
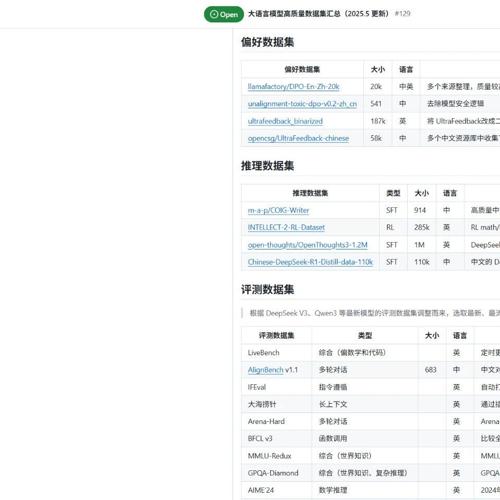
高质量数据集
AI高质量数据集交易爆发式增长

北数所表示,人工智能高质量数据集需求和交易量正在快速增长。2023年12月国家数据局等发布行动计划,要求建设高质量的人工智能大模型训练数据集。目前北数所已交付1814TB数据集,并达成171笔交易,主要服务AI头部企业用于构建行业知识底座及模型训练。


视频推理的R1时刻!港中文、清华推出首个Video-R1,7B模型竟超GPT-4o?

港中文联合清华团队发布首个将强化学习范式应用于视频推理的模型Video-R1,该模型通过引入时序建模和混合训练机制,在权威测试中击败了GPT-4o。

多模态方向开源数据集资源汇总

MINT-1T 数据集是一个 1 万亿个文本标记和 34 亿张图像的开源数据集,扩展了现有开源数据集的 10 倍。WuDaoCorpora 是一个由北京智源人工智能研究院构建的大规模、高质量数据集。Conceptual Captions 提供超过 300 万张带有自然语言字幕的配对图像。SBU Captions 数据集中有 100 万带标题的照片描述图像。MiniGPT-4 使用高质量图文对进行微调,Ego-Exo4D 包含三种精心同步的语言视频数据集。
Figure机器人进厂打工,8小时速成物流分拣大师!自研VLA模型全面升级

Figure公司通过自研VLA模型Helix,在8小时内训练完成机器人包裹分拣任务,并实现超越人类的效率和精度,展示了视觉-运动控制策略在物流场景中的巨大潜力。
