


以 DeepSeek-R1 为代表的强化学习范式,近期在语言模型领域掀起了一次“推理革命”。
而这一次,轮到视频了。
最近,港中文联合清华团队正式发布了首个将 “R1 范式”系统性落地到视频推理领域的模型——Video-R1。
不仅将强化学习算法从 GRPO 升级为更懂“时间”的 T-GRPO,还首次打通了图像+视频的混合训练路径,搭建了两个高质量数据集,真正让模型在视频中学会了“深度思考”。
更炸裂的是:在李飞飞团队提出的 VSI-Bench 这一权威视频空间推理测试中,Video-R1(仅 7B 参数)竟然干掉了GPT-4o!
目前,研究团队已经将全部代码、模型权重、数据集一并开源,视频推理的 “R1 时刻”,真的来了。

论文链接:
https://arxiv.org/abs/2503.21776
项目地址:
https://github.com/tulerfeng/Video-R1
推特知名博主 AK 也在第一时间推荐了这篇论文:

视频推理为什么这么难?
研究团队指出,在多模态大模型中,若直接使用传统 GRPO 算法做强化学习,会面临两个致命问题:
1. 没有时间感,推理全靠“猜”
原始 GRPO 不具备时间建模能力,模型很容易“走捷径”——看一帧就匆匆回答,完全忽略前后画面的因果关系。
最终学到的是一种投机式的浅层策略,泛化能力极差。下面这张图展示的就是典型的“误判式推理”。

2. 训练数据太“浅”,推理根本练不起来
目前大多数开源视频数据集,任务多以识别、分类为主,缺乏真正考验逻辑推理的内容。
这也让模型压根没机会锻炼深层次的“思考能力”。

Video-R1 怎么做的?
为了解决上述两个挑战,研究团队提出了 Video-R1,主要包含如下内容:
T-GRPO 训练算法:首先,研究团队将 GRPO 算法加入时序建模,拓展为 T-GRPO 算法。简单来说,这个算法就是要“逼”模型认真看完视频、考虑时序。
方法也不复杂:它把视频帧以乱序输入,再跟原本顺序输入做对比,只有模型在顺序那组得到正确答案的比例更大,才能得到一个设定的时序奖励。
通过这一套对比奖励机制,能够让模型在推理时明白:原来视频不是一堆图堆在一起,而是“前因后果”的线索串联。
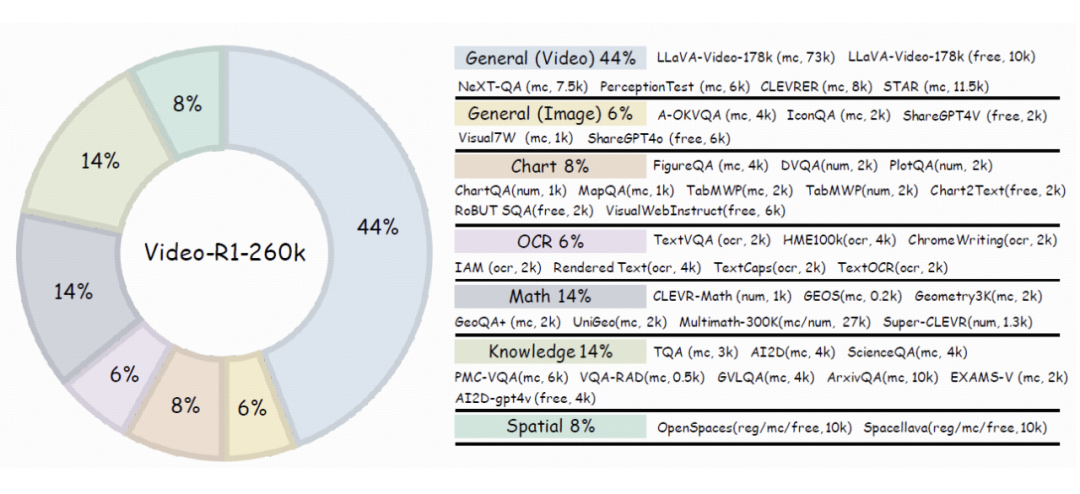
数据集精心构建:为了解决高质量的视频推理训练数据稀缺的问题,研究团队策略性地引入了高质量的图像推理数据,用于增强视频推理能力
他们精心构建了两个数据集:一个是 Video-R1-COT-165k,用来做 SFT 冷启动;另一个是 Video-R1-260k,用于强化学习训练。
图像数据在训练中并非配角,反而成了通用推理能力的重要地基;而精心筛选的视频样本,则补上了模型对时序逻辑与动态变化的理解能力。
这种“图像+视频”的混合训练机制,不只是解决了数据稀缺的问题,更关键的是——让模型学会了从静态图像中学推理、再迁移到动态视频中用推理,真正打通了多模态认知的任督二脉。

