

今天是2025年7月16日,星期三,北京,晴。
今天我们继续来看多模态数据合成,尤其是领域多模态数据合成的一些思路,看多模态医学大模型的一个例子,体会其实现策略。
另外,看看具身智能领域的代表性空间理解大模型,这个也很有趣,看看两个代表工作,如何应用大模型去理解这些场景,RoboBrain 2.0 以及SpatialLM。
一、从医疗多模态大模型灵枢看其数据合成思路
多模态医学大模型灵枢《Lingshu: A Generalist Foundation Model for UnifiedMultimodal Medical Understanding and Reasoning》,提供灵枢-7B、灵枢-32B两个开源版本,功能包括X光、CT扫描、MRI、显微镜、超声、组织病理学、皮肤镜检查、眼底检查OCT、数字摄影、内窥镜检查和PE功能。
相应的细节在:https://huggingface.co/collections/lingshu-medical-mllm/lingshu-mllms-6847974ca5b5df750f017dad,https://alibaba-damo-academy.github.io/lingshu/,https://arxiv.org/pdf/2506.07044,https://superrobobrain.github.io/核心还是看训练数据清洗思路跟训练步骤。
1、数据合成策略
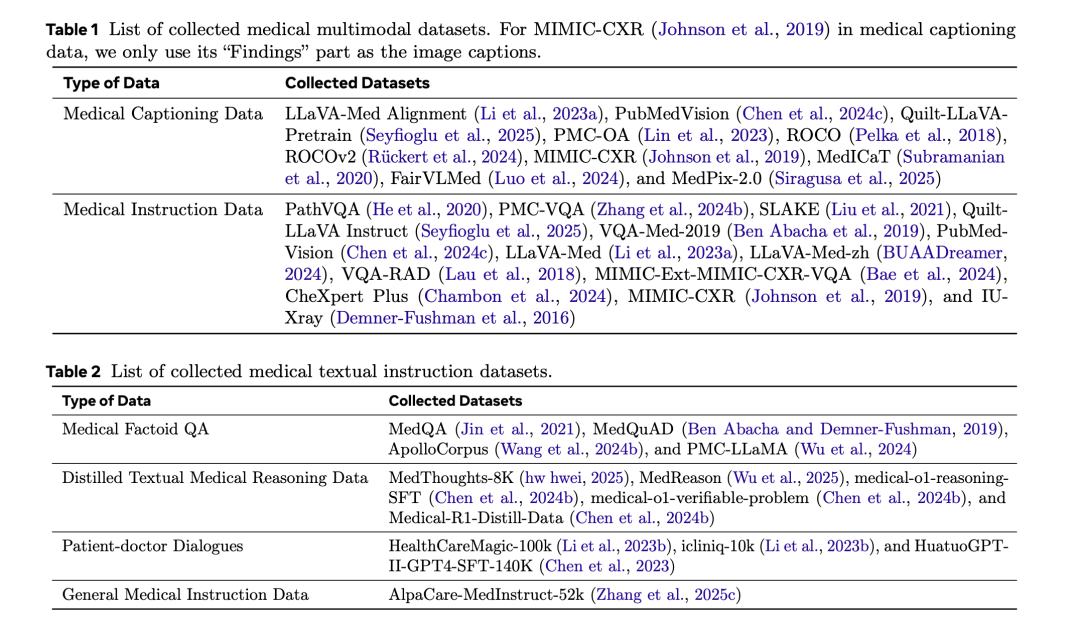
1、数据收集,这块比较全,如下:
2、数据清洗
许多开源的多模态医学数据集是从科学论文中自动提取的,因此通常包含噪声和冗余。
为了确保数据质量,实施了一个三阶段的清洗流程。
首先,进行图像过滤,移除尺寸小于64像素的图像,以消除低分辨率或无信息内容。
其次,进行图像去重,采用感知哈希算法,并设置严格的汉明距离阈值为零,以检测并移除完全重复的图像,每组只保留一个高质量的实例。
为了加速该过程,采用了基于块的去重技术。第三,进行文本过滤,其中图像标题样本少于10个。
3、数据合成
当前,数据合成方法无处不在,因此,可以重点看看。
这个工作合成四种类型的医学多模态数据,包括长格式标题、基于OCR的指令样本、视觉问答实例以及推理数据。
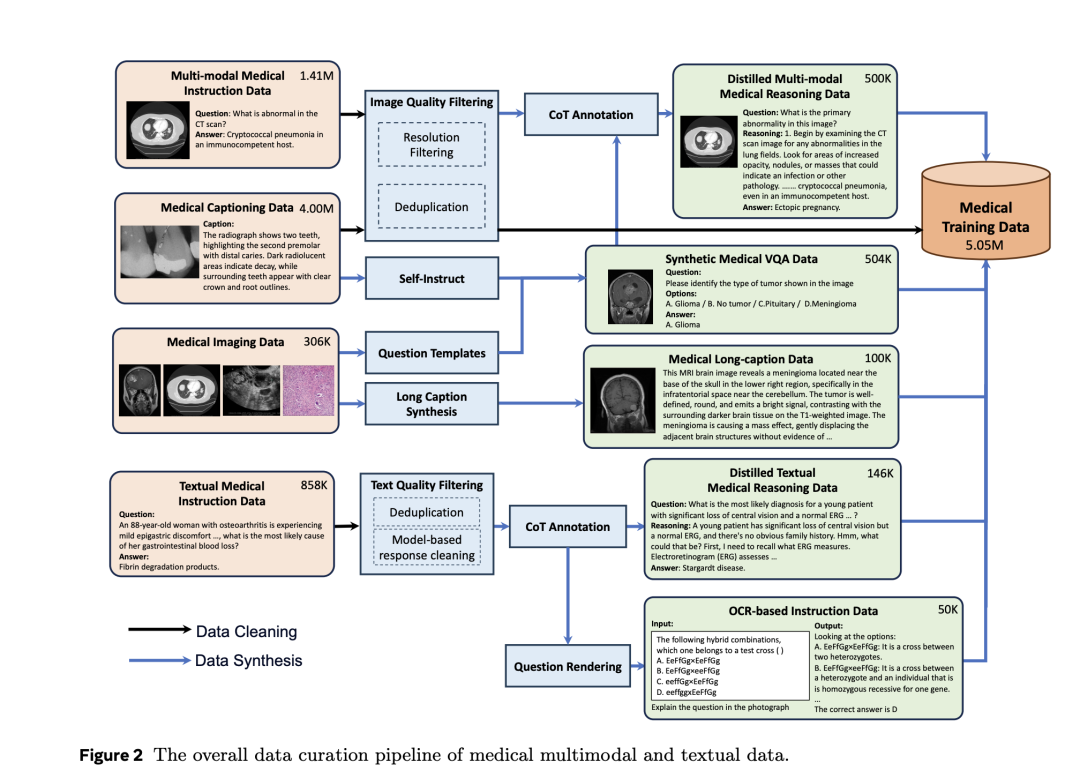
1)医学长格式标题合成
首先,元数据准备。该阶段利用元数据为给定图像提供必要的上下文信息,包括成像方式、疾病类型,并在适用的情况下,包括相机视角和可观察到的患者特征,
其次,区域(RoI)识别。在第一阶段获得的文本数据的基础上,这一阶段结合了补充的视觉信息。对于图像分割数据集,通过RoI提供疾病或异常的定位,这对于减少幻觉至关重要,必须在图像中清晰标记。对于像MAMA-MIA和KIPA22这样的3D数据集,沿z轴提取2D切片及其对应的掩码,并应用相同的边界框渲染程序生成2D图像。
