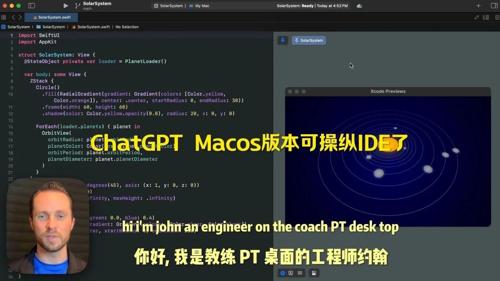
刚刚,Gemini 2.5系列模型更新,最新轻量版Flash-Lite竟能实时编写操作系统

Google发布了Gemini 2.5系列的新版本,包括稳定版和预览版。其中Gemini 2.5 Flash-Lite是性价比最高的模型之一,适用于需要快速处理大量任务的应用场景。
Google发布了Gemini 2.5系列的新版本,包括稳定版和预览版。其中Gemini 2.5 Flash-Lite是性价比最高的模型之一,适用于需要快速处理大量任务的应用场景。

第五届中国情感计算大会(CCAC 2025)将于7月18-20日在四川成都举办,聚焦情感计算与人工智能等领域的交叉融合。会议包含特邀报告、青年科学家论坛、企业论坛等多个环节,并提供多种注册方式和费用。
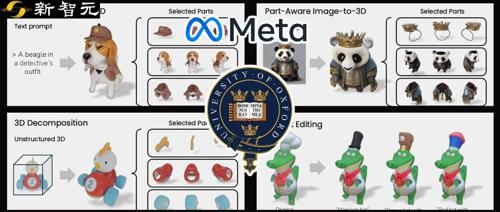
Meta与牛津大学研究人员发布PartGen,能够生成子结构可分离的高质量3D模型,解决现有AI生成3D对象缺乏零部件信息的问题。
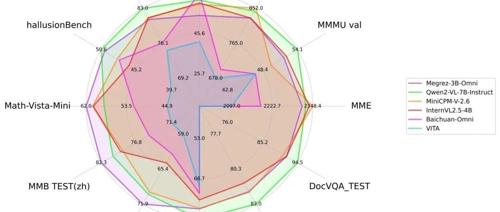
Megrez-3B-Omni是无问芯穹研发的端侧全模态理解模型,基于Megrez-3B-Instruct扩展,在图像、语音和文本领域均取得最优精度。