视频推理的“aha moment”
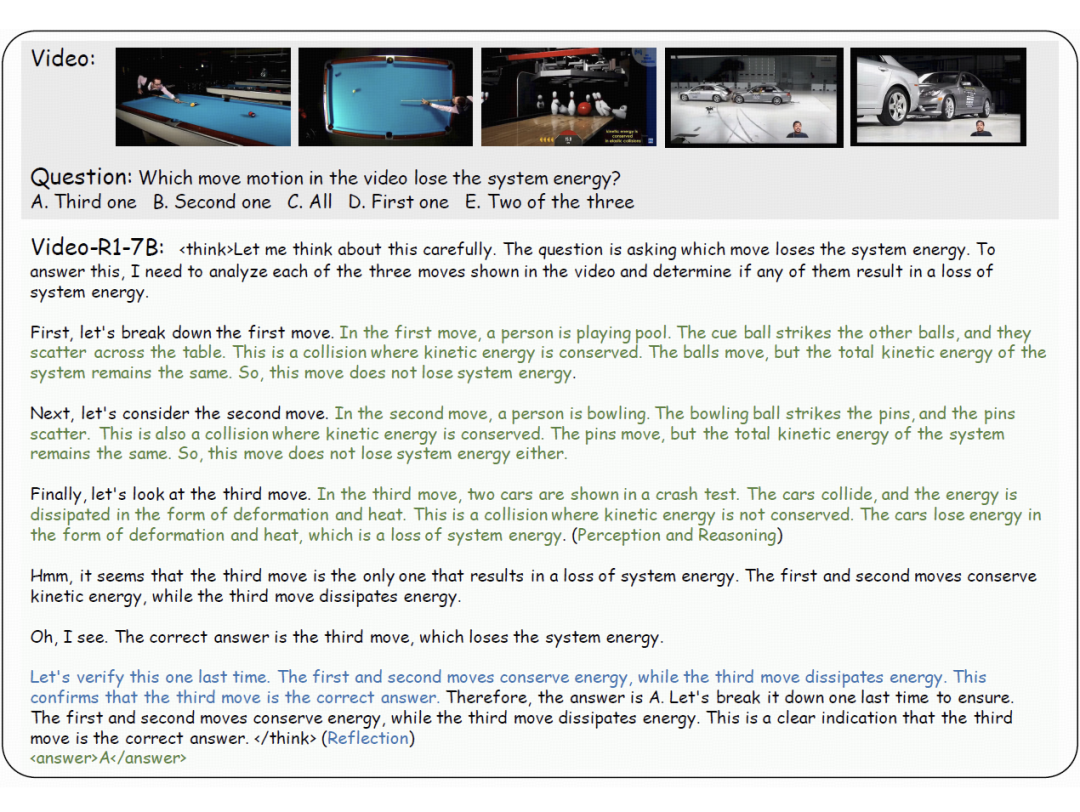
在 Video-R1 中,一个有趣的现象是,模型也出现了自我反思式的推理行为,通常被称为“顿悟时刻(aha moments)”。
例如下面两个例子,第一个询问视频中哪个动作会损失系统能,第二个则是希望根据视频游览房屋的内容,得出从书柜走到浴缸的路径。
这两个问题都不是看一眼就能答的,而是需要真正理解视频时序并进行推理,Video-R1 都做到了精准推理,逻辑闭环,成功答对。