接着,使用事实知识进行标注。这一阶段侧重于通过整合前两个阶段的文本和视觉信息来合成图像描述。对于带有注释区域(RoI)的数据集,将边界框渲染的图像、简短标题和检索到的医学知识输入到GPT-4o中以生成描述性文本。
最后,根据医生的偏好进行标注。
2)医学视觉问答数据合成
医学视觉问答数据合成,提取包含与解剖结构、异常或成像模态相关的标签的数据集,对于每种标签类型,手动设计问题模板进行合成。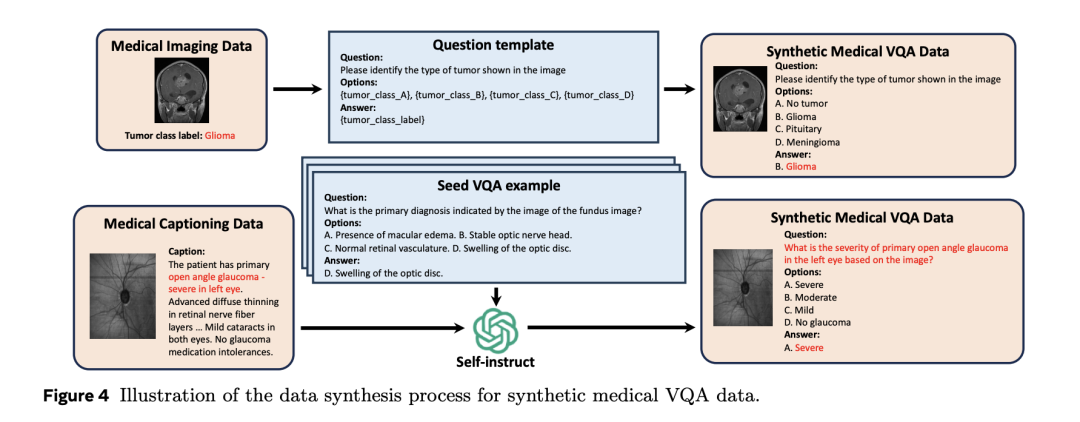
为了增强问题的多样性和语言变化,利用GPT-4o从医学字幕数据集中获取的(图片,标题)对生成VQA样本。使用少样本格式提示GPT-4o,其中种子示例取自开源医学VQA。
3)医学推理数据合成
大多数现有的开源和合成的医学指令数据主要由简答题和多选题组成,缺乏对其底层推理过程的明确注释,为了加强模型的医学推理能力,利用GPT-4o为部分多模态和文本指令数据生成CoT推理轨迹。
具体的,对于每个样本,向GPT-4o提供问题、正确答案,以及适用情况下的答案选项和相应的医学图像。GPT-4o被提示生成一个不依赖或不明显引用正确答案的逐步推理路径,为确保质量,实施了一个验证过程,GPT-4o在此过程中评估推理轨迹与正确答案之间的一致性,被认为不一致的样本将从最终数据集中排除。
4)总结数据合成
使用GPT-4o结合第3阶段和第4阶段的输出,进行总结。
2、模型训练策略
