

本位作者分别来自南京大学,罗格斯大学和马萨诸塞大学阿默斯特分校。第一作者韩廷旭与共同第一作者王震霆是分别来自南京大学和罗格斯大学的博士生,研究方向聚焦于大模型推理以及安全负责任的生成式人工智能。通讯作者为南京大学房春荣教授。
随着大型语言模型(LLM)技术的不断发展,Chain-of-Thought(CoT) 等推理增强方法被提出,以期提升模型在数学题解、逻辑问答等复杂任务中的表现,并通过引导模型逐步思考,有效提高了模型准确率。
然而,这类方法也带来了新的挑战:模型生成的中间推理过程往往冗长,产生了大量冗余 Token,这显著增加了推理阶段的计算成本和资源消耗。在 LLM 日益走向实际部署的背景下,如何在保证推理能力的同时控制成本,已成为制约其大规模应用的核心问题。
为解决这一矛盾,近日来自南京大学、罗格斯大学和马萨诸塞大学阿默斯特分校的研究团队提出了一种基于 Token 预算感知 的 LLM 推理新框架 TALE,旨在保证推理准确率的同时,显著压缩输出长度、降低计算开销。
TALE 的核心理念是在推理过程中引入「Token 预算」这一约束机制,引导模型在限定的 Token 预算范围内完成有效推理。这种机制不仅可以提升模型对资源约束的适应性,也能促使其生成更加简洁、高效的推理路径。
该成果近日被自然语言处理顶级会议 ACL 2025 正式接收为 Findings。

-
论文标题:Token-Budget-Aware LLM Reasoning -
论文地址:https://arxiv.org/pdf/2412.18547 -
GitHub:https://github.com/GeniusHTX/TALE
背景与动机:CoT Token 冗余与 Token 弹性现象

图 1:关于 Token 预算的直观示例。
以 CoT 为代表的推理增强技术,已被广泛集成至 GPT-4o、Yi 系列等主流模型中。但研究者发现,模型生成的中间推理过程往往冗长重复,输出 Token 数量成倍增长,带来了显著的计算与经济成本。
特别是在资源受限的边缘端推理任务部署场景(如教育答题、金融问询、代码理解)中,如何在「准确率」与「资源效率」之间取得平衡,成为当前急需解决的关键问题。该工作的研究者通过引入显式的 Token 预算信息,引导或训练模型在满足任务正确性的同时压缩推理过程,实现推理效率与性能之间的最优折中。
研究者首先通过不断降低问题的 Token 预算来探究模型思维链压缩的极限,并在系统性实验中观察到一个普遍存在的现象——Token Elasticity(Token 弹性)。即:当提示中施加过小的 Token 预算约束时,模型不仅难以遵守预算,反而可能耗费更多的 Token,导致总成本进一步上升。
这种「压缩失败反弹」的现象表明,当前 LLM 的推理行为在预算限制下存在一定的不稳定性和非线性响应,提示我们不能简单地通过减小预算来压缩推理,而是需要设计一套机制,引导模型在合理预算范围内产生最优推理路径。
为了实现这一目标,研究者提出了 TALE(Token-Budget-Aware LLM Reasoning) 框架,以实现推理质量与生成效率的协同优化。研究者给出了两种不同的具体实现方式:基于预算估计与提示工程的 TALE-EP(Estimation and Prompting) 以及基于后训练内化 Token 预算感知的 TALE-PT(Post-Training)。

图 2:关于 Token 弹性现象的直观示例。
基于预算估计与提示工程的 TALE-EP(Estimation and Prompting)
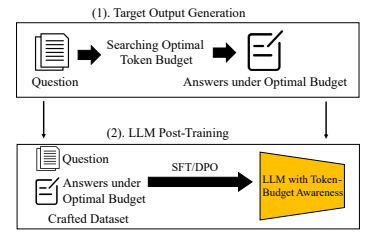
图 3:TALE-EP 的框架图。
TALE-EP 是一种轻量级、即插即用的基于零样本提示的推理增强方法。TALE-EP 首先让模型自我估计对每个具体问题所需的合理 Token 预算,并在推理过程中将该预算信息融入输入提示中,引导模型在不超过预算的前提下生成推理过程。这种方法无需修改模型参数,仅通过提示工程即可实现对 Token 生成的动态控制,兼具灵活性与实用性。实验结果显示,TALE-EP 在多个数学推理数据集上显著降低了 Token 使用量,平均节省超过 60% 的推理开销,且保持了与传统 CoT 方法相当甚至更优的准确率。

图 4:TALE-EP 的实验性能展示。
基于后训练内化 Token 预算感知的 TALE-PT(Post-Training)
图 5:TALE-PT 的框架图
TALE-PT 则通过监督微调(SFT)或偏好优化(DPO)的训练方式将 Token 预算感知内化为模型本身的推理能力。TALE-PT 首先通过搜索算法为每个问题寻找最优 Token 预算,并使用该预算生成精炼的推理路径作为「目标输出」,引导其在未来推理中主动生成更符合预算约束的输出。
实验结果显示,无论是采用 SFT 还是 DPO 方法进行后训练,TALE-PT 均可在维持推理准确率的同时,将平均推理所需的 Token 数量降低 40% 以上,显著优于原始的思维链推理方式。
图 6:TALE-PT 的实验性能展示。
结语
本研究围绕大型语言模型推理过程中的 Token 冗余问题,提出了具有前瞻性的解决方案——TALE 框架,通过引入「Token 预算感知」机制,实现了推理准确性与生成效率之间的有效平衡。值得一提的是,本文所提出的 Token 预算思想已开始在行业中获得响应,包括 Qwen3 和 Claude 3.7 等最新发布的大模型也引入了类似的预算控制机制(图 7 和 图 8 所示),用于优化推理效率与输出质量。

图 7:截取自 Qwen3 技术报告。

图 8:截取自 Claude Developer Guide。
实验结果表明,TALE 在多个主流数据集和模型上均表现出显著的压缩效果和良好的兼容性,进一步拓展了大型语言模型在资源受限场景下的应用边界。未来,该框架有望推广至更多任务类型和多模态场景中,推动大型模型推理走向更加可控、高效与可落地。

©
(文:机器之心)