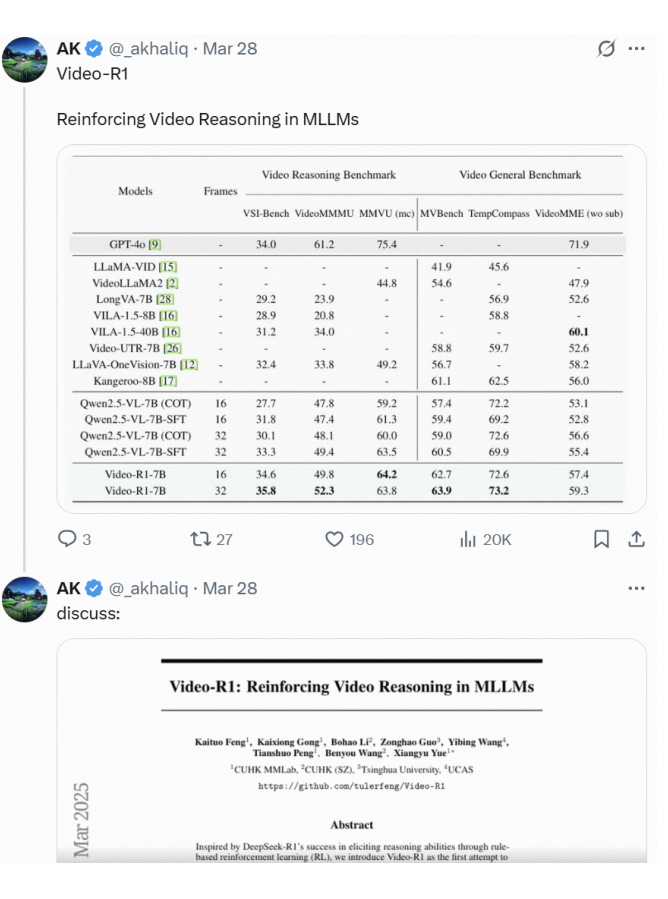
实验结果
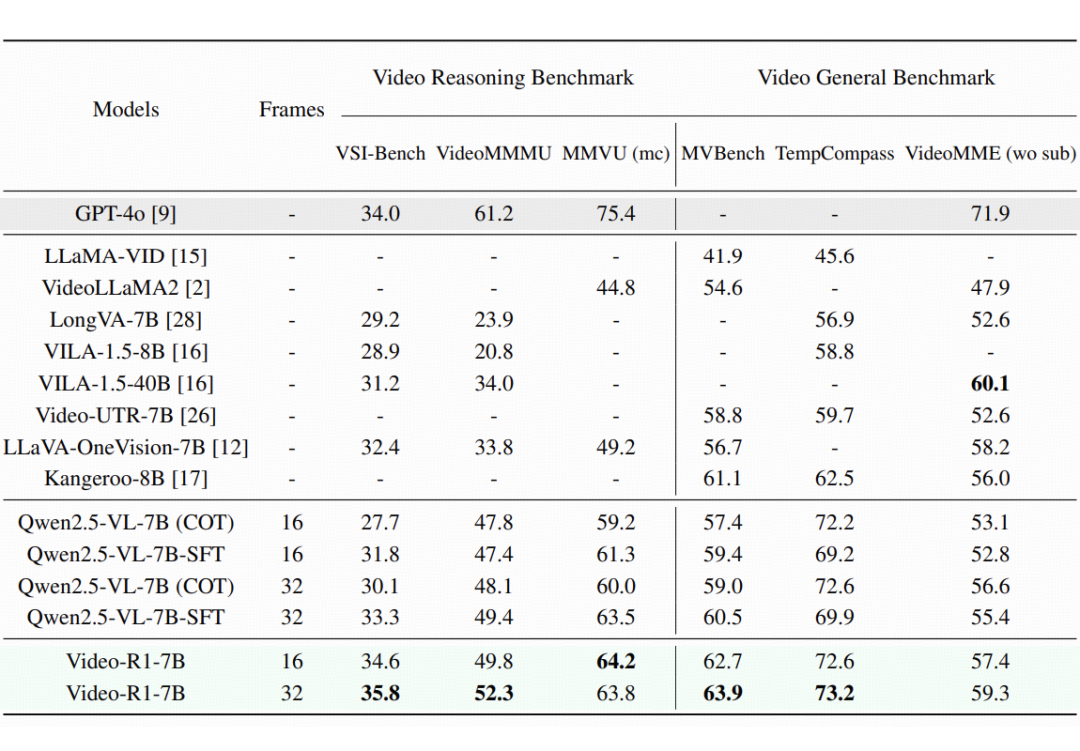
从实验结果中,可以发现:
Video-R1 的卓越性能:在大多数评测基准上,Video-R1 的表现显著优于以往模型,尤其是在等视频推理的 benchmark上。值得注意的是,在 VSI-Bench 这一专注于视频空间推理的评测中,Video-R1-7B 达到了 35.8% 的最新准确率,超越了闭源模型 GPT-4o。
RL 相对于 SFT 的优越性:SFT 模型 Qwen2.5-VL-7B-SFT 在多个评测中未能持续带来性能提升,可能是由于过拟合或在未知场景下泛化能力有限。而 Video-R1 在所有评测中都实现了显著提升,特别是在推理任务中效果尤为明显。这表明了强化学习强大的泛化能力。
更多帧带来更强推理:当输入帧数从 16 增加到 32 时,几乎所有评测任务的表现都有所提升。这表明更长的上下文和更丰富的时序信息对模型推理能力具有积极影响。开发能够推理更长视频内容的模型,是未来研究中一个有前景且必要的方向。