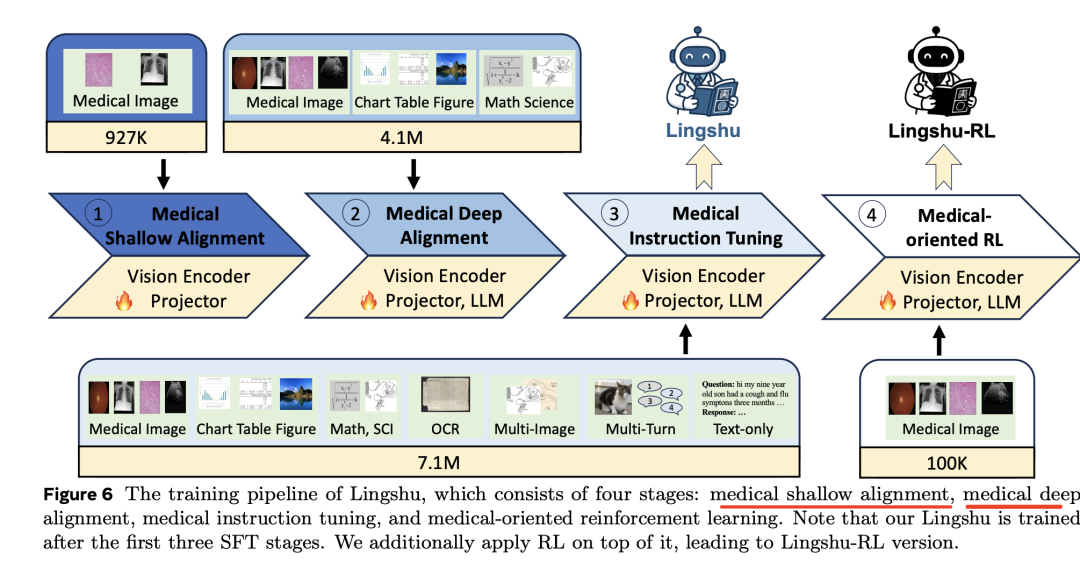
在Qwen2.5-VL基础之上使用了医疗浅层对齐、医疗深层对齐、医疗指令调优和医疗导向四阶段强化训练。
其中:
医学浅层对齐:冻结LLM,仅微调视觉编码器和投影层,使用PMC-OA和ROCO数据;
医学深层对齐:解冻所有模型参数,使用更丰富、更高质量的医学图像-文本对数据进行端到端微调,包括医学图像字幕、ROCOV2、LLaVA-Med等数据;
医学指令微调:解锁所有参数,进行大规模端到端优化,使用PathVQA、PMC-VQA、SLAKE等数据;
医学导向的强化学习:采用Group Relative Policy Optimization (GRPO) 方法,使用MIMIC-Ext-MIMIC-CXR-VQA、PMC-VQA等数据进行训练。
其中,每一步对应的数据集情况如下:
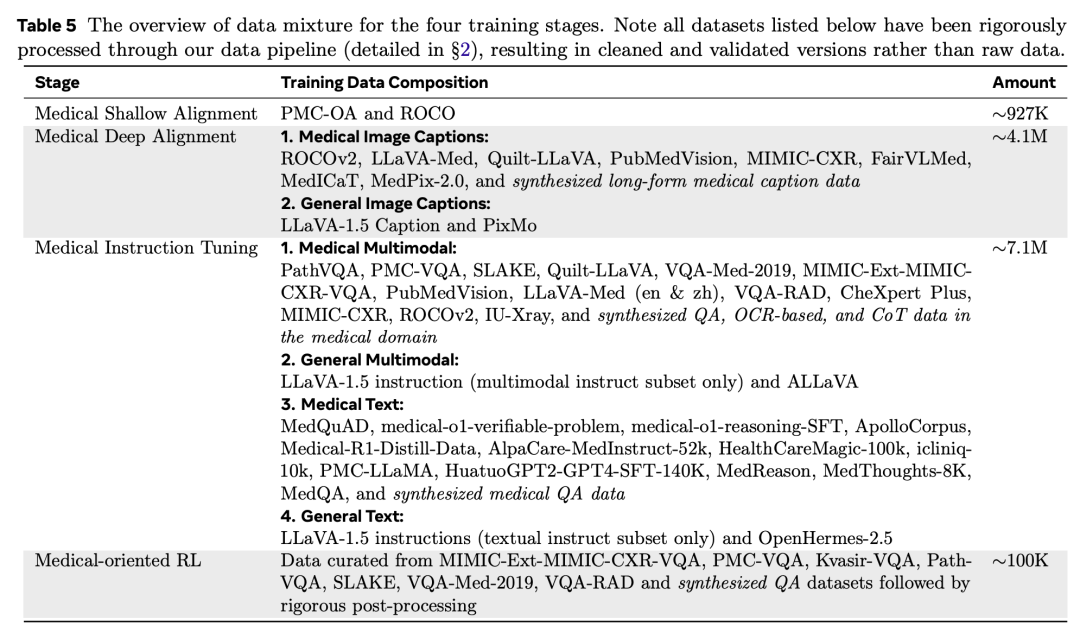
对了,其还提供了一个医疗领域的评估工具MedEvalKit,https://github.com/alibaba-damo-academy/MedEvalKit
二、具身智能领域的代表性空间理解大模型
空间理解也是跟具身智能结合比较紧密的一个方向,来看两个工作,结合比较紧密。
