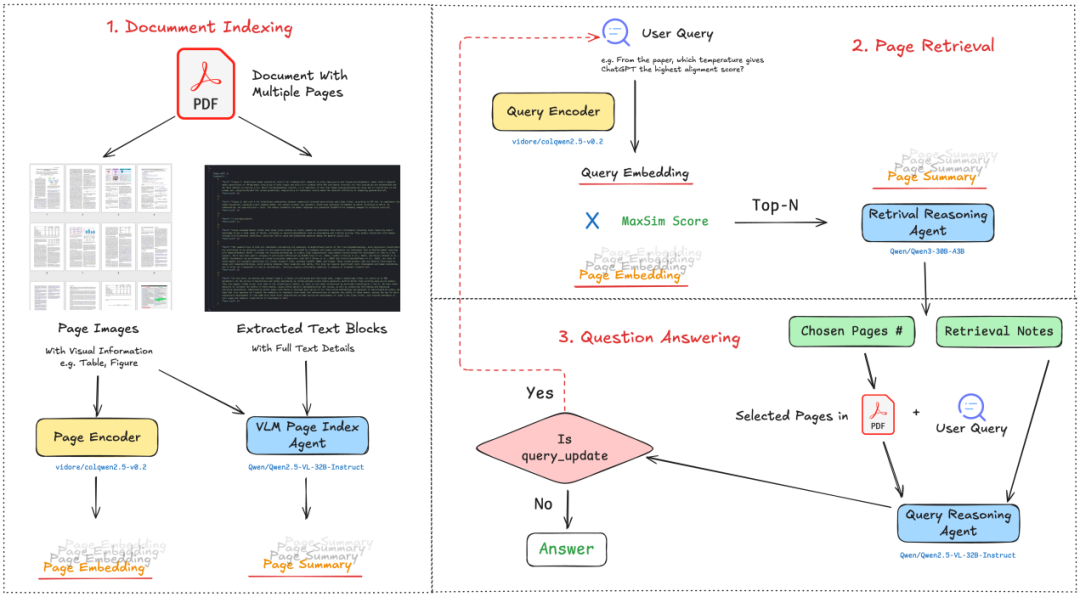
重点在标红部分,

其中摘要用了个prompt实现:

用一个具体的例子来说明具体过程,如下图:

从中可以看到,SimpleDoc如何通过迭代推理来解决一个问题。在第一轮中,代理基于嵌入和基于摘要的过滤检索了第6页、第13页和第14页。然而,检索到的页面仅描述了实验设置和评估指标,而没有给出确切的对齐分数。
代理识别出这一缺口,并生成了一个更精确的查询,专门请求一个比较不同温度下分数的部分或表格。这个更新后的查询检索到了第7页,其中包含了表3,里面有所需的信息,从而使代理能够正确回答温度0.1产生了最高的对齐分数。
3、看结果
结果上,在4个DocVQA数据集上的表现比之前的基准模型平均高出3.2%,按照它的讲法就是页面更少,准确度更高,在 DocVQA 基准测试中准确率高达70.12%,同时每个查询仅读取约3.5页。
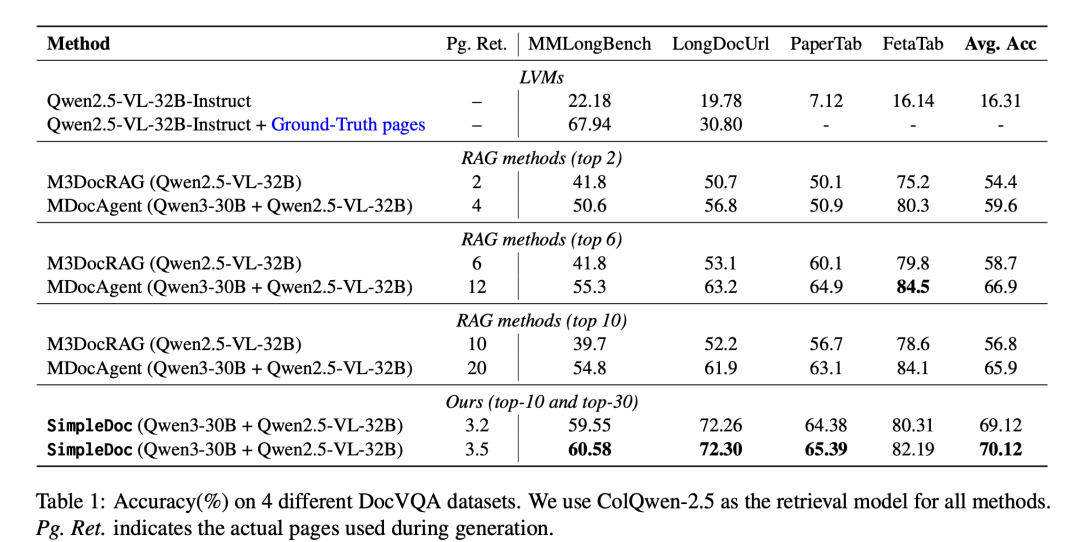
此外,方案简单但有效:在4个主要基准测试中的3个上,表现优于MDocAgent等多代理系统和 M3DocRAG等混合RAG管道。
参考文献
1、https://arxiv.org/pdf/2506.14035
(文:老刘说NLP)