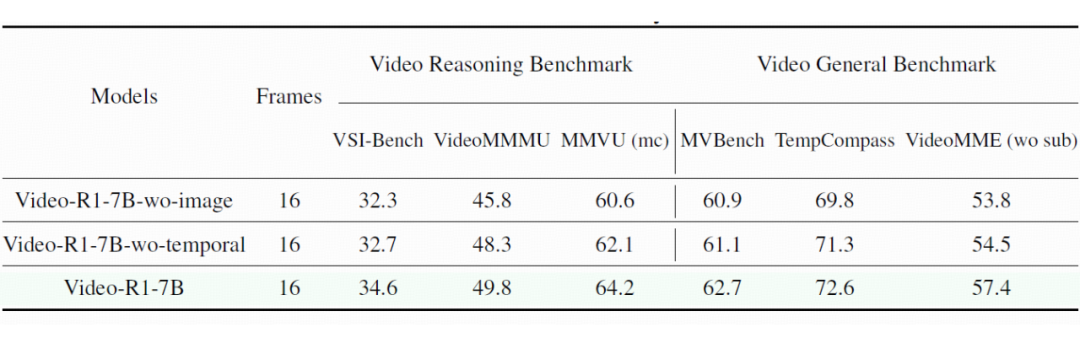
在消融实验中,也可以看到,去除了图像训练数据或是去除了时序建模后,模型的表现都下降了,这说明了提出的方法的有效性。
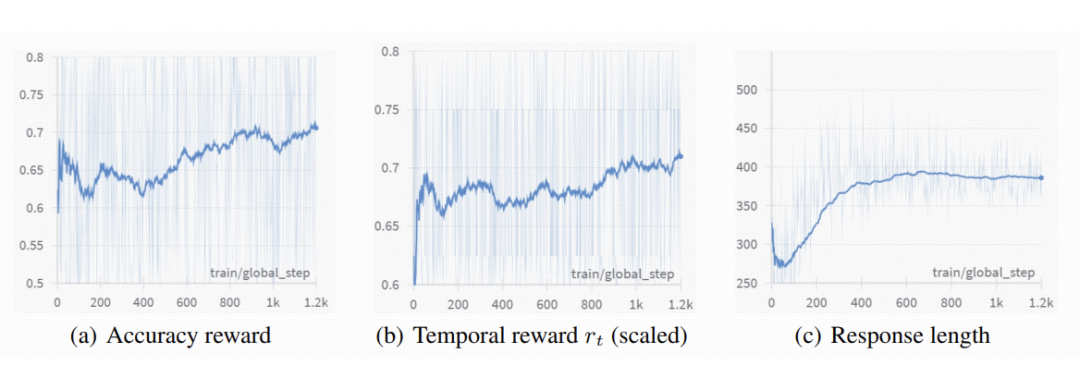
上图展示了 Video-R1 在强化学习过程中的训练动态。
准确率奖励和时序奖励整体呈上升趋势,表明模型在强化学习过程中不断提升其生成正确答案的能力,并且在训练中也逐步采用了更多基于时间的推理策略。
而对于输出长度,在强化学习训练初期,模型的输出长度先是下降,随后逐步上升,最终稳定在一个固定范围内。这可能是由于训练初期模型会先抛弃 SFT 中学习到的次优推理策略,再逐步收敛到一种更优的推理模式。

写在最后
Video-R1 证明了:强化学习不只是语言模型的专属,在视频领域同样能激发模型的深度推理潜力。
更关键的是,它是全开源的。
视频 AI 的“推理纪元”,正在从这一刻开启。
更多细节,请参考论文原文。
(文:PaperWeekly)