一个是SpatialLM《SpatialLM: Training Large Language Models for Structured Indoor Modeling》,这个很像3D目标检测,空间大模型:https://github.com/manycore-research/SpatialLM,https://arxiv.org/pdf/2506.07491,https://manycore-research.github.io/SpatialLM/,基于Qwen2.5-0.5B作为基础模型。
在模型功能上,处理3D点云数据并生成结构化的 3D 场景理解输出,包括建筑元素,例如墙壁、门、窗以及带有语义类别的定向物体边界框。
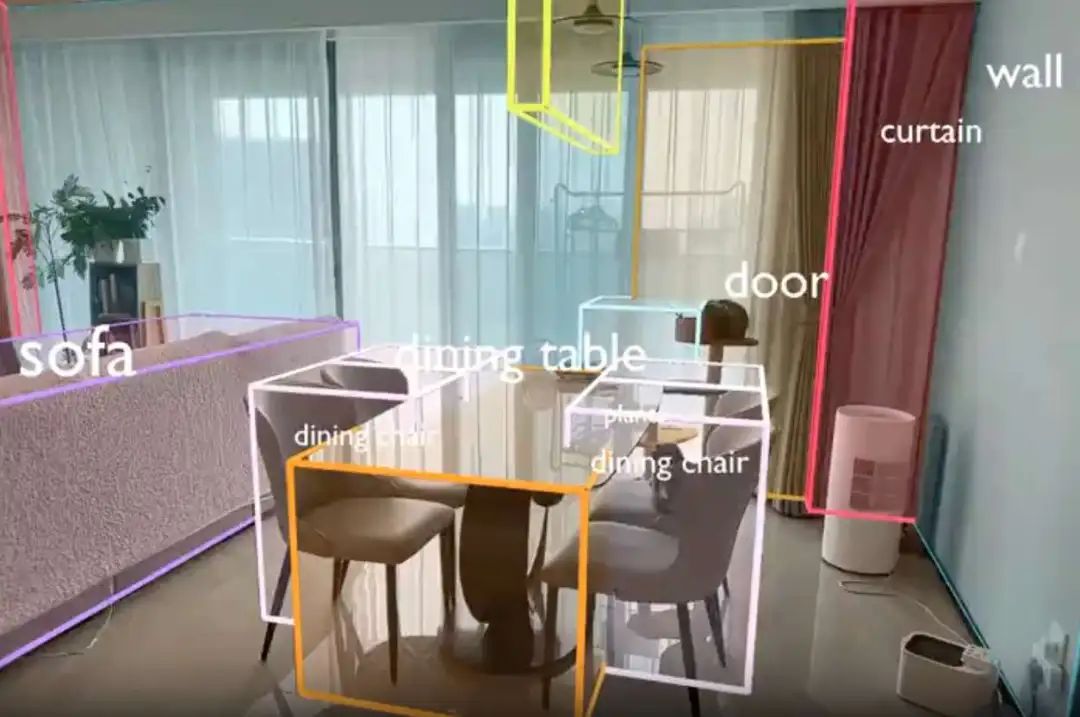
在模型架构上,通过在合成数据集上进行微调,使用MASt3R-SLAM重建3D点云。然后, SpatialLM将这些密集的点云转换为结构化表示。点云编码器将点云编码为紧凑的特征,LLM 生成描述场景的场景代码,这些代码可以转换为 3D 结构化布局。

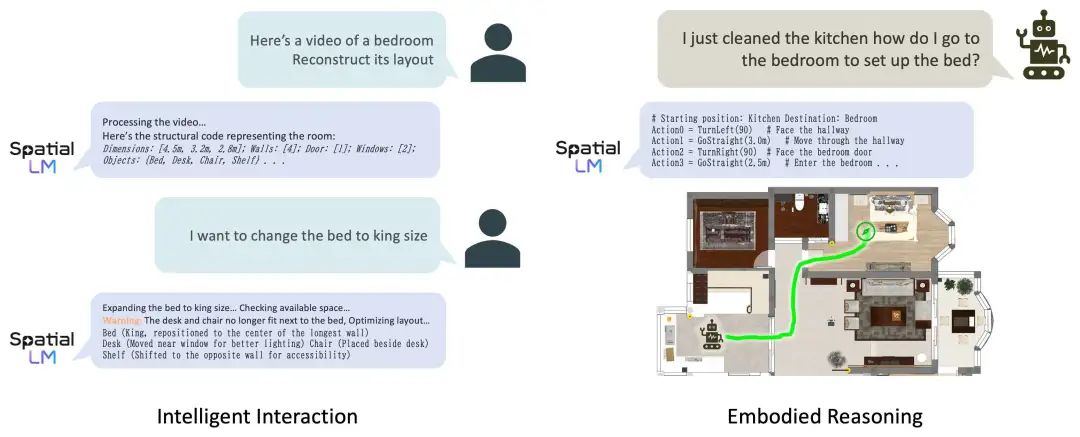
另一个是RoboBrain 2.0 32B,《RoboBrain 2.0 Technical Report》https://arxiv.org/abs/2507.02029,https://superrobobrain.github.io,GitHub:https://github.com/FlagOpen/RoboBrain2.0,也是用于做空间理解。
