AI狂飙前夜,WAIC 2025全球开票!早鸟限时,会员专享超级礼遇!

2025年7月26日至28日,世界人工智能大会(WAIC)将在上海召开。会议将涵盖高端对话、四大展馆展览、创新生态共振和智能场景联动等内容,吸引全球顶尖思想与企业参展,展现AI前沿技术及应用蓝图。
2025年7月26日至28日,世界人工智能大会(WAIC)将在上海召开。会议将涵盖高端对话、四大展馆展览、创新生态共振和智能场景联动等内容,吸引全球顶尖思想与企业参展,展现AI前沿技术及应用蓝图。

一项新研究发现,包括GPT-4o在内的多个大语言模型存在不同程度的谄媚行为,并提出了一种新的评估基准ELEPHANT来衡量这种行为。

VGGT 是一种基于纯前馈 Transformer 架构的通用 3D 视觉模型,能在单张或多张图像中直接预测相机参数、深度图和点云等几何信息。其推理速度可达秒级,并在多个任务中超越传统方法。

计算机视觉与模式识别会议CVPR将于2025年召开,首届计算机视觉推理扩展研讨会(ViSCALE)将探讨Test-time Scaling在计算机视觉中的应用与发展潜力。
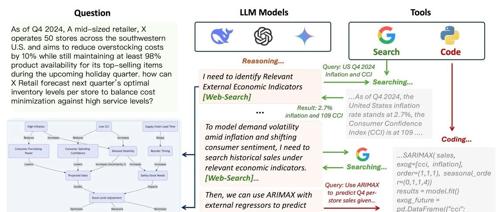
牛津大学提出Agentic Reasoning框架通过整合外部代理增强LLM推理能力,在复杂研究任务中超越现有模型,显著提高准确性和生产力。

牛津大学的本·格林和哥伦比亚大学的梅塔布·索尼解决了素数分布问题的新进展,通过引入粗略素数的概念并利用Gowers范数技术证明了存在无限多个符合特定条件的素数。
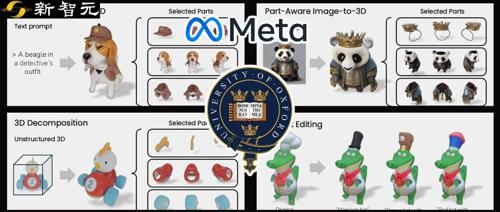
Meta与牛津大学研究人员发布PartGen,能够生成子结构可分离的高质量3D模型,解决现有AI生成3D对象缺乏零部件信息的问题。

赵宇飞、Mehtaab Sawhney与Ben Green合作证明了高斯素数猜想,使用Gowers范数分析x, y组合分布的均匀性,最终得出目标公式。两人因研究Gowers范数而结缘,格林和索尼的合作始于20年前的共同成果。
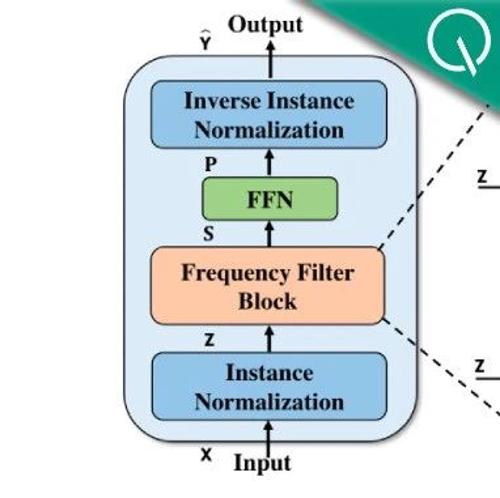
研究团队提出FilterNet模型,通过频率滤波器简化时间序列预测架构。该方法已在八个基准数据集上展示出卓越的性能,并且在效率方面表现出色。