在功能上看,支持具有长远规划和闭环反馈的 交互式推理、从复杂指令中进行精确点和边界框预测的 空间感知、用于未来轨迹估计的时间感知以及通过实时结构化内存构建和更新进行 场景推理。
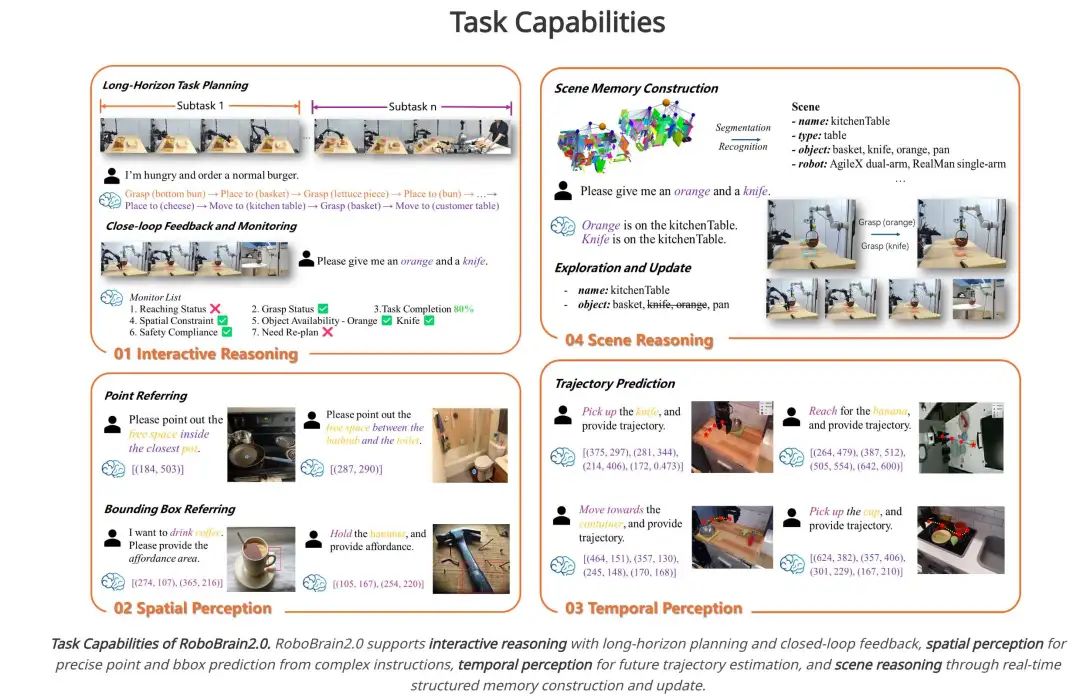
从训练架构上看,模型支持多图像、长视频和高分辨率视觉输入,并在语言方面支持复杂的任务指令和结构化场景图。
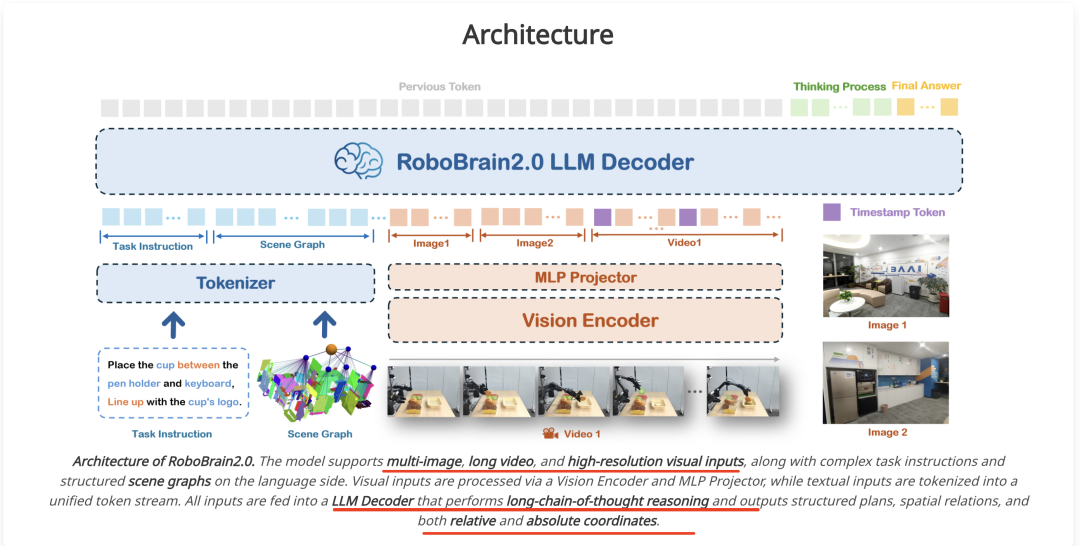
视觉输入通**过视觉编码器 (Vision Encoder) 和多层感知器 (MLP) 投影器 (Projector) 进行处理,而文本输入则被标记化为统一的标记流。所有输入都被输入到LLM 解码器 (Decoder)**,该解码器执行长链思维推理,并输出结构化规划、空间关系以及相对和绝对坐标。
对应的模型权重在:https://huggingface.co/BAAI/RoboBrain2.0-7B,Checkpoint-32B:,https://huggingface.co/BAAI/RoboBrain2.0-32B
参考文献
1、https://arxiv.org/pdf/2506.07044
2、https://github.com/manycore-research/SpatialLM
3、https://arxiv.org/abs/2507.02029
(文:老刘说NLP)